
An OpenMP Runtime for Transparent Work Sharing across Cache-Incoherent Heterogeneous Nodes
An OpenMP Runtime for Transparent Work Sharing across Cache-Incoherent Heterogeneous Nodes
Key Words: Heterogeneous systems,Heterogeneous-ISA CPUs,OpenMP, work sharing
1.INTRODUCTION
本文考虑的系统是一种异构系统,每个CPU有自己的物理存储和ISA,这些CPU之间没有缓存一致性,因此软件上的内存一致性以及数据的移动是必须要考虑的问题,并且数据必须使用通用的格式或动态转换。传统的编程模型如MPI不能很好的处理复杂的数据处理和动态转换,且需要手动管理存储一致性和工作分配,因此不适合异构服务器。
近期出现了一些使用分布式共享存储(DSM)的异构系统(Popcorn Linux),提供透明的跨节点的数据处理,这样异构系统的并行计算就可以在此基础上完成。
对于紧密耦合的异构系统,挑战在于如何分配并行工作,以平衡CPU性能及DSM通信开销。
作者实现的libHetMP是基于OpenMP的,但可以自动完成合适的工作分配,而开发者可以按照OpenMP的方式去编写并行程序。
libHetMP 包含了一个新的 HetProbe 循环迭代调度器,针对的是每次循环计算量相同的循环迭代计算。分析了一小部分初始循环迭代的行为,并确定剩余的迭代是否应该在多个节点上执行。如果跨节点执行有利,那么 HetProbe 调度器根据每个 CPU 的相对性能分配工作给线程。如果跨节点的工作共享导致了太多的通信,那么 HetProbe 调度器就在一组最适合给定计算的缓存一致的同构 CPU 上执行所有的工作。分配工作的复杂过程由 libHetMP 透明地自动化。
如果循环中计算是不规则的,预测执行行为就会更加困难,为了处理不规则的工作负载,libHetMP 包含了一个 HetProbe 调度器的扩展,称为 HetProbe-I。HetProbe-I 通过将一个工作共享区域逻辑地分成多个较小的工作共享区域来处理不规则的计算内核,每个区域都有自己的探测和工作负载分配决策。
作者使用OpenMP 基准测试套件的一些benchmark来评估libHetMP,在不对称CPU 上得到几何平均 41% 的加速比。而HetProbe-I 的评估表明,它可以通过触发周期性的分配决策进一步提高不规则计算的加速,某些情况下高达 24%。
2.BACKGROUND
OpenMP
OpenMP是常用于并行计算的编程模型,针对的是共享内存系统。只需要在程序中添加指导语句,编译器会创建线程,分配并行任务并提供同步能力。最常用的就是通过pragma omp for将循环迭代分配给线程完成。
1 | int vecsum ( const int ∗ vec , size_t num) { |
OpenMP不适用于异构ISA的CPU,因此系统软件(编译器和OS)需要提供共享内存的抽象,并且并行工作的分配也需要重新设计。
以下是现有的工作怎样实现跨异构ISACPU执行程序的方式,假定节点是单ISA的具有缓存一致性的处理器。
Heterogeneous-ISA Execution
想要将不对称的处理器结合在一起必须集成不同ISA的CPU,系统软件必须处理ISA的异构性和内存一致性。以往有一些工作实现了在运行时将编译好的共享内存应用程序在异构ISA的CPU之间迁移的系统软件,但作者使用的是Popcorn Linux作为系统软件,因为Popcorn Linux是可用的。其他的一些工作关注GPU/CPU的交互,但作者的工作关注的是通用计算应用。
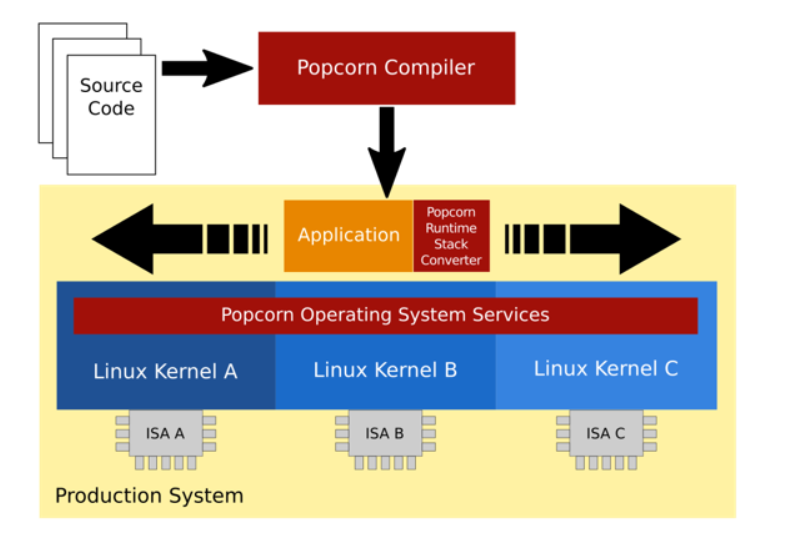
Popcorn Linux. Popcorn Linux1是一个基于Linux内核的软件栈,它可以让应用程序在分布式的主机上执行,而且可以在运行时在不同的主机之间迁移。Popcorn Linux可以支持不同ISA的主机,例如x86和ARM。可以作为模块加载到不同的Linux发行版上。 ↩
Multi-ISA Binaries
Popcorn Linux的编译器会构建能够跨ISA执行的多ISA二进制文件。多ISA二进制文件由一个对齐的数据段和多个每个ISA的代码段组成。编译器安排程序的全局地址空间在不同ISA之间对齐,使全局数据和函数都有相同的地址。编译器也会生成描述函数栈的数据,在等价点重建栈帧。
等价点. 是指在应用程序执行过程中,可以在不同ISA的CPU之间切换的点。等价点通常是函数的入口或者出口,因为这时候栈帧是完整的,而且没有任何寄存器的依赖。 ↩
Thread Migration
线程在迁移点时在节点之间迁移,迁移点是等价点的子集。libHetMP在OpenMP运行时内部添加了迁移点,以自动地在节点之间分配线程。为了在节点之间迁移,线程需要进入一个状态转换的过程,这个过程会检查线程的栈,并把它转换成目标节点的指令集架构(ISA)的格式。转换完成后,线程会把一个转换后的寄存器集合传递给一个系统调用,然后在目标节点的CPU上继续执行。
Page-level Distributed Shared Memory
一旦线程迁移到新的节点,它们就必须能够访问应用程序数据。操作系统级的DSM,如Kerrighed2和Popcorn Linux,通过在页故障处理中观察远程内存访问,并根据类似于缓存一致性协议的方式迁移数据页。通过仔细地操作页权限,操作系统强制应用程序在访问远程数据时发生故障。当发生故障时,源节点(即发生故障的节点)的内核从当前拥有该页的远程节点请求该页。该页从远程节点传输到源节点,并映射到应用程序的地址空间。内存访问重新开始,应用程序线程不知道数据是远程获取的,数据在节点之间透明地和按需地进行调度。
Kerrighed. 单系统映像集群软件项目,实现针对高性能计算的操作系统,扩展了Linux的模块。Kerrighed支持多线程和基于消息传递的应用程序,并提供分布式共享内存,进程迁移和检查点等功能。 ↩
Cross-node Execution Challenges
比起传统的共享内存多处理器系统,DSM共享数据的粒度更大,以页面粒度共享数据,并且数据管理的成本远高于传统的内存访问,页面迁移需要几十微秒。由于这两个特点,不同节点上的线程访问的数据应该以页面进行划分,并且需要有足够的计算来摊销DSM成本。
Irregular workloads
不是所有循环在迭代中都有相同的行为,在内存访问模式,功能单元的压力等方面可能都有不同。这些被称为不规则的工作负载。对于这样的工作负载,静态分配可能是有问题的。
OpenMP是可以进行动态负载分配的,但是DSM系统的通信开销和内存一致性协议,以及异构ISA的二进制不兼容性会导致动态工作分配的正确性。
3.DESIGN
libHetMP基于Popcorn Linux,自动确定在异构系统中将并行计算放在哪里,以最大化性能。libHetMP在OpenMP的基础上加入了两个组件:
- 在异构ISA CPU之间执行并行化计算需要的机制,包括线程迁移到不同的节点,以及并行工作分配给线程的机制。
- 新的循环迭代调度器,分析 CPU 之间的互连上的 DSM 活动和性能计数器,自动化工作分配决策。
3.1 扩展OpenMP
libHetMP在启动程序时会查询系统,确定节点的特征(可用CPU的类型和数量),在启动线程时插入迁移点,在线程迁移分配后,将运行时的工作(性能监控,同步,工作分配)分为节点和全局操作。libHetMP会把线程组织成层次结构以减少DSM流量,并使用层次结构进行工作分配,规约,同步,以及初始化每个节点的数据结构,如循环迭代调度器元数据,barrier。每个节点选择一个线程领导者,由该领导者处理节点的同步和规约等操作。
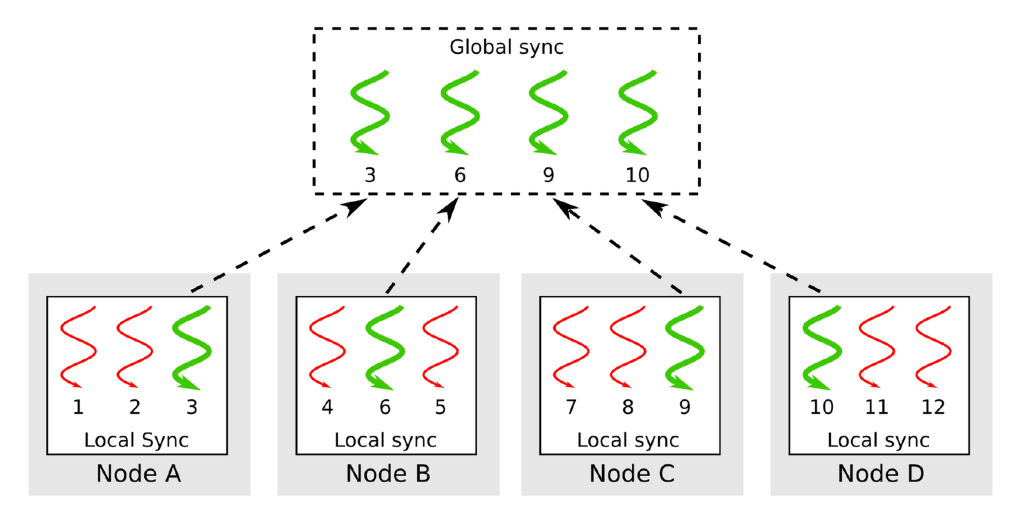
libHetMP在OpenMP已有的循环迭代调度器的基础上进行扩展,并引入了HetProb调度器。假设每个节点包含一组具有相同微架构和缓存一致性的CPU核。为了量化性能差异,libHetMP定义了一个核速度比(CSR),例如与ThnderX核相比,Xeon核有3:1的核速度比,则Xeon被认为是ThunderX计算速度三倍,将获得ThunderX线程的3倍的循环迭代。CSR是针对每个工作共享区域的。
对于OpenMP的各个调度器,libHetMP进行了扩展。静态调度器扩展后允许开发者指定每个节点的CSR,但是手动配置理想的CSR难度很大。动态调度器原本是由线程不断地从工作池中抓取用户定义的批量迭代,并使用原子操作。扩展后基于层次结构,线程首先从节点本地工作抓取迭代,如果本地池为空,该线程作为领导者将批量迭代从全局池转移到节点池。但是不停地抓取工作批量会对性能产生负面影响,并且循环迭代到线程的非确定性映射可能导致DSM中的抖动。
DSM中的抖动. 对于多次执行相同工作共享区域的程序,如果映射是确定的,数据可能在第一次调用后稳定,因为节点获取了适当的页面,反之则会产生抖动。 ↩
综上,扩展OpenMP的调度器的问题是需要找到最佳的工作负载分配配置,包括每个新的异构平台的CSR或批量大小,还要考虑到DSM开销。
3.2 HetProbe调度器
3.2.1 HetProbe和HetProbe-I
HetProbe调度器可以像其他调度方式一样通过schedule子句指定。该调度器会先在所有节点执行一小部分迭代,这个期间为探测期,衡量各个节点的单核执行时间,跨节点的页错误处理。由于Hetprobe是针对有相同行为的迭代的,因此用循环迭代本身就可以探测。
此外libHetMP还实现了一个probe cache,这样对于执行同一个工作共享区域多次的程序,可以避免多次探测,而且会使探测结果更加平滑,采用指数加权平均来处理测量数据,这样不准确的测量值会被快速修正。因为一开始执行时DSM可能需要跨节点复制数据,而此后的可能少一些,所以采用这种方式更准确。
HetProbe的扩展HetProbe-I用于处理不规则的工作负载,HetProbe-I会触发一个新的探测期来适应不规则的工作负载,使用新探测期的性能指标来计算新的CSR,并重新分配工作。
下图说明了HetProbe-I的一个调度过程,有100个迭代,而初始探测已经完成。在第一次分配后,经过一定数量的迭代后,进入新的探测期,探测结束后,剩余的迭代被合并,生成新的工作队列(称为Jump)。调度器会确保执行过的迭代不会再次被执行。
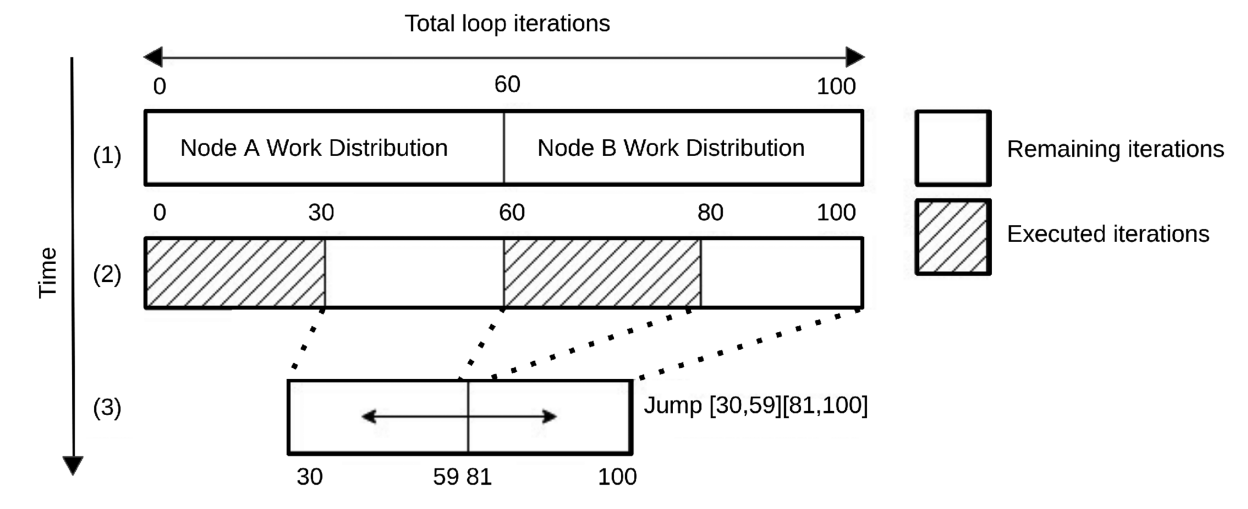
在这个过程中,有两个问题要解决:
- 在什么情况触发重新探测。频繁的重新探测能带来更细粒度的工作分配,但会影响性能。
- 重新探测时,必须重新确认未完成的迭代并放入全局工作。
对于第一个问题,HetProbe-I将在初次探测后只分配一部分迭代,当线程下一次获取迭代时,HetProbe-I检查是否重新进行探测。目前HetProbe-I会在用户定义的百分比迭代后触发重新探测,默认比例为10%(所有线程的完成的迭代达到分配出去的所有迭代的10%,每个线程完成部分迭代后,会重新获取迭代,更新已完成的迭代数)。在执行过程中,将按这个比例反复进行重新探测。例如有100000个迭代,初次探测已经完成,按照测量的CSR进行分配,每次只分给节点一部分,节点完成后再获取一部分,此时更新全局已完成的迭代数,达到1000个时触发重新探测。10%这个值作者没有给出选定原因。
对于第二个问题,HetProbe-I会通过barrier等待所有节点完成此前的迭代计算,然后将所有节点的工作重新整理得到待完成的工作,再进行分配。
3.2.2 负载分配机制
HetProbe调度器使用测量的执行时间,页错误和性能计数器来确定调度决策。解决的问题主要有三个。
1.运行时是否应该利用多个节点进行并行执行?
由于数据处理和跨节点的存储一致性的代价,不是所有情况下程序都能从跨节点执行中受益。作者使用了一个测试观察DSM的开销,实验设置如下图:
而系统使用的协议采用两种,TCP/IP和RDMA。测试为每个节点的每个核心建立一个线程,然后运行一个循环,主线程运行在源节点Xeon上,源节点访问所有的页面,这样就强制DSM将所有页面带回源节点的内存,模拟了应用程序的初始状态。接下来其他节点的线程开始计时执行,每个ThunderX线程访问不同页面,强制DSM将页面传输到ThunderX内存,模拟数据访问。计算结束后,测试程序计算循环需要的时间,计算每秒的操作数,评估DSM的开销和跨节点执行的效率。以下两图显示了测试结果,两图的横坐标均为compute operation per byte of data transferred,即完成1byte字节传输时间内的计算操作,横坐标越大,计算越多。(TCP/IP需要更多计算摊销DSM)。
RDMA. 远程内存直接访问技术。核心技术是零拷贝,内核旁路,协议卸载。零拷贝:HCA(网卡)可以直接与应用内存传输数据。内核旁路:执行RDMA请求不需要执行内核调用,可直接向网卡发送命令。协议卸载:网卡硬件中部署可靠的传输协议。 ↩
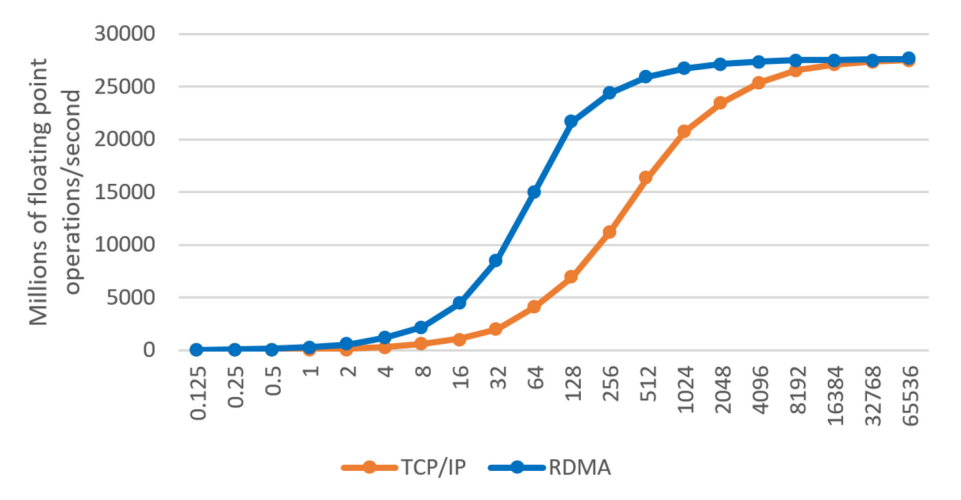
从这张图可以看出,RDMA的延迟要小于TCP/IP,即TCP/IP需要更多计算才能摊销DSM。
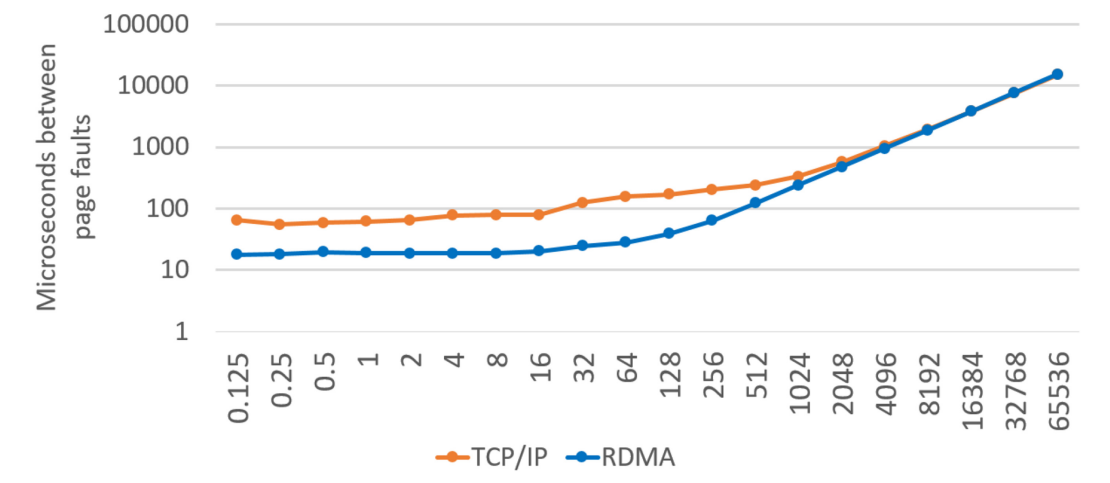
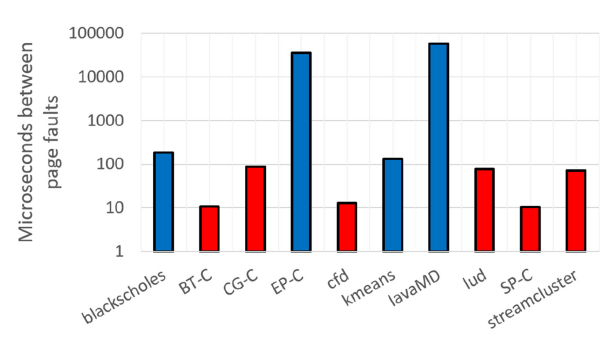
这张图则体现了处理页错误的时间,纵坐标为一个计算周期中,触发页错误的间隔时间,RDMA处理页错误的间隔时间更短,因为RDMA的访存延迟更低。
从以上两图可以看出跨节点执行是否有益的临界点,对于RDMA,从第一张图可以看出每字节传输时操作超过512后性能变化不大,提升到足够高,因此对应第二张图作者将阈值设置为100,只要测量的页错误间隔大于100,就可以跨节点执行,TCP/IP也是类似的。如果这个时间太小,就说明跨节点执行的开销太大,页错误的时间难以摊销。以上的这个测试可以作为一个工具重复使用,以自动确定跨节点执行变得有益的阈值。
2.如果利用跨节点执行,那么应该将多少工作分配给每个节点?
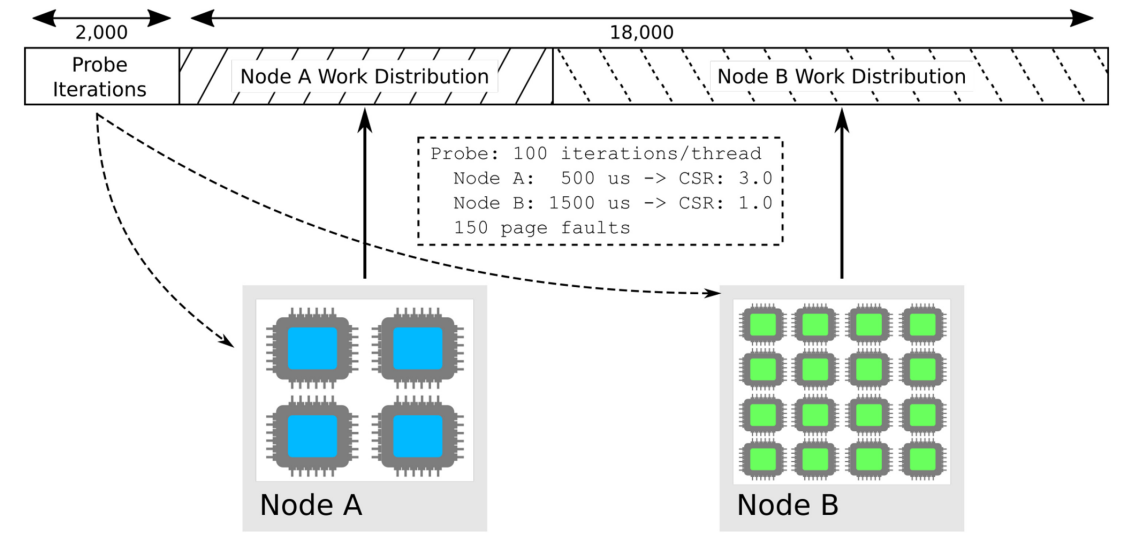
如前述,使用测量的CSR来分配工作。
3.如果不使用跨节点执行,该使用哪个节点执行?
这个问题的解决需要依赖在探测期测量的性能,在测量期间会使用硬件性能计数器,根据结果和程序计算特点来决定。例如上述例子,Xeon有更大的核心和缓存,而ThunderX有更多的核心以及两倍于Xeon的带宽,但只有简单的两级缓存,如果程序有非常多的缓存未命中,则可能无法利用ThunderX的多核心。HetProbe调度器在探测期间测量的是缓存未命中率,据此设定阈值(每千条指令三次缓存未命中,这是一个实验值)来确定使用Xeon还是ThunderX,用户也可以指定其他性能计数器。HetProbe调度器必须使用性能计数器,不能简单地使用探测期间的执行时间来决定一个节点,探测期间测量的执行时间包含了在单个节点上执行时不存在的DSM开销。
一旦选择了一个节点,调度器就回退到OpenMP调度器,进行单节点进行工作分配。并且确定单节点工作后,可以把多余的线程结束掉。
3.2.3 实现
在HetProbe调度器中,线程在三个场合调用libHetMP。在第一次调用运行时,HetProbe分配了用于探测的迭代。在第二次,HetProbe存储性能指标,并计算CSR来在节点之间分配工作。在最后一次调用中,HetProbe利用动态调度器来分配之前计算出的分配中的剩余迭代。在HetProbe-I中,通过检查是否满足重新探测的条件,在必要时重新探测。因为HetProbe-I需要线程定期调用这个函数,所以它只分配了它们应该根据它们的CSR接收的迭代的一部分,每次迭代分配较小的块,其块大小与计算出的速度比成正比。例如,如果一个节点应该有0到30的迭代,那么HetProbe-I将这些注册为真实的下一个和结束,并在第一次调用运行时时分配0到5的迭代,在下一次时分配5到10,依此类推,直到任何一个线程获取迭代时,整体完成数量达到了阈值(10%)。
HetProbe-I在需要重新探测时可能面临三种潜在的情况:
- 只有一个节点在执行工作。触发重新探测期间的线程属于唯一一个被HetProbe分配了迭代的节点——根据探测期间收集的指标,跨节点执行被认为是不有益的。如果没有分配工作,那么不执行迭代的节点的领导线程将被停止,阻塞该节点上的所有线程,停滞在一个层次化的barrier中。因此,每当在这些情况下触发重新探测时,HetProbe-I只需要恢复在非活动节点上的执行,并分配探测迭代。让停止的领导线程在一个全局变量上旋转是不昂贵的,因为该节点没有执行任何其他工作。
- 所有节点上都有工作在运行。因为有跨多个节点的工作在执行,触发重新探测的线程属于一个有一部分迭代的节点。这个节点的领导线程将不得不等待其他节点完成工作。
- 一个节点没有剩余的迭代。HetProbe-I也必须考虑到这种不太常见的情况,即即使没有触发重新探测,节点也耗尽了工作。HetProbe-I停止那些耗尽了工作的线程,等待其他节点完成工作。
一旦触发重新探测,HetProbe-I都必须重新开始性能统计,并生成新的全局工作队列。为了防止重复执行已经完成的工作,HetProbe-I必须为线程提供连续的迭代范围。当HetProbe-I生成一个新的工作队列,迭代可能是不连续的,HetProbe-I需要考虑跳转来给线程标记和分配工作。 当分配给线程的工作在分配函数中包含一个跳转时,第一半被分配,线程被标记,以便在下一次调用函数时接收另一半。第二部分也可能包含跳转,所以这个过程可能会重复几次,在最坏的情况下会有非常多次。
4.EVALUATION
4.1对HetProbe的评估及结果分析
对libHetMP的评估主要关注以下问题:
- 能否有效利用非对称的异构平台的计算能力
- 能否准确测量运行时行为并作出合理的负载分配决策
- 各调度器最适合什么类型的运行时行为
实验平台为一个Xeon服务器和一个ThunderX服务器组成的异构平台,通过InfiniBand进行连接,提供低延迟和高吞吐量。两台机器都运行Popcorn Linux。选择了十个基准测试,每个测试采用三次运行的平均值。
用于评估的工作负载配置有以下几种:
- Xeon:Xeon单节点执行
- ThunderX:ThunderX单节点执行
- 理想CSR:收集调度器运行时的CSR,作为环境变量手动提供,使用扩展的静态调度器,在两个节点并行执行
- 跨节点动态执行:使用扩展的动态调度器
- HetProbeMP:使用HetProbeMP调度器执行,探测期间使用10%的循环迭代
- HetProbeMP(Xeon):使用HetProbe调度器但强制在Xeon上单节点执行
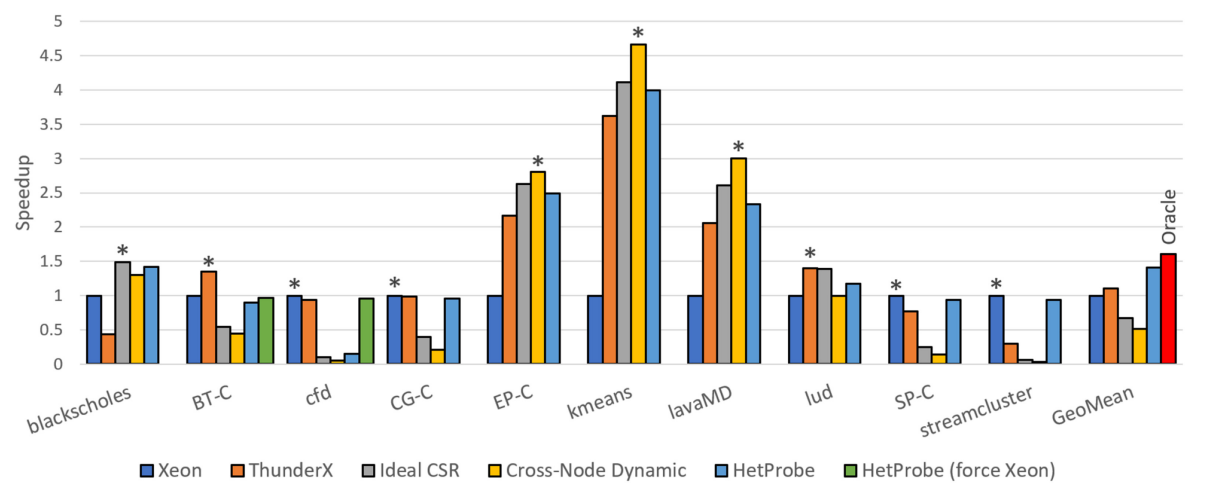
基准测试可以分为两类,blackscholes、EP-C、kmeans和lavaMD可以从跨节点执行中受益,而其他的则不受益。而在这些测试当中,动态跨节点执行都获得了最高的加速比,这是因为测试采用的块为细粒度,工作在节点之间几乎完美地平衡分配,并且由于线程层次结构,全局同步较少。在这四个基准测试当中,跨节点动态的执行平均加速比为2.68x,其次是理想CSR,加速比为2.55x,HetProbMP由于探测期间的开销,加速比为2.4x,低于前两种。理想CSR和HetProbe之间的差值就是探测的开销,这个开销平均为5.5%,表明HetProbe调度器提供了竞争力的性能和很小的开销。
对于无法从跨节点执行受益的基准测试,理想CSR和跨节点动态执行会显著降低性能,因为DSM的开销过大,计算不足以摊销DSM页错误的成本。而HetProbe调度器通过测量页错误触发间隔时间判断跨节点执行不利,成功地避免了这些基准测试的跨节点执行。下图中,如第3节提到的,阈值为100微秒,小于100微秒的不适合跨节点执行。
不适合跨节点执行的测试,HetProbe根据每1000条指令的缓存缺失来确定是在Xeon还是ThunderX上执行工作共享区域,对于测试,以每千条指令3次缺失为阈值,将BT-C,cfd和lud放在ThunderX上,其他的放在Xeon上执行。对于这些测试,直接在单节点执行和HetProbe之间的差值就是探测开销,对于放在Xeon上的三个基准测试,平均开销为6.1%,开销很小。而ThunderX上的测试有特殊的行为。

cfd和CG-C在Xeon和ThunderX上的性能大致相同,但在缓存缺失上有很大的不同。并且cfd在Xeon上更快。这是因为cfd的并行部分在ThunderX上更快,但有一个长的串行I/O阶段,在Xeon上更快(1.83s,在ThunderX上是13.72s),因此总体时间在Xeon更快。
对于BT-C、cfd和lud,由于操作系统的限制,在ThunderX上执行并行区域的性能比预期的差。Popcorn Linux的内核目前只支持在应用程序启动的节点上产生线程,即使在工作共享区域在ThunderX上执行时,也必须有一个线程保留在Xeon上。这些基准测试执行了数百到数千个工作共享区域,导致了大量的跨节点同步。因此测试了强制在Xeon上单节点执行,探测开销很小。
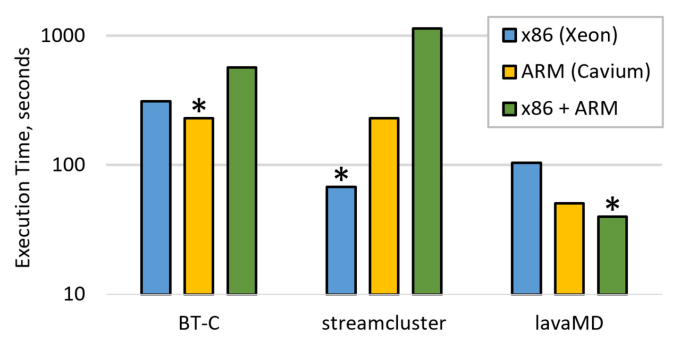
没有任何一种负载分配在所有情况下是最好的,这说明了HetProbe的必要性,在所有的基准测试中提供了平均41%的性能提高,高于其他所有分配方式(ThunderX提供11%)。理想情况下,如果开发者对所有的配置进行了广泛的分析,并为所有的基准测试选择了最佳的配置,那么可以获得60%的平均加速比。
从跨节点执行中受益的四个应用程序都有足够高的计算与跨节点通信的比例,而适合单节点执行的测试无法摊销数据传输的成本。例如,BT-C和SP-C在连续的工作共享区域中沿着不同的维度访问多维数组,导致DSM在节点之间移动大量的数据。以及大量的伪共享问题。作者也对其他几个基准测试的计算进行了一些分析。都存在各自的无法摊销DSM开销的原因。
4.2 对 HetProbe-I的评估
作者加入了一个新的基准测试,接收工作负载的不规则程度作为参数,合并streamcluster和BT-C的源代码(分别在Xeon和ThunderX上有最佳性能),来评估HetProbe。新的基准测试将两个基准测试的迭代混合,60%的不规则程度表示10个迭代中有6个是streamcluster的调用。当不规则程度较小时,由于重新探测的开销,HetProbe-I的性能不如HetProbe,但当不规则程度大于50时,HetProbe-I的性能就超过了HetProbe。
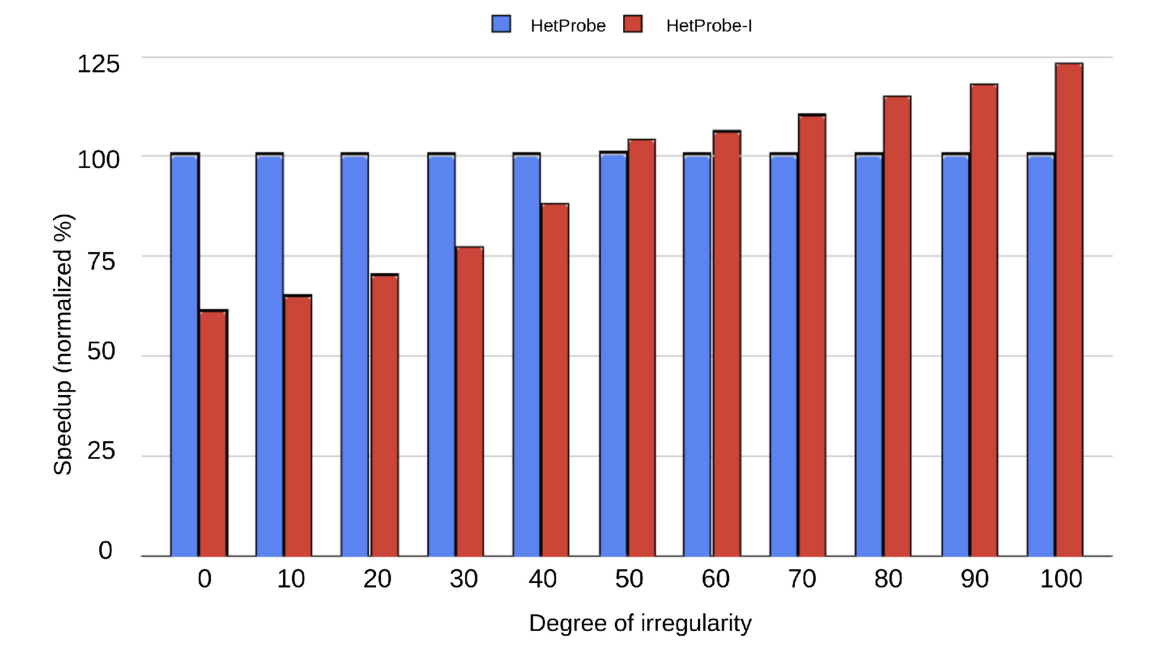
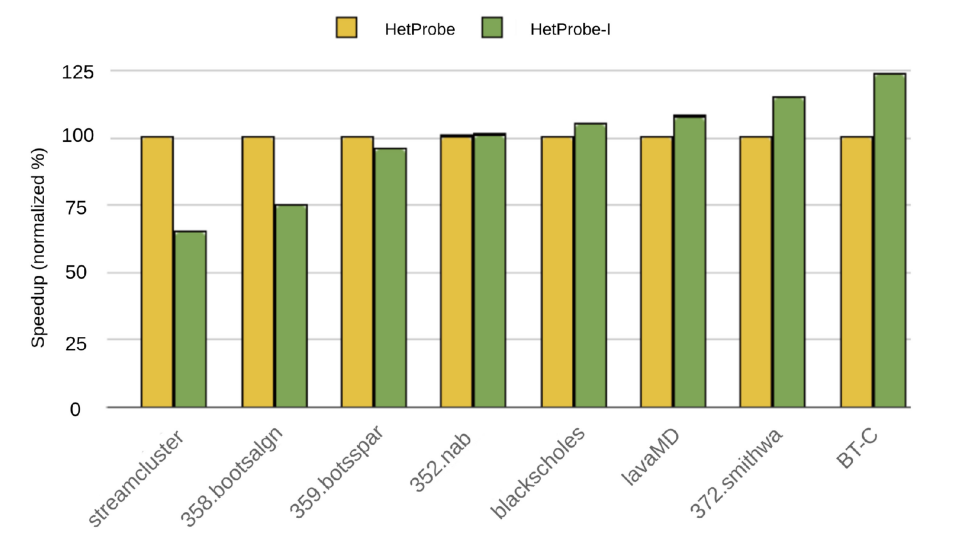
对各个基准测试(包括新加入的一些SPEC基准测试)的结果如下图,对于比较规则的工作(streamcluster),重新探测的开销导致了性能的下降,但对于不规则的工作,HetProbe-I的性能更好,并且对于这些工作,HetProbe-I的性能比Cross-Node Dynamic还要好。因为重新探测的开销没有那么大,而动态调度中线程补充迭代的开销更大。整体来说,HetProbe-I在包含高度不规则性的工作共享区域中表现出色。
SPEC. Standard Performance Evaluation Corporation,为不同类型的计算机系统提供公平、可靠和可重复的性能测试方法,以帮助用户和开发者选择和优化合适的硬件和软件配置 ↩
4.3 局限性
libHetMP还有许多可以扩展的地方。HetProbe-I的一种替代方案是在工作共享区域内持续监测页面错误,如果页面错误的数量开始上升,就回退到单节点执行。反之可以在另外一个节点启动额外的线程。
此外,libHetMP目前也只关注实现最大的性能,而不是能效。第一代ThunderX CPU消耗大量的电力,跨节点执行提供最好的性能,但能耗更大。
HetProbe-I的潜在性能下降方面,重新探测的行为会带来一定的开销。并且所有评估的基准测试的缓存未命中次数都有所增加。这种增加可能是因为迭代的空间局部性可能不会被下一个工作分配的节点利用。
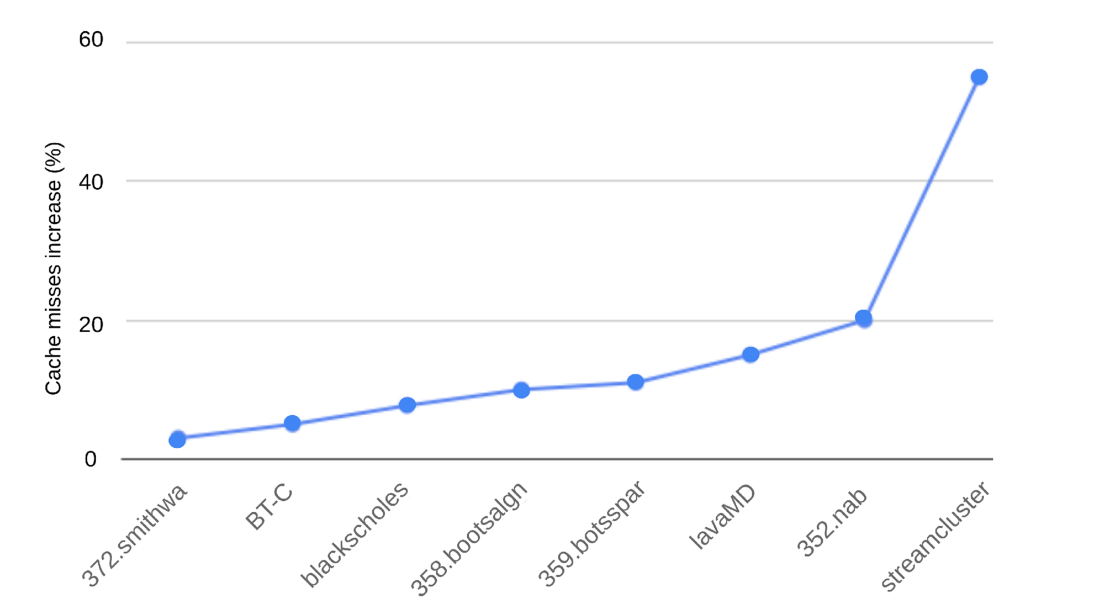
下图显示了与HetProbe相比,每个基准测试的缓存未命中次数的百分比增加。最大的增加来自streamcluster(缓存未命中次数增加了55%)与HetProbe相比,性能下降了35%。因此循环调度器在这种情况下会降低性能,对循环调度器的内存管理进行改进,可能会减轻HetProbe-I产生的开销。
5.总结
作者实现了针对使用DSM的异构平台的一个OpenMP运行时版本,提供了跨节点执行的工作分配机制。通过新的调度器,自动进行工作负载分配,包括是否跨节点执行或单节点执行,并针对不规则的工作负载设计了一个更好的版本。
作者的创新点主要在于该设计是针对异构DSM系统的,基于OpenMP实现,使开发者可以以使用OpenMP的方式实现此类平台的并行工作自动的负载分配,并且对于不规则的工作负载也有良好的效果。并使用页面错误间隔衡量是否使用跨节点执行。
作者的局限性和可改进的内容主要有:
- 只测试了两个节点的系统,没有对多节点的情况进行测试
- 只关注最大性能,还可以针对不同的效率指标来进行工作负载分配
- HetProbe-I的重新探测行为会造成一定的开销,可能增加缓存未命中次数和内存访问延迟,且重新探测的阈值的确定还有待考量。如果对循环调度器的内存管理进行改进,可能可以减轻HetProbe-I产生的开销
最后,本篇文章也启发了对缓存一致的互连系统的关注,以及相关技术例如CXL3,OpenCAPI4等,以及对异构平台的关注。
参考文献
[1]Popcorn Linux - Replicated-kernel Linux[EB/OL]. popcornlinux.org. /2023-11-29. http://popcornlinux.org/index.php/replicated-kernel-linux#:~:text=Popcorn.
[2]Kerrighed[EB/OL]. Wikipedia. 2023-07-24/2023-11-29. https://en.wikipedia.org/wiki/Kerrighed.
[3]NVLink 和 NVSwitch 互联技术[EB/OL]. NVIDIA. /2023-11-29. https://www.nvidia.cn/data-center/nvlink/.
[4]HOME[EB/OL]. Compute Express Link. https://www.computeexpresslink.org/.