CS149-Assignment-1&2。
CS149:https://gfxcourses.stanford.edu/cs149/fall23/
program 1: Parallel Fractal Generation Using Threads 需要用std::thread并行化mandelbrot程序,该程序对二维的数据进行处理得到图像数据,直接改mandelbrotThread中的代码。由于框架已经写好,直接将height分配一下,调用串行函数就可以了。
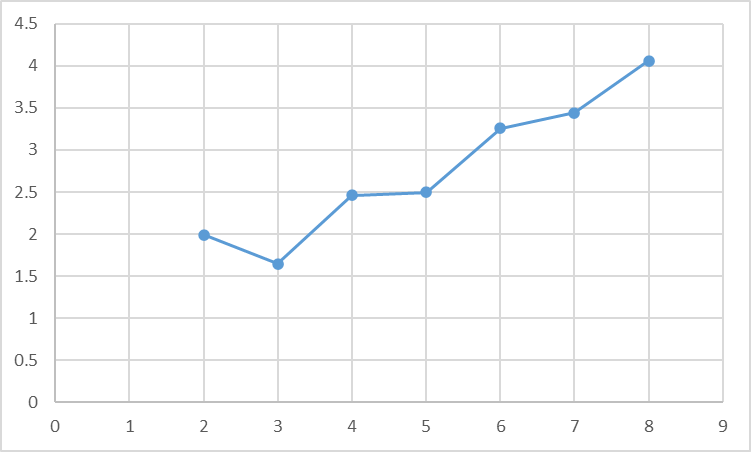
尝试使用不同数量的线程,比较加速比,本机是6核12逻辑处理器。
线程数
加速比
2
1.99
3
1.65
4
2.46
5
2.50
6
3.26
7
3.44
8
4.06
显然加速比不是线性的,而且在奇数个线程时,线程增加没有明显的变化。在3个线程时,还比只有两个线程更慢。原因是负载不均衡的问题。为了验证,记录线程的计算时间,结果为:
线程1即第二个线程的计算时间更长,看来图像中间行的计算量比上下要大很多。从图像也看的出来:
同理对view2进行测量,8线程的加速比是4.09x,但是图像上方的计算量更大,线程0和1的工作负载更大。
为了实现题目要求的7-8x的加速比,需要通过静态分配来实现负载的均衡。因此尝试每个线程不计算连续的行,而是交替进行分配来进行均衡。进行尝试以后view1的6线程加速比达到了5.70x,但是7和8线程反而加速比下降了。不知道在虚拟机上跑该程序,是不是没有用到超线程。view2的6线程加速比为4.60x。应该是机器的问题。
题中最后还问了16线程运行程序会不会有性能提升,显然在我的机器上不会了,6线程就是最佳性能了。
Program 2: Vectorizing Code Using SIMD Intrinsics 该任务的要求是使用cs149intrin.h中的fake SIMD指令对一个程序进行向量化。提供了一个向量化abs为参考。这个向量化的abs是不完整的,N%VECTOR_WIDTH的部分没有计算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void absVector (float * values, float * output, int N) __cs149_vec_float x; __cs149_vec_float result; __cs149_vec_float zero = _cs149_vset_float(0.f ); __cs149_mask maskAll, maskIsNegative, maskIsNotNegative; for (int i=0 ; i<N; i+=VECTOR_WIDTH) { maskAll = _cs149_init_ones(); maskIsNegative = _cs149_init_ones(0 ); _cs149_vload_float(x, values+i, maskAll); _cs149_vlt_float(maskIsNegative, x, zero, maskAll); _cs149_vsub_float(result, zero, x, maskIsNegative); maskIsNotNegative = _cs149_mask_not(maskIsNegative); _cs149_vload_float(result, values+i, maskIsNotNegative); _cs149_vstore_float(output+i, result, maskAll); } }
未向量化的程序为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void clampedExpSerial (float * values, int * exponents, float * output, int N) for (int i=0 ; i<N; i++) { float x = values[i]; int y = exponents[i]; if (y == 0 ) { output[i] = 1.f ; } else { float result = x; int count = y - 1 ; while (count > 0 ) { result *= x; count--; } if (result > 9.999999f ) { result = 9.999999f ; } output[i] = result; } } }
仿照abs中的内容进行向量化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void clampedExpVector (float * values, int * exponents, float * output, int N) __cs149_vec_float x, maxVal; __cs149_vec_int exp, zero, one; __cs149_vec_float result; __cs149_mask maskAll, maskCal, maskGtMax; int i; zero = _cs149_vset_int(0 ); one = _cs149_vset_int(1 ); maxVal = _cs149_vset_float(9.999999f ); maskAll = _cs149_init_ones(); for (i=0 ;i+VECTOR_WIDTH<=N;i+=VECTOR_WIDTH){ _cs149_vload_float(x, values+i, maskAll); _cs149_vload_int(exp, exponents+i, maskAll); result = _cs149_vset_float(1.f ); _cs149_vgt_int(maskCal, exp, zero, maskAll); while (_cs149_cntbits(maskCal)!=0 ){ _cs149_vmult_float(result, result, x, maskCal); _cs149_vsub_int(exp, exp, one, maskCal); _cs149_vgt_int(maskCal, exp, zero, maskCal); } _cs149_vgt_float(maskGtMax, result, maxVal, maskAll); _cs149_vset_float(result, 9.999999f , maskGtMax); _cs149_vstore_float(output+i, result, maskAll); } if (i!=N){ i -= VECTOR_WIDTH; clampedExpSerial (values+i, exponents+i, output+i, N-i); } }
在size为10000下,将向量宽度改为2,4,8,16,向量利用率为79.8%,72.1%,68.1%,66.3%,因为在向量宽度很大时,会有很多lanes是disabled,计算就失去了向量化的优势。
extra bonus是array_sum的计算,主要是多了使用hadd和interleave指令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 float arraySumVector (float * values, int N) __cs149_vec_float result; __cs149_vec_float value; __cs149_mask maskAll; result = _cs149_vset_float(0 ); maskAll = _cs149_init_ones(); for (int i=0 ; i<N; i+=VECTOR_WIDTH) { _cs149_vload_float(value, values+i, maskAll); _cs149_vadd_float(result, value, result, maskAll); } int width = VECTOR_WIDTH; while (width/=2 ){ _cs149_hadd_float(result,result); _cs149_interleave_float(result,result); } float tmp[VECTOR_WIDTH]; _cs149_vstore_float(tmp,result,maskAll); return tmp[0 ]; }
Program 3: Parallel Fractal Generation Using ISPC program3仍然是一个计算图形的程序,但这次要使用ISPC进行并行化。ISPC用于描述独立计算 ,图形计算中每个像素点是独立的,因此可以采用ISPC。提供的程序有一些问题,根据说明,修改之后应该能实现32x的加速比。
尽管和C/C++ code很像,但ISPC的实现是不同的,程序实例会在CPU的SIMD执行单元并行执行,实例的数量由编译器器根据具体机器决定,可以通过变量programCount获取,每个实例有自己的programIndex。调用ISPC函数相当于创建了一组程序实例,运行结束后将控制返回caller。
ISPC也有两种实现,一种是命令式的,指明任务的分配,另一种是声明式的,用于计算独立的情况,可以专注于将问题分解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 export sum (uniform int N, uniform float * a, uniform float * b, uniform float * c) for (int i=0 ; i<N; i+=programCount) { c[programIndex + i] = a[programIndex + i] + b[programIndex + i]; } } export sum2 (uniform int N, uniform float * a, uniform float * b, uniform float * c) foreach (i = 0 ... N) { c[i] = a[i] + b[i]; } }
给出的mandelbrot图像计算程序可以达到5.74x的加速比,由于ISPC会转换程序为宽度为8的AVX向量指令,理想的加速比是8x,没有达到理想加速比的原因是计算负载的不均衡。与program1不同的是,这次的计算是利用向量化在单核上进行的。
ISPC也提供了利用多核的方法,可以使用launch命令来创建并行任务,任务可以在不同的核中以任意顺序并行执行。使用—tasks参数启动给出的程序,可以达到11.27x的加速比。
在给出的代码中,task数是2,虚拟机是8核的,如果创建8个task的话,加速比可以达到24.45x;创建10个task,加速比达到30.30x。本来到这里就应该差不多了,因为在program1时6线程就是最佳性能了,即使假设用到超线程,也只是取12,但奇怪的是,我将task改为20(因为height是800,这样可以整除),加速比又有了一点提升,将task改为50,加速比竟然上升到了36.44x。这个加速比本身不算特别大,因为说明中已经告诉了加速比可以超过32x,但为什么task加到这么多才达到最大加速比,暂时我还没有想法。
ISPC以非常便捷的方式实现了最大性能,向量化只要使用foreach语句就可以实现,线程也只需要launch命令就可以开启,极大提高了并行编程的效率。
作为参考学习,这个program的多核并行ISPC代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 task void mandelbrot_ispc_task (uniform float x0, uniform float y0, uniform float x1, uniform float y1, uniform int width, uniform int height, uniform int rowsPerTask, uniform int maxIterations, uniform int output[]) uniform int ystart = taskIndex * rowsPerTask; uniform int yend = ystart + rowsPerTask; uniform float dx = (x1 - x0) / width; uniform float dy = (y1 - y0) / height; foreach (j = ystart ... yend, i = 0 ... width) { float x = x0 + i * dx; float y = y0 + j * dy; int index = j * width + i; output[index] = mandel (x, y, maxIterations); } } export void mandelbrot_ispc_withtasks (uniform float x0, uniform float y0, uniform float x1, uniform float y1, uniform int width, uniform int height, uniform int maxIterations, uniform int output[]) uniform int rowsPerTask = height / 50 ; launch[50 ] mandelbrot_ispc_task (x0, y0, x1, y1, width, height, rowsPerTask, maxIterations, output); }
Program 4: Iterative sqrt program4给出了一个迭代计算根号值的程序。首先需要做的是比较ISPC的单核SIMD并行和多核并行加速比。
得到的结果如下,task数为64:
第二个任务是通过修改数组的值来提高加速比,可以将数组的值改为相同的值,这样SIMD计算时速度会更快,并且通过给出的图可以看出,在接近3时迭代计算是最多的,这样可以最大化加速比。修改后单核加速比达到8.90x,多核并行达到59.55x。
Program 5: BLAS saxpy
program5给出了一个saxpy计算的实现,saxpy的计算为result = scale*X+Y,result,X和Y都是向量。运行程序,多核并行对单核并行的加速比只有1.23x,原因是向量的SIZE是20M,超过了memory的带宽,因此性能受到了限制。保持这个SIZE可能没法有性能提升了。
Assignment 2: Building A Task Execution Library from the Ground Up Assignment2的任务是完成一个并行库(类似ISPC LAUNCH),以线程池的方式实现并行任务执行接口,并能够进行工作的同步和协调,还要能够对工作进行合理调度。
Part A: Synchronous Bulk Task Launch 任务执行的接口定义在抽象类itasksys.h中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class IRunnable { public : virtual ~IRunnable (); virtual void runTask (int task_id, int num_total_tasks) 0 ; }; class ITaskSystem { public : ITaskSystem (int num_threads); virtual ~ITaskSystem (); virtual const char * name () 0 ; virtual void run (IRunnable* runnable, int num_total_tasks) 0 ; virtual TaskID runAsyncWithDeps (IRunnable* runnable, int num_total_tasks, const std::vector<TaskID>& deps) 0 ; virtual void sync () 0 ; };
runTask是由具体的testcase实现的,只需要TaskID就会执行自己部分的工作,TaskSystem只需要指定线程启动Task。
需要实现的TaskSystem有三个,复杂度是递增的:
TaskSystemParallelSpawn
TaskSystemParallelThreadPoolSpinning
TaskSystemParallelThreadPoolSleeping
完成后通过runtasks进行测试,最简单的一个用来debug的测试是SimpleTest。
1 2 # -n指定最大线程数 有许多testcase,定义在test.h中 ./runtasks -n 8 mandelbrot_chunked
test程序会准备Task,然后使用TaskSystem启动Task。在simpleTest中,将相同的Tasks 执行了两次,并且在异步执行中按照顺序执行两次Tasks。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 TestResults simpleTest (ITaskSystem* t, bool do_async) { SimpleMultiplyTask first = SimpleMultiplyTask (num_elements, array); SimpleMultiplyTask second = SimpleMultiplyTask (num_elements, array); double start_time = CycleTimer::currentSeconds (); if (do_async) { std::vector<TaskID> firstDeps; TaskID first_task_id = t->runAsyncWithDeps (&first, num_tasks, firstDeps); std::vector<TaskID> secondDeps; secondDeps.push_back (first_task_id); t->runAsyncWithDeps (&second, num_tasks, secondDeps); t->sync (); } else { t->run (&first, num_tasks); t->run (&second, num_tasks); } double end_time = CycleTimer::currentSeconds (); return results; }
先从最简单的串行来理解TaskSystem,run函数启动了total_task次Task,而异步执行和sync函数在串行情况下都不需要实现。对于并行版本,应该使用不同线程调用runnable的runTask函数,来并行启动Task。
1 2 3 4 5 void TaskSystemSerial::run (IRunnable* runnable, int num_total_tasks) for (int i = 0 ; i < num_total_tasks; i++) { runnable->runTask (i, num_total_tasks); } }
TaskSystemParallelSpawn 这个版本只需要创建线程,分配Task。在该类中需要在构造时保存最大线程数。
1 2 3 TaskSystemParallelSpawn::TaskSystemParallelSpawn (int num_threads): ITaskSystem (num_threads) { this ->num_threads = num_threads; }
任务是根据TaskID在runnable中分好的,线程只需要调用runTask,并传入TaskID。Task的分配可以是静态的,也可以是动态的。静态的分配如下(交错分配):
1 2 3 4 5 6 7 8 9 10 11 12 13 void TaskSystemParallelSpawn::run (IRunnable* runnable, int num_total_tasks) std::thread threads[num_threads]; for (int i=0 ;i<num_threads;i++){ threads[i] = std::thread ([runnable, num_total_tasks, i](int num_threads){ int id = i; while (id<num_total_tasks){ runnable->runTask (id, num_total_tasks); id += num_threads; } }, num_threads); } for (int i=0 ;i<num_threads;i++) threads[i].join (); }
动态分配如下:
1 2 3 4 5 6 7 8 9 10 11 12 void TaskSystemParallelSpawn::run (IRunnable* runnable, int num_total_tasks) std::thread threads[num_threads]; std::atomic<int > taskID (0 ) ; for (auto &thread: threads){ thread = std::thread ([&taskID, runnable,num_total_tasks]{ for (int id=taskID++;id<num_total_tasks;id=taskID++) runnable->runTask (id, num_total_tasks); }); } for (auto &thread: threads){ thread.join (); } }
对于这个测试来说,动态分配和静态分配的结果差不多。有一些testcase使用动态分配的话会比串行时间更长,应该是由于获取task时的原子操作开销大,Task数量多但计算少导致的。
TaskSystemParallelThreadPoolSpinning 在这个版本中,需要实现线程池,在TaskSystem构造或第一次调用run时创建线程。线程创建后进入自旋,并持续检查是否有工作需要完成(通过当前task_id和total_task值)。相应的需要使用同步机制确认所有task完成,这里直接让主线程在条件变量上休眠,等待所有线程完成任务后,由最后一个线程来唤醒主线程。
核心的部分就是线程的工作以及TaskSystem的Run,所有的线程在TaskSystem构造时启动,析构时修改flag,然后等待线程结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void TaskSystemParallelThreadPoolSpinning::ThreadFunc () int my_task_id, num_total_tasks; while (true ){ if (shut_down) break ; mtx.lock (); my_task_id = tasks->next_task_id++; num_total_tasks = tasks->num_total_tasks; mtx.unlock (); if (my_task_id<num_total_tasks){ tasks->runnable->runTask (my_task_id, num_total_tasks); mtx.lock (); tasks->task_finished++; if (tasks->task_finished==num_total_tasks){ mtx.unlock (); condition_mtx.lock (); done = true ; condition_mtx.unlock (); task_done.notify_all (); } else mtx.unlock (); } } } void TaskSystemParallelThreadPoolSpinning::run (IRunnable* runnable, int num_total_tasks) mtx.lock (); this ->tasks->runnable = runnable; this ->tasks->next_task_id = 0 ; this ->tasks->num_total_tasks = num_total_tasks; this ->tasks->task_finished = 0 ; this ->done = false ; mtx.unlock (); std::unique_lock<std::mutex> lk (this ->condition_mtx) ; while (!done) task_done.wait (lk); lk.unlock (); }
测试通过,时间和之前的版本差不多。
TaskSystemParallelThreadPoolSleeping 在这个版本中,要让线程在没有工作的时候休眠,而不是自旋等待。实际上就是实现消费者-生产者模型,用两个条件变量进行同步。需要注意在析构时,必须唤醒所有线程,为了保证线程在唤醒后不会再次进入睡眠,要把flag也修改掉。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 TaskSystemParallelThreadPoolSleeping::~TaskSystemParallelThreadPoolSleeping () { shut_down = true ; std::unique_lock<std::mutex> lk (cmtx) ; done = false ; sleeping_queue.notify_all (); lk.unlock (); for (int i=0 ;i<num_threads;i++) threads_pool[i].join (); delete [] threads_pool; delete tasks; } void TaskSystemParallelThreadPoolSleeping::ThreadFunc () int my_task_id, num_total_tasks; while (true ){ if (shut_down) break ; mtx.lock (); my_task_id = tasks->next_task_id++; num_total_tasks = tasks->num_total_tasks; mtx.unlock (); if (my_task_id<num_total_tasks){ tasks->runnable->runTask (my_task_id, num_total_tasks); mtx.lock (); tasks->task_finished++; if (tasks->task_finished==num_total_tasks){ mtx.unlock (); cmtx.lock (); done = true ; cmtx.unlock (); task_done.notify_all (); } else mtx.unlock (); } else { std::unique_lock<std::mutex> lk (cmtx); while (done) sleeping_queue.wait (lk); lk.unlock (); } } } void TaskSystemParallelThreadPoolSleeping::run (IRunnable* runnable, int num_total_tasks) mtx.lock (); done = false ; tasks->runnable = runnable; tasks->num_total_tasks = num_total_tasks; tasks->task_finished = 0 ; tasks->next_task_id = 0 ; mtx.unlock (); std::unique_lock<std::mutex> lk (cmtx) ; while (!done) { sleeping_queue.notify_all (); task_done.wait (lk); } lk.unlock (); }
测试通过。
与reference的比较测试 只有一个math_operations_in_tight_for_loop_fewer_tasks的testcase的perf结果是1.35不合格,大部分都不超过1。不过这个testcase单独跑可以过,每次运行性能都有一点变化。
Part B: Supporting Execution of Task Graphs partB需要实现能够异步执行任务,并且可以保证任务之间的依赖关系。给出的提示是创建两个队列分别处理仍然存在依赖的task bulk和可以执行的task bulk。任务组数量不超过int范围。
这个PartB对于不熟悉并发编程的我来说遇到了非常多的困难,改了很多次都没办法跑通。于是看了一些其他人的实现,奇怪的是在github上找的两个实现也跑不通(不是无法通过,而是完全跑不出来),其中这位HUST同学的实现 是正确的,但是对于他的实现我有一些不理解的地方,主要是将等待的TaskBulk放入ready_queue的过程,为什么是放在sync()当中的,这样只有sync()调用后才会转移有依赖的bulk进入待执行队列,感觉更应该把转移工作放在线程中,而不是要等到sync()调用后才处理。此外还看到了单独使用一个线程进行调度的实现,那一种应该更好实现一些,只需要调度器和主线程进行同步,不过性能就差了。
尽管参考了一些他人的实现,最后还是按照自己的思路完成的,在经历了两天的重写和修改后,终于能跑通了。在这个过程中其实思路没什么问题,在debug的过程中熟悉了一下gdb调试多线程程序,找到了一直无法运行的原因是主线程结束并析构TaskSystem时join子线程,而子线程休眠在条件变量上。要注意的问题主要有:
有哪些数据结构需要上锁,哪些不需要
每个线程在条件变量被唤醒有哪些可能的原因
当前线程条件变量的锁可能是从谁手中获得的,有哪些可能
是否能保证状态的改变可以被看到,需要重点考虑目标线程不是从休眠状态唤醒的情况,如果刚好对方休眠,那么唤醒对方后,对方应该检查状态,这样就一定能看到状态的改变,但如果对方没有休眠,需要确保对方在任何一个位置都能继续执行并到达检查状态的位置
实现 为了方便管理任务组,建立了一个结构体,保存任务组的所有信息,包括依赖的任务组ID以及一个用于原子读写num_tasks_done和next_task_id的锁,这两个数据会被多个线程访问。
1 2 3 4 5 6 7 8 9 10 struct TaskBulk { TaskID id; IRunnable *runnable; int num_total_tasks = 0 ; int num_tasks_done = 0 ; int next_task_id = 0 ; std::unordered_set<TaskID> dependencies; std::mutex bulk_mtx; TaskBulk (TaskID _id, IRunnable *_runnable, int _num_total_tasks, const std::vector<TaskID> &_deps): id (_id), runnable (_runnable), num_total_tasks (_num_total_tasks), dependencies (_deps.begin (), _deps.end ()){}; };
TaskSystem类如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class TaskSystemParallelThreadPoolSleeping : public ITaskSystem { private : int num_threads; TaskID next_id; bool done; bool terminate; std::atomic<int > num_bulk_done; std::thread *thread_pool; std::vector<TaskBulk*> waiting; std::vector<TaskBulk*> ready; std::unordered_set<TaskBulk*> all_bulks; std::unordered_set<TaskID> finished_bulk; std::condition_variable sleeping_cv; std::condition_variable waiting_cv; std::mutex qmtx; std::mutex cmtx; void ThreadFunc () void CheckWaiting () public : TaskSystemParallelThreadPoolSleeping (int num_threads); ~TaskSystemParallelThreadPoolSleeping (); const char * name () void run (IRunnable* runnable, int num_total_tasks) TaskID runAsyncWithDeps (IRunnable* runnable, int num_total_tasks, const std::vector<TaskID>& deps) void sync () };
TaskSystem的构造:
1 2 3 4 5 6 7 8 TaskSystemParallelThreadPoolSleeping::TaskSystemParallelThreadPoolSleeping (int num_threads): ITaskSystem (num_threads), num_bulk_done (0 ) { this ->num_threads = num_threads; terminate = false ; done = true ; next_id = 0 ; thread_pool = new std::thread[num_threads]; for (int i=0 ;i<num_threads;i++) thread_pool[i] = std::thread (&TaskSystemParallelThreadPoolSleeping::ThreadFunc, this ); }
TaskSystem的析构:
1 2 3 4 5 6 7 8 9 10 11 12 TaskSystemParallelThreadPoolSleeping::~TaskSystemParallelThreadPoolSleeping () { sync (); terminate = true ; std::unique_lock<std::mutex> lk (cmtx) ; done = false ; sleeping_cv.notify_all (); lk.unlock (); for (int i=0 ;i<num_threads;i++) thread_pool[i].join (); for (auto bulk: all_bulks) delete bulk; delete [] thread_pool; }
异步任务的启动:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 TaskID TaskSystemParallelThreadPoolSleeping::runAsyncWithDeps (IRunnable* runnable, int num_total_tasks, const std::vector<TaskID>& deps) TaskID the_id = next_id++; TaskBulk *new_bulk = new TaskBulk (the_id, runnable, num_total_tasks, std::move (deps)); all_bulks.insert (new_bulk); qmtx.lock (); if (deps.size ()==0 ) ready.push_back (new_bulk); else waiting.push_back (new_bulk); qmtx.unlock (); cmtx.lock (); done = false ; cmtx.unlock (); sleeping_cv.notify_all (); return the_id; }
同步,每次被唤醒后要重新检查是否所有任务都完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 void TaskSystemParallelThreadPoolSleeping::sync () std::unique_lock<std::mutex> lk (cmtx) ; while (!done){ waiting_cv.wait (lk); if (num_bulk_done==next_id) done = true ; else { done = false ; sleeping_cv.notify_all (); } } lk.unlock (); }
从等待队列转移任务到就绪队列,调用需要保证持有锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void TaskSystemParallelThreadPoolSleeping::CheckWaiting () std::vector<TaskBulk*> move; for (auto waiting_bulk: waiting){ for (auto it = waiting_bulk->dependencies.begin (); it != waiting_bulk->dependencies.end (); ) { if (finished_bulk.find (*it) != finished_bulk.end ()) { it = waiting_bulk->dependencies.erase (it); } else ++it; } if (waiting_bulk->dependencies.size ()==0 ) move.push_back (waiting_bulk); } for (auto remov: move){ auto it = std::find (waiting.begin (), waiting.end (), remov); waiting.erase (it); } for (auto enqueue: move) { ready.push_back (enqueue); } }
线程函数,这里我把将任务组从就绪队列删除的工作放在了任务组结束后,这样的话,如果默认选取就绪队列的第一个任务组,会有一些线程拿到大于num_total_task的任务而无效等待,相应的我将选择任务组改为随机,来减少这种无效的等待。其实可以在获取任务时,就将已经全部分配的任务组从就绪队列删除,但是我尝试这样做后,在极少数的情况下会有coredump或者疑似死锁的情况,由于出现的次数非常少,很难调试,我就直接放弃了这一种,还是用一开始写的这一种,只要任务组的数量稍多一些,应该很少有线程拿到id>=num_total_task的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 void TaskSystemParallelThreadPoolSleeping::ThreadFunc () int my_id, num_done; TaskBulk *my_bulk; while (!terminate){ std::unique_lock<std::mutex> lk (cmtx) ; if (terminate) return ; if (next_id==num_bulk_done){ done = true ; waiting_cv.notify_one (); } else done = false ; while (done){ waiting_cv.notify_one (); sleeping_cv.wait (lk); if (terminate) return ; if (next_id==num_bulk_done){ done = true ; waiting_cv.notify_one (); } else done = false ; } lk.unlock (); my_id = 0x3f3f3f3f ; my_bulk = nullptr ; qmtx.lock (); if (ready.empty ()) CheckWaiting (); if (!ready.empty ()){ my_bulk = ready[rand ()%ready.size ()]; my_bulk->bulk_mtx.lock (); my_id = my_bulk->next_task_id++; my_bulk->bulk_mtx.unlock (); } qmtx.unlock (); if (my_bulk && my_id < my_bulk->num_total_tasks){ my_bulk->runnable->runTask (my_id, my_bulk->num_total_tasks); my_bulk->bulk_mtx.lock (); num_done = ++my_bulk->num_tasks_done; my_bulk->bulk_mtx.unlock (); if (num_done==my_bulk->num_total_tasks){ qmtx.lock (); num_bulk_done++; auto it = find_if (ready.begin (), ready.end (), [my_bulk](const TaskBulk* ptr) {return ptr == my_bulk;}); if (it!=ready.end ()){ ready.erase (it); } finished_bulk.insert (my_bulk->id); sleeping_cv.notify_all (); qmtx.unlock (); } } } }
与reference的比较测试 所有的测试都通过了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 y@ubuntu:~/桌面/CS149/asst2/part_b$ python ../tests/run_test_harness.py -a ================================================================================ Running task system grading harness... (22 total tests) - Detected CPU with 8 execution contexts - Task system configured to use at most 8 threads ================================================================================ ================================================================================ Executing test: super_super_light... Reference binary: ./runtasks_ref_linux Results for: super_super_light STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 51.694 49.241 1.05 (OK) ================================================================================ Executing test: super_super_light_async... Reference binary: ./runtasks_ref_linux Results for: super_super_light_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 10.132 20.943 0.48 (OK) ================================================================================ Executing test: super_light... Reference binary: ./runtasks_ref_linux Results for: super_light STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 67.003 61.637 1.09 (OK) ================================================================================ Executing test: super_light_async... Reference binary: ./runtasks_ref_linux Results for: super_light_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 42.82 45.168 0.95 (OK) ================================================================================ Executing test: ping_pong_equal... Reference binary: ./runtasks_ref_linux Results for: ping_pong_equal STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 201.44 235.962 0.85 (OK) ================================================================================ Executing test: ping_pong_equal_async... Reference binary: ./runtasks_ref_linux Results for: ping_pong_equal_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 181.643 224.728 0.81 (OK) ================================================================================ Executing test: ping_pong_unequal... Reference binary: ./runtasks_ref_linux Results for: ping_pong_unequal STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 297.235 287.366 1.03 (OK) ================================================================================ Executing test: ping_pong_unequal_async... Reference binary: ./runtasks_ref_linux Results for: ping_pong_unequal_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 275.763 281.908 0.98 (OK) ================================================================================ Executing test: recursive_fibonacci... Reference binary: ./runtasks_ref_linux Results for: recursive_fibonacci STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 247.546 262.125 0.94 (OK) ================================================================================ Executing test: recursive_fibonacci_async... Reference binary: ./runtasks_ref_linux Results for: recursive_fibonacci_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 246.797 267.185 0.92 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 335.786 309.661 1.08 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop_async... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 260.238 241.34 1.08 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop_fewer_tasks... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop_fewer_tasks STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 355.964 309.96 1.15 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop_fewer_tasks_async... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop_fewer_tasks_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 94.946 95.299 1.00 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop_fan_in... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop_fan_in STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 80.797 76.612 1.05 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop_fan_in_async... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop_fan_in_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 52.42 53.054 0.99 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop_reduction_tree... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop_reduction_tree STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 54.942 54.193 1.01 (OK) ================================================================================ Executing test: math_operations_in_tight_for_loop_reduction_tree_async... Reference binary: ./runtasks_ref_linux Results for: math_operations_in_tight_for_loop_reduction_tree_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 47.468 48.073 0.99 (OK) ================================================================================ Executing test: spin_between_run_calls... Reference binary: ./runtasks_ref_linux Results for: spin_between_run_calls STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 300.939 311.881 0.96 (OK) ================================================================================ Executing test: spin_between_run_calls_async... Reference binary: ./runtasks_ref_linux Results for: spin_between_run_calls_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 302.373 315.376 0.96 (OK) ================================================================================ Executing test: mandelbrot_chunked... Reference binary: ./runtasks_ref_linux Results for: mandelbrot_chunked STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 45.19 45.303 1.00 (OK) ================================================================================ Executing test: mandelbrot_chunked_async... Reference binary: ./runtasks_ref_linux Results for: mandelbrot_chunked_async STUDENT REFERENCE PERF? [Parallel + Thread Pool + Sleep] 45.8 44.917 1.02 (OK) ================================================================================ Overall performance results [Parallel + Thread Pool + Sleep] : All passed Perf