OpenMP笔记。由于曾经学习过,这一遍就简单过一下。
学习内容来自:
https://lemon-412.github.io/imgs/20200516OpenMP_simple_Program.pdf
https://hpc-wiki.info/hpc/OpenMP
https://www.easyhpc.net/course/10/lesson/107/material/128
常看手册:https://www.openmp.org/wp-content/uploads/openmp-examples-4.5.0.pdf
主要的内容来自第一个文档,第三个文档有一些数据相关的条件下寻找并行性的例子,没有做笔记但是值得看一下。
OpenMP是一组编译制导语句和库函数,用来表达程序中的并行性。
OpenMP面向共享存储体系结构,特别是SMP系统,
一.OpenMP的使用 OpenMP在IDE中配置属性中通常有选择项可开启,如果直接编译,只需要在编译时添加-fopenmp 。
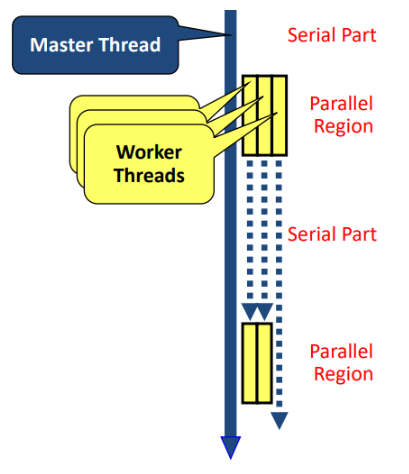
1.并行执行模式 OpenMP采用fork/join模式,开始时只有一个主线程,串行部分都由主线程执行,并行部分产生其他线程来执行。
2.制导指令 在C/C++中,OpenMP的格式均为:
其中指令有以下一些:
parallel
for
parallel for
sections
parallel sections
critical
single
barrier
atomic
master
ordered
threadprivate
子句有:
private:线程私有变量
firstprivate:线程有变量私有副本,并且要继承主线程中的初值
lastprivate:将私有变量的值并行处理结束后复制回主线程的变量
reduce:一个或多个变量私有,最后要执行特定操作
nowait:忽略默认的等待
num_threads:指定线程的个数
schedule:指定如何调度
shared:指定共享变量
ordered:指定循环顺序执行
copyprivate:single的指定变量变为多个线程共享
copyin:指定threadprivate的变量的值用主线程的值初始化
而库函数包括:
omp_get_num_procs
omp_get_num_threads
omp_get_thread_num
omp_set_num_threads
omp_init_lock
omp_set_lock
omp_unset_lock
omp_destroy_lock
3.并行子句的使用 parallel
parallel子句可构造一个并行块:
1 2 3 4 #pragma omp parallel num_threads(8) { std::cout<<"parallel\n" ; }
相当于重复调用创建线程完成并行块中的内容。
for
要与parallel结合使用:
1 2 3 4 #prama omp parallel for for (i=0 ;i<4 ;i++){ std::cout<< "i=" <<i<< " Threadid=" <<omp_get_thread_num (); }
for语句中的三个子句必须符合规范,第一个是赋值,第二个是与边界值比较,第三个是i++,i—等。
sections
sections将块中代码划分为不同section,然后并行执行:
1 2 3 4 5 6 7 8 9 10 #pragma omp parallel sections { #pragma omp section printf (“section 1 ThreadId = %d\n”, omp_get_thread_num ()); #pragma omp section printf (“section 2 ThreadId = %d\n”, omp_get_thread_num ()); #pragma omp section printf (“section 3 ThreadId = %d\n”, omp_get_thread_num ()); #pragma omp section printf (“section 4 ThreadId = %d\n”, omp_get_thread_num ()); }
使用sections划分要保证各个section中的代码执行时间相差不大,才能保证并行执行的效果。
barrier
barrier是同步指令,插入barrier后,所有线程都到达barrier后才会向后继续执行。
例如以下程序,没有barrier就可能会有线程提前访问sum,输出不稳定的值:
1 2 3 4 #pragma omp parallel cal_sum ();#pragma omp barrier printf ("i=%d, thread_id=%d\n" , sum,omp_get_thread_num ());
一些指令是会隐式同步的,如for,single,parallel,可以使用nowait子句来消除隐式同步。
4.数据处理子句的使用 private
private子句用于将一个或多个变量声明成线程私有变量,指定每个线程都有私有副本。(同名共享变量将在并行区不起作用):
1 2 3 4 5 6 int k = 100 ;#pragma omp parallel for private(k) for ( k=0 ; k < 10 ; k++){ printf ("k=%d\n" , k); } printf ("last k=%d\n" , k);
最终输出的k是100,而并行区域中的k也不会继承共享变量k的值。
firstprivate
如果需要私有变量继承共享变量的值,可以使用firstprivate子句:
1 2 3 4 5 6 7 int k = 100 ;#pragma omp parallel for firstprivate(k) for ( i=0 ; i < 4 ; i++){ k+=i; printf ("k=%d\n" ,k); } printf ("last k=%d\n" , k);
最终会输出k=100(101,102,103) last k = 100。即私有的k继承了共享的k值,但不会修改共享的k。
lastprivate
如果要在退出并行区域时将最终的私有变量取值赋值给对应共享变量,可使用lastprivate子句:
1 2 3 4 5 6 7 int k = 100 ;#pragma omp parallel for firstprivate(k),lastprivate(k) for ( i=0 ; i < 4 ; i++){ k+=i; printf ("k=%d\n" ,k); } printf ("last k=%d\n" , k);
最后last k = 103。如果是循环迭代,则是最后一次循环的值,如果是sections,则是最后一个section中的值。
threadprivate
该子句指定各个线程都复制一个全局变量的私有拷贝:
1 2 3 4 5 6 int counter = 0 ;#pragma omp threadprivate(counter) int increment_counter () counter++; return (counter); }
shared
shared子句用来声明变量为共享变量。如果要写变量,需要注意对其进行保护。
default
default(shared|none)可指定默认情况下,变量是否被视为共享变量。如果取值为none,则必须明确指定使用到的变量是共享的还是私有的。
reduction
reduction指定对一个或多个参数指定一个操作符,线程首先创建一个私有拷贝进行计算,在并行区域结束处对值进行指定计算,更新原始参数:
1 2 3 4 5 6 int i, sum = 100 ;#pragma omp parallel for reduction(+: sum) for ( i = 0 ; i < 1000 ; i++ ){ sum += i; } printf ( "sum = %ld\n" , sum);
copyin
copyin中的参数必须被声明为threadprivate,并有明确的拷贝赋值,用于将主线程中threadprivate的值拷贝到并行区域中的threadprivate变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int main (int argc, char * argv[]) int iterator; #pragma omp parallel sections copyin(counter) { #pragma omp section { int count1; for ( iterator = 0 ; iterator < 100 ; iterator++ ){ count1 = increment_counter (); } printf ("count1 = %ld\n" , count1); } #pragma omp section { int count2; for ( iterator = 0 ; iterator < 200 ; iterator++ ){ count2 = increment_counter (); } printf ("count2 = %ld\n" , count2); } } printf ("counter = %ld\n" , counter); }
copyprivate
该子句可将一个私有变量值广播到执行同一并行区域的其他线程。copyprivate子句可以关联single构造,可以对private和threadprivate子句中的变量进行操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int counter = 0 ;#pragma omp threadprivate(counter) int increment_counter () counter++; return (counter); } #pragma omp parallel { int count; #pragma omp single copyprivate(counter) { counter = 50 ; } count = increment_counter (); printf ("ThreadId: %ld, count = %ld\n" , omp_get_thread_num (), count); }
5.任务调度 OpenMP中的任务调度主要用于并行for循环,因为循环中迭代的计算量常常不相等,例如:
1 2 3 4 5 6 7 int i, j;int a[100 ][100 ] = {0 };for (i=0 ;i<100 ;i++){ for (j=i;j<100 ;j++){ a[i][j] = i*j; } }
最外层并行化后,假设有4个线程,每个线程执行25次循环,i为0-25和i为75-99显然计算量有很大差别,出现较大的负载不平衡问题。OpenMP通过schedule子句进行任务调度。
schedule子句的格式为schedule(type[,size]) ,size参数是可选的,调度类型有:
dynamic
guided
runtime
static
runtime是根据环境变量选择另外三种之一。
size参数表示循环迭代次数,必须是整数,可以不使用该参数。
静态调度
没有schedule子句时,默认使用静态调度,通常使用平均分配n/t个循环给每个线程。如果指定size,会依次给每个线程分配size次连续迭代计算:
1 2 3 4 #pragma omp parallel for schedule(static, 2) for (i = 0 ; i < 10 ; i++ ){ printf ("i=%d, thread_id=%d\n" , i, omp_get_thread_num ()); }
thread1分配到迭代0,1,4,5,8,9。
动态调度
动态调度动态地将迭代分配到各个线程,可使用size参数,使用size后会每次分配给线程指定size次迭代。
guided
guided调度时一种启发式自调度方法,开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减,指数下降到size(未指定则降到1)。
6.锁 参考文档的作者给出了一份测试OpenMP中锁和原子操作性能的比较,测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 #include <windows.h> #include <time.h> #include <process.h> #include <omp.h> #include <stdio.h> void TestAtomic () clock_t t1, t2; int i = 0 ; volatile LONG a = 0 ; t1 = clock (); for (i = 0 ; i < 2000000 ; i++) { InterlockedIncrement (&a); } t2 = clock (); printf ( "SingleThread, InterlockedIncrement 2,000,000: a = %ld, time = %ld\n" , a, t2 - t1); t1 = clock (); #pragma omp parallel for for (i = 0 ; i < 2000000 ; i++) { InterlockedIncrement (&a); } t2 = clock (); printf ("MultiThread, InterlockedIncrement 2,000,000: a = %ld, time = %ld\n" , a, t2 - t1); } void TestOmpLock () clock_t t1, t2; int i; int a = 0 ; omp_lock_t mylock; omp_init_lock (&mylock); t1 = clock (); for (i = 0 ; i < 2000000 ; i++) { omp_set_lock (&mylock); a += 1 ; omp_unset_lock (&mylock); } t2 = clock (); printf ("SingleThread,omp_lock 2,000,000:a = %ld, time = %ld\n" , a, t2 - t1); t1 = clock (); #pragma omp parallel for for (i = 0 ; i < 2000000 ; i++) { omp_set_lock (&mylock); a += 1 ; omp_unset_lock (&mylock); } t2 = clock (); printf ("MultiThread,omp_lock 2,000,000:a = %ld, time = %ld\n" , a, t2 - t1); omp_destroy_lock (&mylock); } void TestCriticalSection () clock_t t1, t2; int i; int a = 0 ; CRITICAL_SECTION cs; InitializeCriticalSection (&cs); t1 = clock (); for (i = 0 ; i < 2000000 ; i++) { EnterCriticalSection (&cs); a += 1 ; LeaveCriticalSection (&cs); } t2 = clock (); printf ("SingleThread, Critical_Section 2,000,000:a = %ld, time = %ld\n" , a, t2 - t1); t1 = clock (); #pragma omp parallel for for (i = 0 ; i < 2000000 ; i++) { EnterCriticalSection (&cs); a += 1 ; LeaveCriticalSection (&cs); 24 / 28 } t2 = clock (); printf ("MultiThread, Critical_Section, 2,000,000:a = %ld, time = %ld\n" , a, t2 - t1); DeleteCriticalSection (&cs); } int main (int argc, char *argv[]) TestAtomic (); TestCriticalSection (); TestOmpLock (); return 0 ; }
运行了一下,结果是:
1 2 3 4 5 6 SingleThread, InterlockedIncrement 2,000,000: a = 2000000, time = 16 MultiThread, InterlockedIncrement 2,000,000: a = 4000000, time = 64 SingleThread, Critical_Section 2,000,000:a = 2000000, time = 34 MultiThread, Critical_Section, 2,000,000:a = 4000000, time = 331 SingleThread,omp_lock 2,000,000:a = 2000000, time = 111 MultiThread,omp_lock 2,000,000:a = 4000000, time = 11315
锁明显更慢,不过这个测试结果和作者的不一样,显然是受一些其他因素影响的。
7.性能优化 动态设置并行循环的线程数量
并行循环的线程数量应该考虑到,循环次数比较少时,不应使用过多线程,且线程数量不应该远大于CPU核数。
以下是一个例子(在学习std::thread时,也有一个类似的例子,使用std::thread::hard_concurrency()来确定线程数量):
1 2 3 4 5 6 7 8 9 const int g_ncore = omp_get_num_procs (); int dtn (int n, int min_n) int max_tn = n / min_n; int tn = max_tn > g_ncore ? g_ncore : max_tn; if (tn < 1 ) { tn = 1 ; } return tn; }
在每次并行化时直接使用函数来获取合适的线程数量:
1 2 3 4 #pragma omp parallel for num_threads(dtn(n, MIN_ITERATOR_NUM)) for ( i = 0 ; i < n; i++ ){ printf ("Thread Id = %ld\n" , omp_get_thread_num ()); }
嵌套循环的并行化
嵌套循环中,如果外层循环迭代次数较少时,很难通过调度达到负载的平衡,有时可以通过将外层循环和内层的一层循环合并来提高外层循环的迭代次数。参考文档中给出了一个矩阵乘法的优化例子。
其他
减少创建线程的开销:使用线程池
提高对局部性的利用:使用线程私有变量,复制数据副本为多线程使用
用尽可能大的并行区,减小启动开销;消除不必要的隐式同步(nowait)
最小化数据依赖:使用私有变量消除依赖,选择合适的同步方式,尽可能少的使用同步,减少临界区,尽量使用reduction或原子性操作
选择合适的调度策略
核绑定
有三种方式:spread,close,master,详见https://www.openmp.org/wp-content/uploads/openmp-examples-4.5.0.pdf。
1 #prama omp parallel for proc_bind(close)
除了程序中绑定,也可以使用环境变量绑定:
1 2 3 export OMP_NUM_THREADS=8 export OMP_PROC_BIND=close #false spread export OMP_PLACES=cores #sockets threads numa_domains..
二.练习 点积 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <iostream> #include <omp.h> #include <ctime> #include <stdlib.h> const int N = 1e8 +5 ;const int MIN_SIZE = 1e5 ;const int cores = omp_get_num_procs ();int dtn () int max_tn = N/MIN_SIZE; int tn = max_tn > cores ? cores : max_tn; if (tn<1 ) tn = 1 ; return tn; } void initialize (int *a, int *b) for (int i=0 ;i<N;i++){ a[i] = rand ()%100 ; b[i] = rand ()%100 ; } } int dot_product_serial (int *a, int *b, int len) int sum = 0 ; for (int i=0 ;i<len;i++){ sum += a[i]*b[i]; } return sum; } int dot_product_parallel (int *a, int *b, int len) int sum = 0 , i; #pragma omp parallel for reduction(+:sum) num_threads(dtn()) for (i=0 ;i<len;i++){ sum += a[i]*b[i]; } return sum; } int main () int *a = new int [N]; int *b = new int [N]; int res_serial, res_parallel; clock_t start,end; initialize (a,b); start = clock (); res_serial = dot_product_serial (a,b,N); end = clock (); std::cout << "serial calculation time is " << (double )(end-start)/CLOCKS_PER_SEC << "s" <<std::endl; start = clock (); res_parallel = dot_product_parallel (a,b,N); end = clock (); std::cout << "parallel calculation time is " << (double )(end-start)/CLOCKS_PER_SEC << "s" <<std::endl; delete [] a; delete [] b; }
结果是:
serial calculation time is 0.325s
如果将reduction改为原子性操作:
1 2 3 4 5 6 7 8 9 10 int dot_product_parallel (int *a, int *b, int len) int i; std::atomic<int > sum; atomic_init (&sum, 0 ); #pragma omp parallel for num_threads(dtn()) for (i=0 ;i<len;i++){ sum.fetch_add (a[i]*b[i]); } return sum; }
则结果为:
serial calculation time is 0.315s
使用锁的时间当然更长:
1 2 3 4 5 6 7 8 9 10 11 12 13 int dot_product_parallel (int *a, int *b, int len) int i; int sum = 0 ; omp_lock_t mtx; omp_init_lock (&mtx); #pragma omp parallel for num_threads(dtn()) for (i=0 ;i<len;i++){ omp_set_lock (&mtx); sum += a[i]*b[i]; omp_unset_lock (&mtx); } return sum; }
由于反复上锁,比串行时间长得多。(太久了因此手动中断了计算)。
矩阵乘法 由于对矩阵的初始化也可以并行完成,这里尝试一下不同并行方式的时间,首先是只对for循环并行化,静态调度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void initialize_parallel (int *a, int *b) #pragma omp parallel for num_threads(dtn()) for (int i=0 ;i<r_a;i++){ for (int j=0 ;j<c_a;j++){ a[i*c_a+j] = rand ()%100 ; } } #pragma omp parallel for num_threads(dtn()) for (int i=0 ;i<r_b;i++){ for (int j=0 ;j<c_b;j++){ b[i*c_b+j] = rand ()%100 ; } } }
时间为0.076s。
尝试修改为动态调度,时间为0.068s,因为这里对外层均分后,负载是均衡的,因此静态分配就可以了。
最后让两个矩阵的初始化并行执行,时间为0.25s,明显快多了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void initialize_parallel (int *a, int *b) #pragma omp parallel sections { #pragma omp section { #pragma omp parallel for num_threads(dtn()) for (int i=0 ;i<r_a;i++){ for (int j=0 ;j<c_a;j++){ a[i*c_a+j] = rand ()%100 ; } } } #pragma omp section { #pragma omp parallel for num_threads(dtn()) for (int i=0 ;i<r_b;i++){ for (int j=0 ;j<c_b;j++){ b[i*c_b+j] = rand ()%100 ; } } } } }
并行化计算的完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 #include <iostream> #include <omp.h> #include <stdlib.h> #include <time.h> const int MAX_COL = 1e6 ;const int MIN_SIZE = 1e4 ;const int cores = omp_get_num_procs ();const int r_a = 1e3 , c_a = 1e4 , r_b = 1e4 , c_b = 1e3 ;int dtn () int max_tn = MAX_COL/MIN_SIZE; int tn = max_tn > cores ? cores : max_tn; if (tn<1 ) tn = 1 ; return tn; } void initialize_parallel (int *a, int *b) #pragma omp parallel sections { #pragma omp section { #pragma omp parallel for num_threads(dtn()) for (int i=0 ;i<r_a;i++){ for (int j=0 ;j<c_a;j++){ a[i*c_a+j] = rand ()%100 ; } } } #pragma omp section { #pragma omp parallel for num_threads(dtn()) for (int i=0 ;i<r_b;i++){ for (int j=0 ;j<c_b;j++){ b[i*c_b+j] = rand ()%100 ; } } } } } bool verify (int *a, int *b) for (int i=0 ;i<r_a;i++){ for (int j=0 ;j<c_b;j++){ if (a[i*c_b+j]!=b[i*c_b+j]) return false ; } } return true ; } void matrix_multiple_ser (int *a, int *b, int *c) for (int i=0 ;i<r_a;i++){ for (int j=0 ;j<c_b;j++){ int val = 0 ; for (int k=0 ;k<c_a;k++){ val += a[i*c_a+k]*b[k*c_b+j]; } c[i*c_b+j] = val; } } } void matrix_multiple_par (int *a, int *b, int *c) int i,j,val,num_threads; num_threads = dtn (); std::cout << "num of threads is " << num_threads << std::endl; #pragma omp parallel for num_threads(num_threads) private(val,j) for (int i=0 ;i<r_a;i++){ for (j=0 ;j<c_b;j++){ val = 0 ; for (int k=0 ;k<c_a;k++){ val += a[i*c_a+k]*b[k*c_b+j]; } c[i*c_b+j] = val; } } } int main () int *matrix_a = new int [r_a*c_a]; int *matrix_b = new int [r_b*c_b]; int *matrix_c = new int [r_a*c_b]; int *matrix_d = new int [r_a*c_b]; clock_t start,end; start = clock (); initialize_parallel (matrix_a, matrix_b); end = clock (); std::cout<< "initialize_parallel time is " << (double )(end-start)/CLOCKS_PER_SEC << "s" << std::endl; start = clock (); matrix_multiple_ser (matrix_a, matrix_b, matrix_c); end = clock (); std::cout << "serial calculation time is " << (double )(end-start)/CLOCKS_PER_SEC << "s" << std::endl; start = clock (); matrix_multiple_par (matrix_a,matrix_b,matrix_d); end = clock (); std::cout << "parallel calculation time is " << (double )(end-start)/CLOCKS_PER_SEC << "s" << std::endl; if (verify (matrix_c,matrix_d)) std::cout << "correct" << std::endl; else std::cout << "wrong anwser!" << std::endl; delete [] matrix_a; delete [] matrix_b; delete [] matrix_c; delete [] matrix_d; return 0 ; }
输出结果:
1 2 3 4 5 initialize_parallel time is 0.242s serial calculation time is 33.917s num of threads is 12 parallel calculation time is 7.139s correct
再尝试循环展开,基本不影响计算时间。
将循环顺序调整为ikj:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void matrix_multiple_par (int *a, int *b, int *c) int i,j,k,val,num_threads; num_threads = dtn (); std::cout << "num of threads is " << num_threads << std::endl; #pragma omp parallel for num_threads(num_threads) private(val,j,k) for (int i=0 ;i<r_a;i++){ for (k=0 ;k<c_a;k++){ for (j=0 ;j<c_b;j++){ c[i*c_b+j] += a[i*c_a+k]*b[k*c_b+j]; } } } }
时间为:
1 2 3 4 5 initialize_parallel time is 0.238s serial calculation time is 33.101s num of threads is 12 parallel calculation time is 5.274s correct
尝试一下O3优化,结果为:
1 2 3 4 5 initialize_parallel time is 0.149s serial calculation time is 13.204s num of threads is 12 parallel calculation time is 0.495s correct
整体时间大幅减少。这也可以看出上面的并行版本还有非常大的优化空间,包括使用AVX,缓存优化及转置等。
三.问题 这部分内容来自https://heptagonhust.github.io/HPC-roadmap/:
什么是OpenMP?有什么作用?
OpenMP是一套支持跨平台共享内存方式的多线程并发的编程API。
OpenMP可用于并行算法的多线程实现。
什么是数据依赖?什么是数据冲突?如何解决?(这里还有一个概念是数据相关,和数据依赖是基本一致的概念。)
数据相关是流水线中操作数之间的依赖关系。对应三种数据依赖。
数据依赖是指一条指令依赖于另外一条指令执行的结果,有三种类型(WAR反相关,RAW真相关,WAW输出相关),是数据相关的根源。(在Tomasulo算法中,反相关和输出相关都是可以靠保留站实现寄存器重命名而避免冲突的)
数据冲突是在流水线中由于数据依赖(数据相关)导致的冲突。
解决数据冲突的方式有:指令重排序,暂停流水线,转发,寄存器重命名。
什么是原子操作?为什么需要原子操作?
原子操作是不会被打断的操作,可以保证数据的一致性,避免竞态条件,在多线程程序对共享资源的访问中需要保证操作的原子性。
对原子变量的操作可以使用std::atomic,在OpenMP中也可以使用atomic子句,只能用于单条赋值语句,但是比锁更高效。
我该选择多少线程来运行呢?线程数量越多越好吗?
线程数不应远大于核数,并且单个线程的工作不能太小。
我的代码运行正确吗?如何检验优化后代码运行的正确性?
在编写代码时,一定要先实现最简单的串行算法,以验证结果的正确性。
和pthread的区别与联系?
OpenMP是基于编译器指令 的并行编程模型,而pthread是基于POSIX标准的线程库。
OpenMP简单易用,但是功能有限,不能使用条件变量,信号量等,不能表达复杂的线程交互与同步。用于简单的数据并行或任务并行。
OpenMP可以使用pthread作为底层实现(gcc就是这样做的)。