
NEON编程
原书为Arm的NEON Programmer’s Guide和NEON Programmer Guide for Armv8-A。
根据我的实际体验,这份文档的帮助不大,只是对A64有个基本认识,实际上手NEON编程,可以在手册直接找相应指令,而关于A64和架构,可以阅读https://www.zhihu.com/column/c_1455195069590962177。
Chapter 1 Introduction
1.1 Data processing technologies
数据处理的常见方法有SISD,SIMD(vector mode),SIMD(packed data mode)。
vector mode
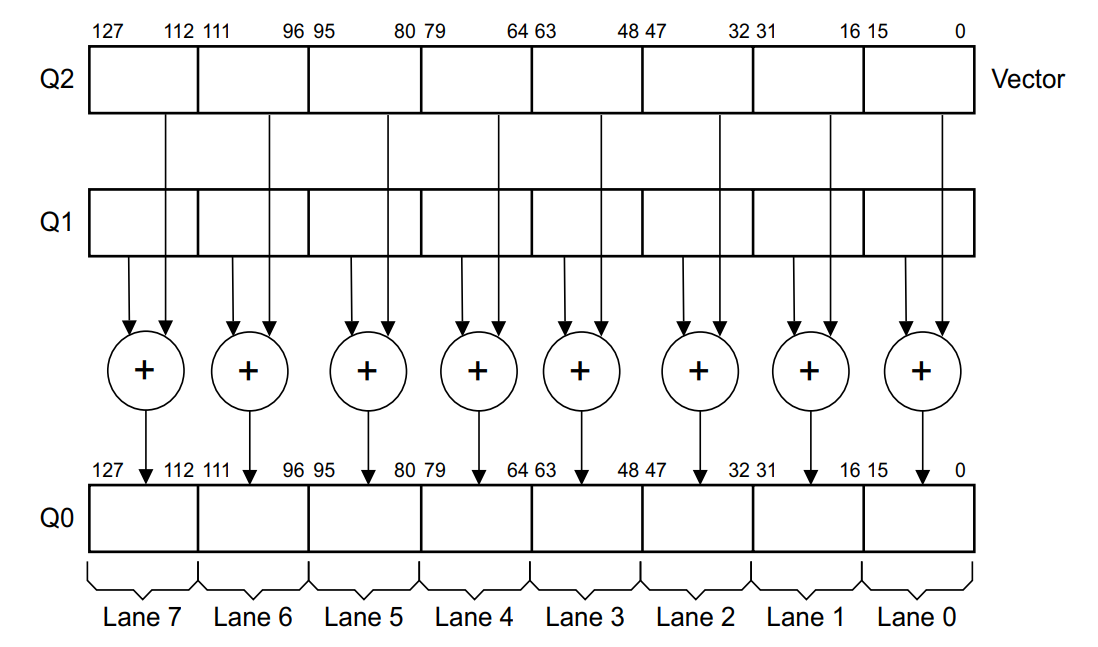
假设vector size为4,SIMD(vector)可使用单指令完成4个数据的操作:
1 | VADD.F32 S24, S8, S16 |
在ARM中,这称为Vector Floating Point(VFP),在ARMv5引入,源和目标寄存器既可以是单个寄存器也可以是多个寄存器。在ARMv7,NEON代替了VFP实现多寄存器上的操作。
packed data mode
这种模式下,一个指令可以指定一个大寄存器中的多个数据部分进行相同的处理:
1 | VADD.I16 Q10, Q8, Q9 |
在ARM中,这称为SIMD或NEON。
1.2 Comparison between ARM NEON technology and other implementations
与ARMv6中相比,ARM NEON的计算单元支持128-bit的向量操作,在ARMv6中只有32-bit的向量操作。并且在NEON中,这些寄存器是单独的,并且其向量操作是专门优化过的,而ARMv6中只是使用和其他指令相同的寄存器和流水线。
与X86的MMX/SSE的比较以及与DSP的比较这里略去了。
1.3 Architecture support for NEON technology
- 不能保证ARMv7-A或ARMv7-R处理器包含NEON或VFP技术。
- ARMv7核心的可能组合包括没有NEON或VFP单元,仅有NEON单元,仅有VFP单元或同时具有NEON和VFP单元。
- 具有NEON单元但没有VFP单元的处理器无法在硬件中执行浮点运算。
- 由于NEON SIMD操作更有效地执行矢量计算,从ARMv7引入开始,VFP矢量模式操作被弃用。
- VFP单元有时被称为浮点单元(FPU)。
- 具有NEON或VFP单元的处理器可能不支持某些扩展,如半精度和融合乘加。
- 半精度指令仅在包含半精度扩展的NEON和VFP系统上可用。
- Fused Multiply-Add (FMA)指令是对VFP和NEON的可选扩展。仅在实现了Fused Multiply-Add扩展的NEON或VFP系统上才可用。VFPv4和Advanced SIMDv2支持Fused Multiply-Add指令。
1.4 Fundamentals of NEON technology
NEON单元的组成部分包括:
- NEON寄存器文件
- NEON整数执行流水线
- NEON单精度浮点执行流水线
- NEON加载/存储和置换流水线。
NEON指令和浮点指令使用相同的寄存器文件,称为NEON和浮点寄存器文件。这与ARM核心寄存器文件不同。NEON和浮点寄存器文件是一组可被访问为32位、64位或128位寄存器的寄存器的集合。哪个寄存器可用于指令取决于它是NEON指令还是VFP指令。本文将NEON和浮点寄存器称为NEON寄存器。某些VFP和NEON指令在通用寄存器和NEON寄存器之间移动数据,或使用ARM通用寄存器来寻址内存。
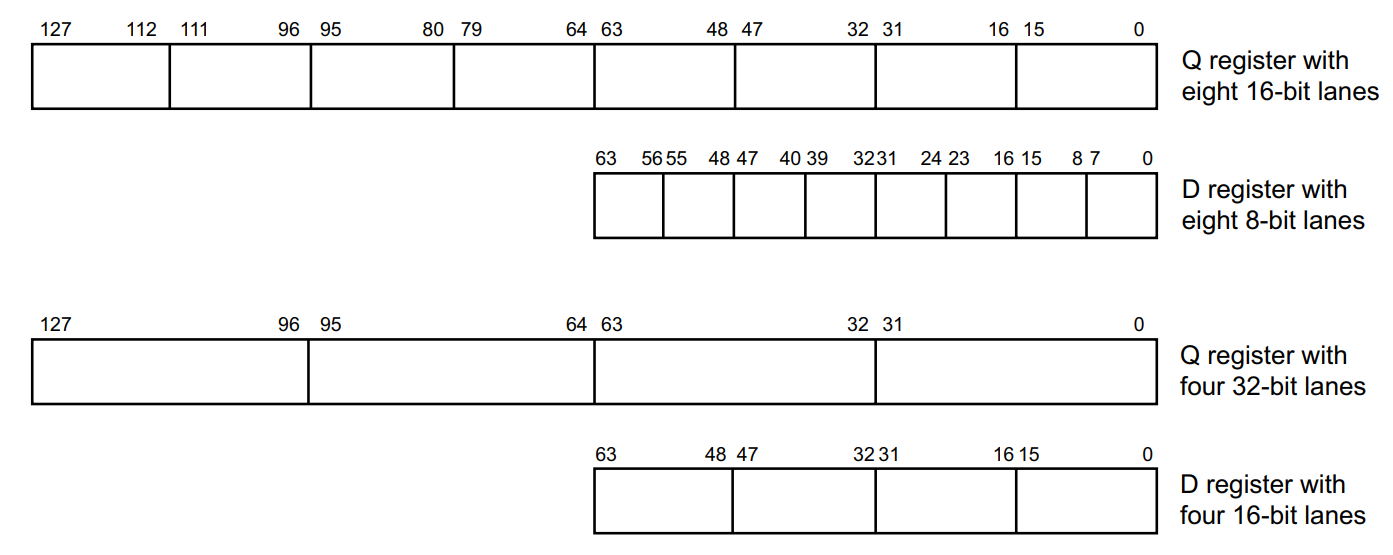
Arm v8 AArch64有32个128位寄存器,也能当作32位Sn寄存器或是64位Dn寄存器使用。
一些NEON指令会使用标量,标量可以通过下标表示。例如VMOV.8 D0[3], R3。NEON标量可以是8bit,16bit,32bit或64bit,除了乘法指令,其他指令都可以访问寄存器中的任意位标量,乘法只能访问:
- 16bit标量:D0-D7的[0-3]
- 32bit标量:D0-D15的[0-1]
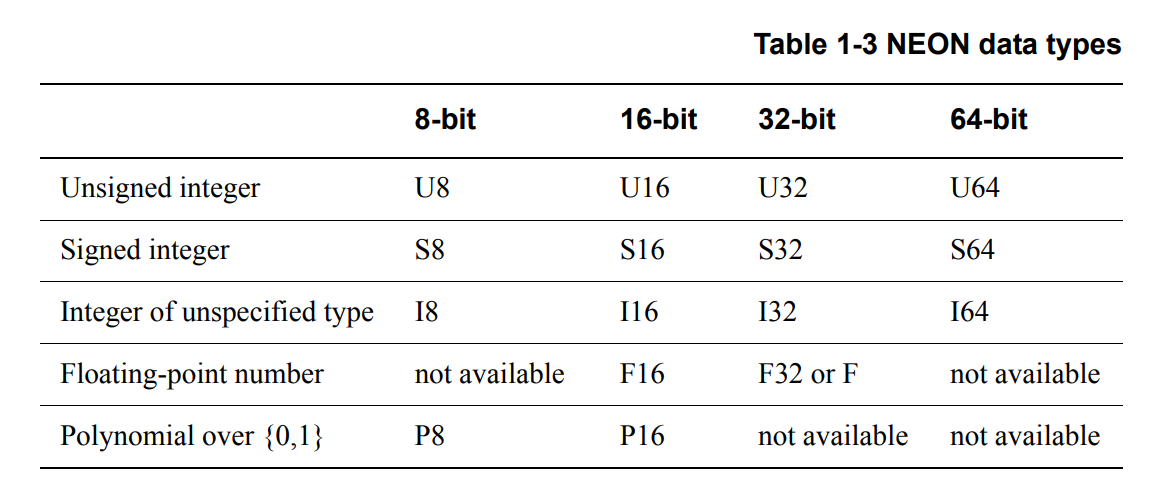
NEON中的数据类型:
Chapter 2 Compiling NEON Instructions
要使用GCC进行自动向量化,需要添加以下选项:
- -ftree-vectorize
- -mfpu=neon
- -mcpu 指定核或架构
以-O3编译相当于添加了-ftree-vectorize。
通常,如果不采用自动向量化,一般使用INTRINSIC代码嵌入C中来使用NEON。需要在头文件中包含arm_neon.h,并指定处理器类型,例如-mcpu=cortex-a72。
1 |
|
C pointer aliasing
标准C中,指针可能指向相同或重叠的数据,这给优化带来了困难。C99和C++引入了restrict关键字,用于声明指针的唯一性,从而提高编译器的优化能力。ARM编译器和GCC都支持restrict关键字,但有不同的语法和选项。
Natural types
算法使用特定数据类型有其原因,但转换为处理器自然类型可以提高运算速度和精度。
Array grouping
对于寄存器数量较少的处理器设计(如x86),通常会将多个数组合并为一个。这样可以让同一个指针的不同偏移量访问数据的不同部分。但是这种方式可能会让编译器误认为偏移量导致了数据集的重叠。除非可以保证不会对数组进行写入操作,否则请避免这样做。将复合数组拆分为单独的数组,可以简化指针的使用并消除这种风险。
Inside knowledge
NEON代码需要知道数组大小,否则编译器会生成多余的代码。数组大小可以在编译时指定,也可以根据工程师的知识进行优化。
Chapter 3 coding for NEON
3.1 Overview
这份guide包含以下内容:
- Memory operations, and how to use the flexible load and store instructions.
- Using the permutation instructions to deal with load and store leftovers.
- Using NEON to perform an example data processing task, matrix multiplication.
- Shifting operations, using the example of converting image data formats.
3.2 Load and store - example RGB conversion
本节以RGB到BGR的转换为例。在一个24bit的RGB图中,像素在内存中以R G B R G B的模式存储。假设现在要完成一个简单的图像处理,交换R和B channel。将RGB数据项按顺序从内存放入寄存器会使交换红色和蓝色通道难以操作。
以下指令将RGB data每次一字节存入NEON寄存器:
1 | LD1 { V0.16B, V1.16B, V2.16B }, [x0] |
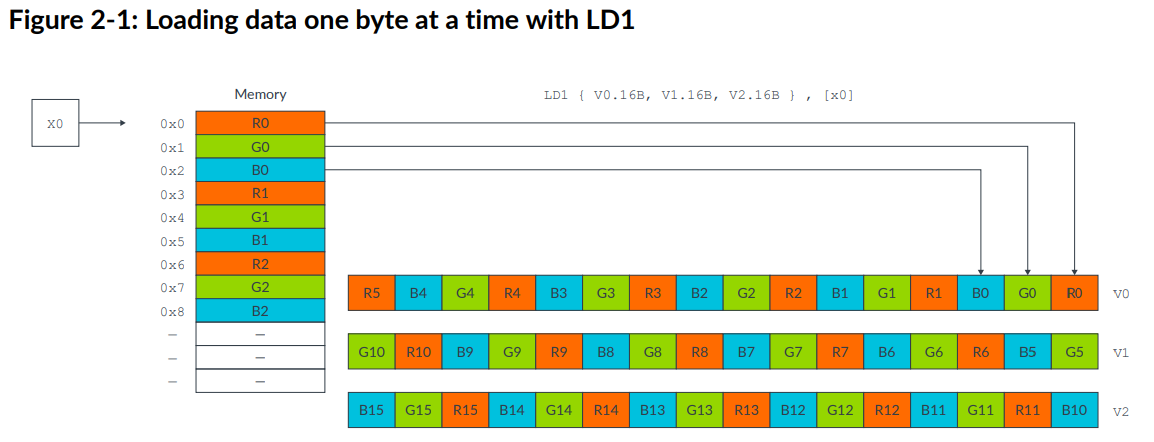
这种情况下,交换不同的Lane会比较复杂。NEON提供了结构load和store指令来应对这种情况,可以将连续的数据分别存储到不同的寄存器。在这个例子中,可以使用LD3指令:
1 | LD3 { V0.16B, V1.16B, V2.16B }, [x0] |
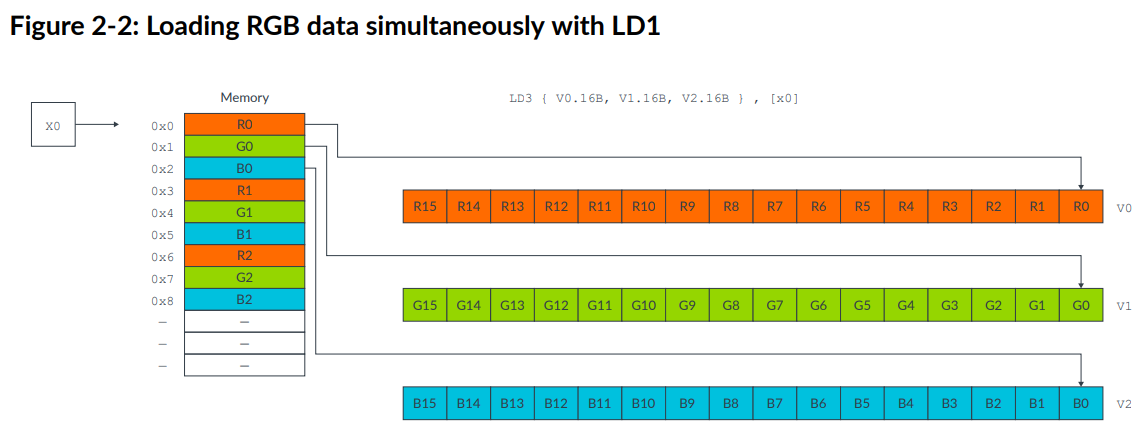
这样只需要使用MOV指令对整个Vector交换,然后使用ST3 store指令写回,完整的操作如下:
1 | LD3 { V0.16B, V1.16B, V2.16B }, [x0], #48 // 3-way interleaved load from |
每一步的操作如下:
- Loads from memory 16 red bytes into V0, 16 green bytes into V1, and 16 blue bytes into V2.
- Increments the source pointer in X0 by 48 bytes ready for the next iteration. The increment of 48 bytes is the total number of bytes that we read into all three registers, so 3 x 16 bytes in total.
- Swaps the vector of red values in V0 with the vector of blue values in V2, using V3 as an intermediary.
- Stores the data in V0, V1, and V2 to memory, starting at the address that is specified by the destination pointer in X1, and increments the pointer.
3.3 Load and store - data structures
在上一个例子中提到的指令进行的操作如下图:

指令的语法如下:
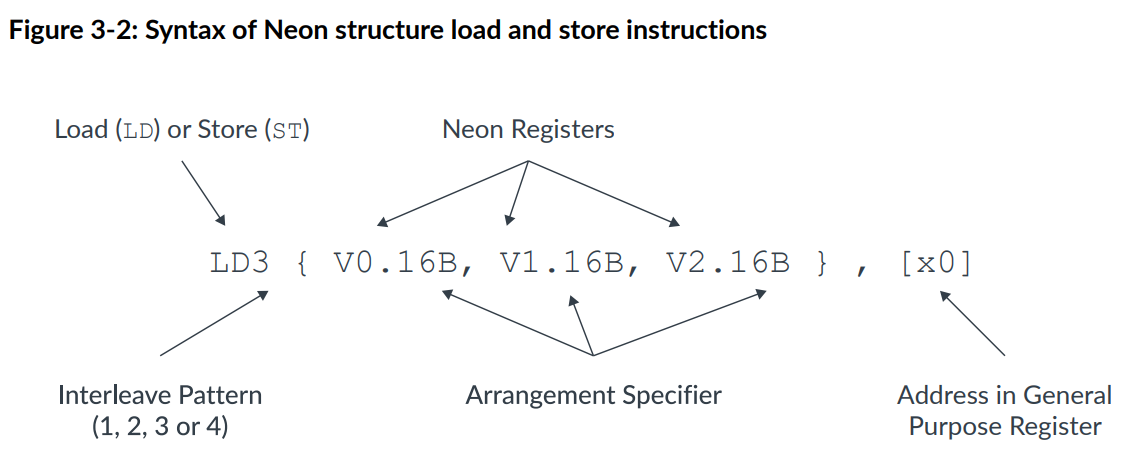
其中的Registers根据interleave pattern最多可以有四个,后面的16B表示每个数据是1B(byte),每个向量是128bit,存储16B。数据类型有8(B),16(H),32(S),64(D)bits。
以下是两个例子:
1 | LD2 {V0.8H, V1.8H}, [X0] |
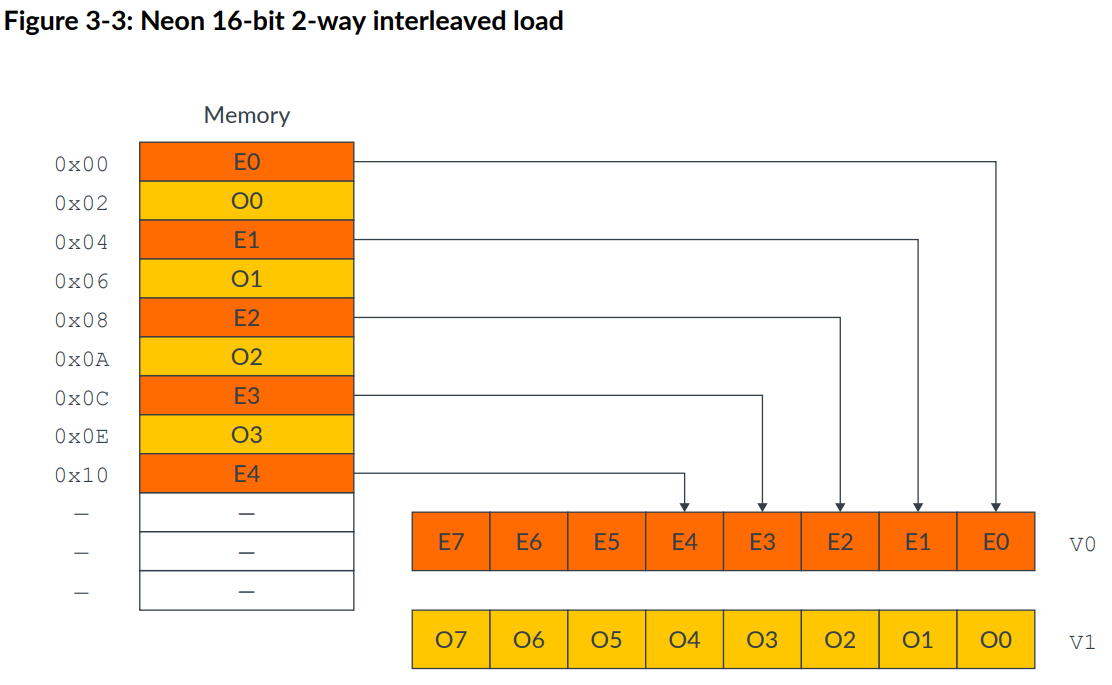
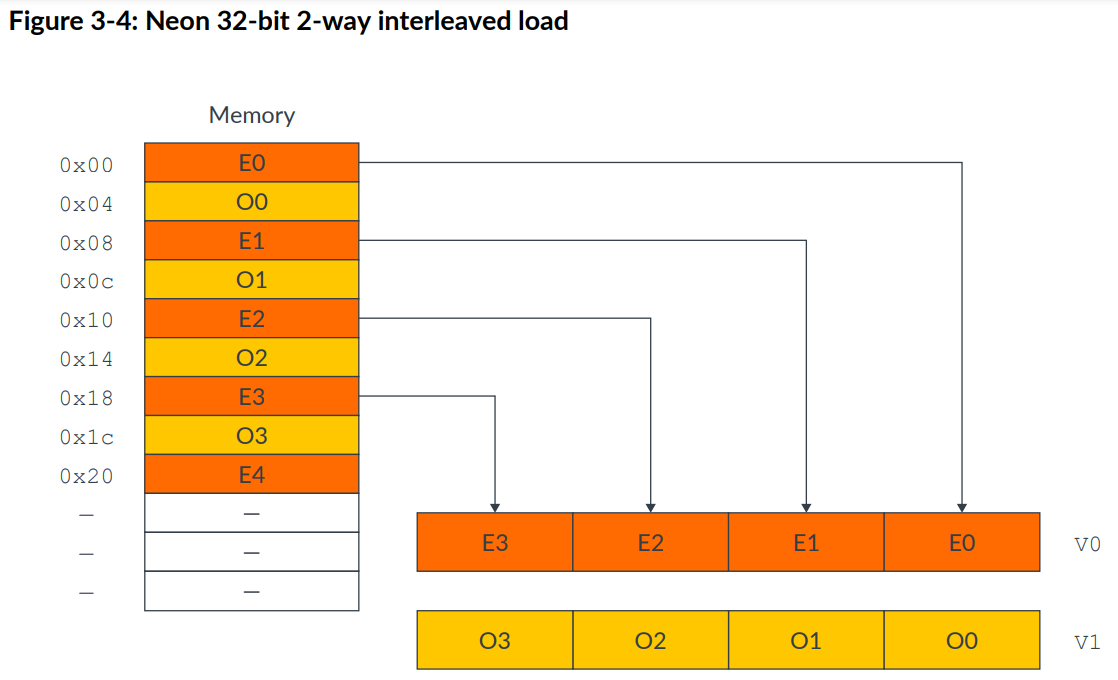
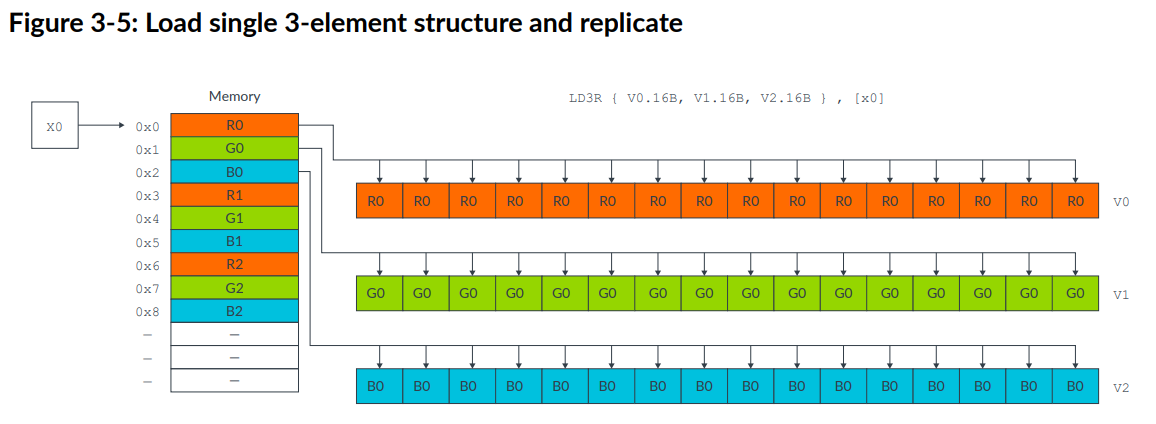
structure load还允许加载一个元素到vector的所有lane中,如下指令:
1 | LD3R { V0.16B, V1.16B, V2.16B } , [x0] |
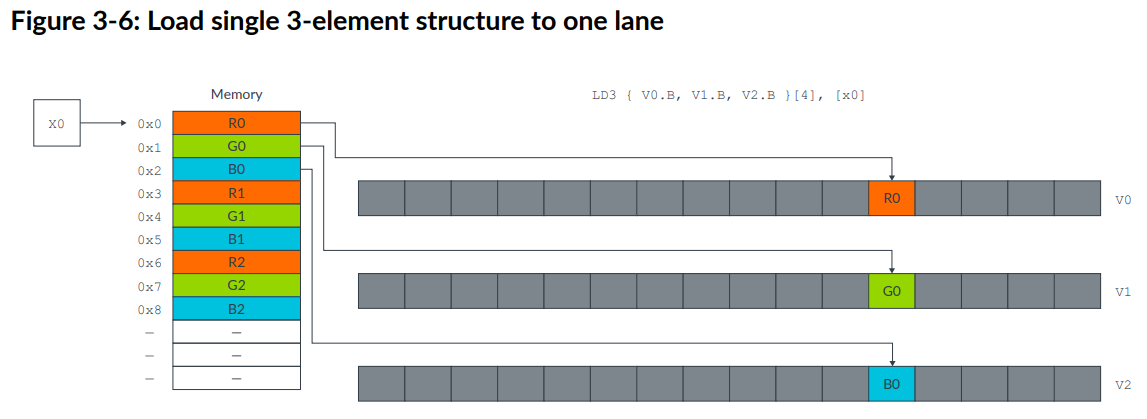
也可以只load到一个lane当中,这在从存储中获取分散的数据到vector中很有用:1
LD3 { V0.B, V1.B, V2.B }[4] , [x0]
[]可以指定地址偏移。为了方便下一次读写,指令后可以添加#imm,会直接给x0地址的值+imm。
除了上述的structure load and store,NEON也提供其他类型的LD和ST指令,详见Arm Architecture Reference Manual。
3.4 Load and store - leftovers
有时输入数据不是向量寄存器lanes的整数倍。例如一个输入数组有21个16bit的元素。NEON寄存器可以一次处理8个元素,最后一次迭代只有5个元素,这5个元素无法填满寄存器。
有三种处理这种情况的办法,需要根据情况选择:
- Extend arrays with padding
- Overlap data elements
- Process leftovers as single elements
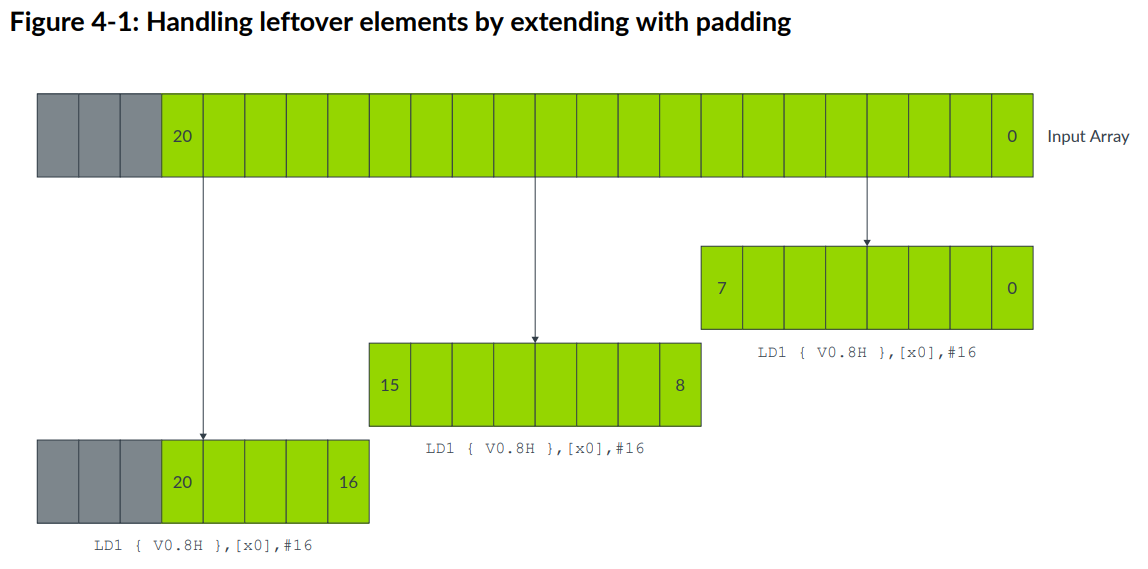
Extend arrays with padding
如果数组长度可变,可以将其填充到vector size的倍数,这样就可以在不影响其他数据的情况下进行数据读写。padding值应该不影响计算的结果。
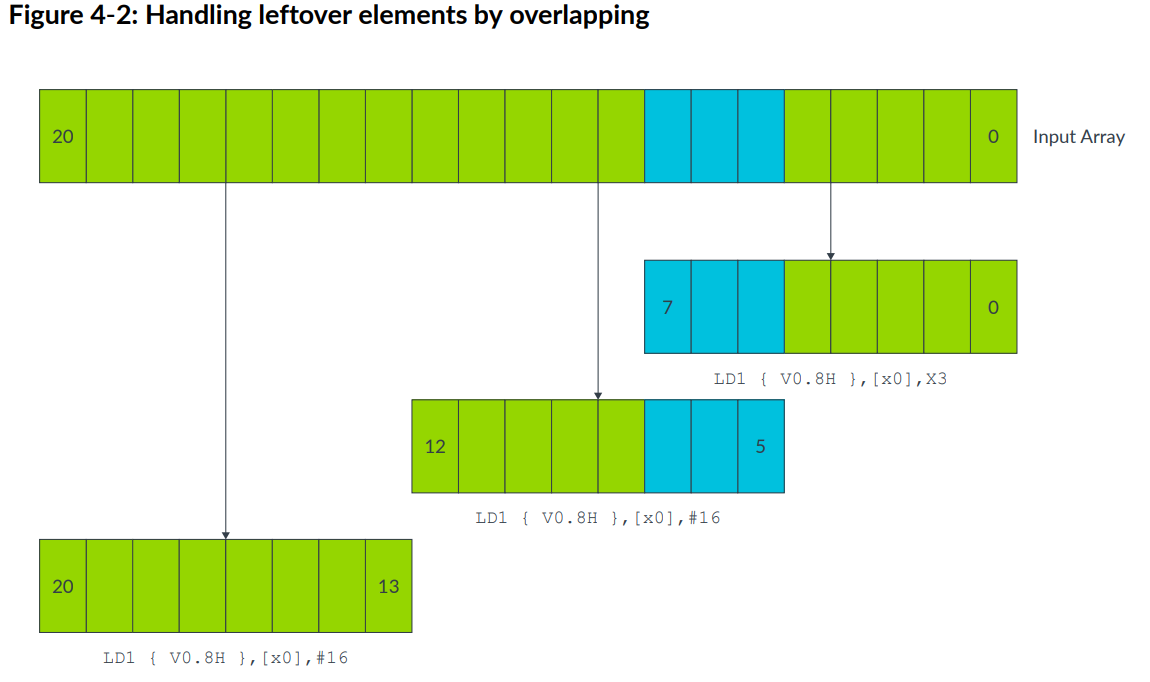
Overlap data elements
如果操作合适,可以通过重叠元素处理多出来的元素。
Process leftovers as single elements
NEON提供了可对向量中的单个元素操作的指令,最后的元素可以单独进行处理。这种方式比前两种都慢,并且会增加代码规模。
还有一些其他需要关注的点:
- 地址对齐:load and store指令的地址应该和缓存行的大小对齐,以实现更高效的访存。
- 可以使用A64的指令完成单独元素的的计算,但是要NEON和A64指令写入相同的内存,特别是相同的cache line。
3.5 Permutation - rearranging vectors
在编写SIMD程序时,数据的顺序很重要,与性能直接相关,有时数据在内存中的位置可能不合适或不是最优的。
一个解决上述问题的方法是重新安排数据。这种方式的性能开销很高。更好的办法是在数据被处理时重新安排数据,重安排被称为permutation,NEON提供了一系列permute指令,实现以下操作:
- Take input data from one or more source registers
- Rearrange the data
- Write the result of the permutation to a destination register
Permutation guidelines
- permuting data不是什么时候都有用。
- permute指令会带来开销。
- 不同的指令使用不同的pipline。最优的方法是最大化pipline的使用。因此需要尽量少使用permute操作,选择执行时会利用空闲pipline的指令。
3.6 Permutation - NEON instructions
这一节介绍的permute指令包括:
- Move
- Reverse
- Extraction
- Transpose
- Interleave
- Lookup table
这里不一一说明这些指令了,需要时再查询。
3.7 Matrix multiplication
这一节是NEON实现矩阵乘法的例子。假定矩阵按照列顺序存储(OpenGL ES的存储格式)。每次计算4*4的矩阵。

下图显示了使用NEON的FMUL指令实现向量和标量的相乘:
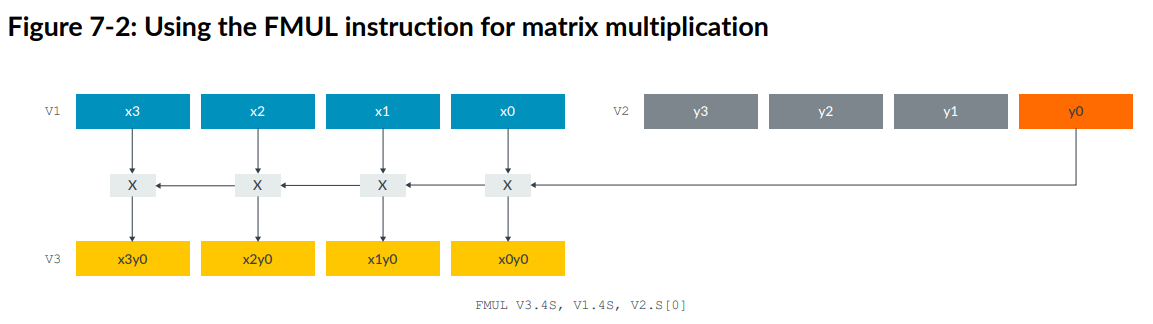
对应矩阵的计算为:
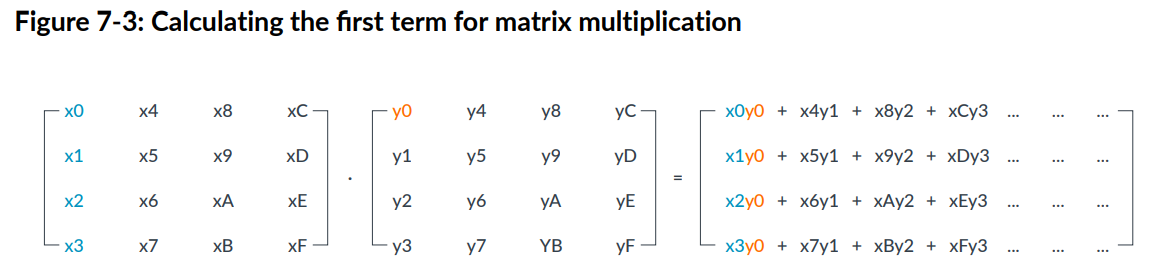
NEON寄存器可以按照不同的格式存储数据,如下图:
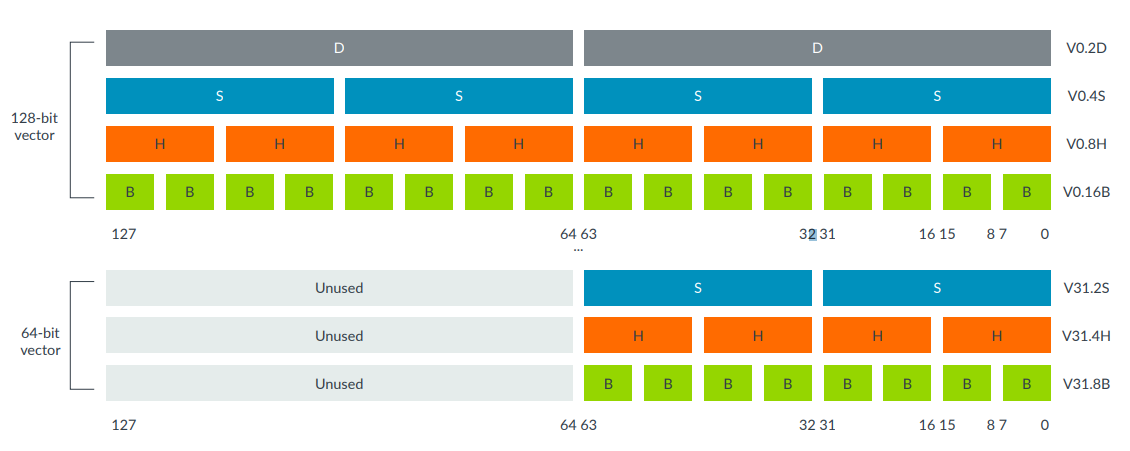
矩阵乘法分三步完成:
- Load矩阵数据
- 矩阵乘法
- 存储结果
load数据的指令如下:
1 | LD1 {V0.4S, V1.4S, V2.4S, V3.4S}, [X1] |
NEON提供32个128bit宽的寄存器。在这个实现中,V0-V3存储了第一个矩阵的16个元素,V4-V7存储了第二个矩阵的16个元素。每个寄存器存储一个矩阵行。
以下代码计算一列的结果:
1 | FMUL V8.4S, V0.4S, V4.S[0] // rslt col0 = (mat0 col0) * (mat1 col0 elt0) |
完整的矩阵运算代码就略去了。只要按照以上代码计算每一列就可以了。每一列要四条指令,将其进行交错,可以提高流水线的ILP。
3.8 Shifting left and right
本节介绍了NEON提供的shift操作。
NEON的向量shift和标量的操作很类似,将元素中的位左移或右移,移出的位会被舍弃,不会移到相邻的位置。移位数可以是指令指定的,也可以是一个移位向量。
下图是NEON的SSHL指令,V1是移位向量:
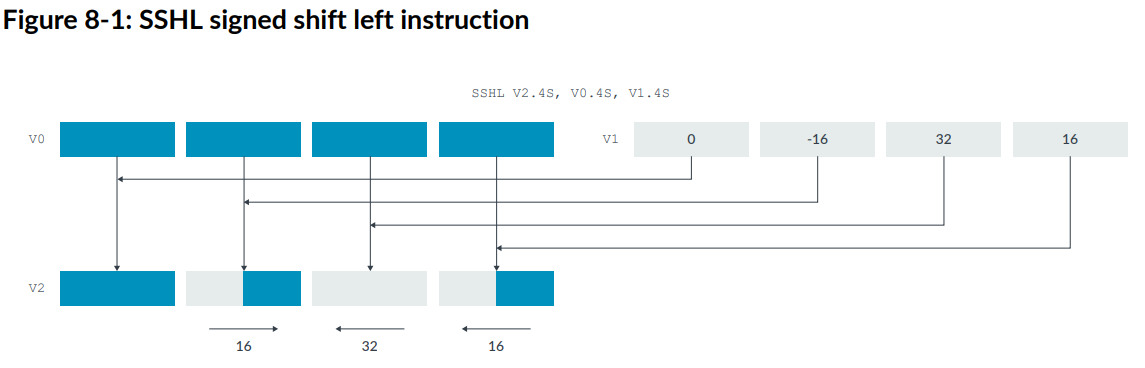
在右移位操作时,要考虑处理的是有符号还是无符号的数据。SSHL是有符号的shift操作。相应的USHL是无符号的。
NEON还支持插入shift,如下图的SLI指令:
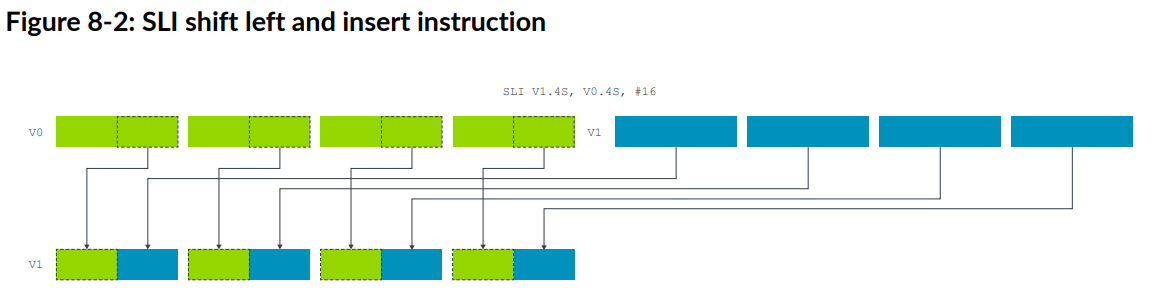
此后是shift指令的一些其他可选项的介绍,以及一个例子,这里都略去了。
Chapter 4 NEON Intrinsics
4.1 Overview
NEON Intrinsics提供了简单的NEON指令编写方式。有符合NEON的数据类型(D和Q寄存器的大小都有),可以使用C变量来分配NEON寄存器。由编译器生成具体的代码。编译器也会进行优化,进行指令重排序来减少停顿,提高ILP。
NEON intrinsic的定义在arm_neon.h中。
4.2 Vector data types for NEON intrinsics
数据类型的pattern如下:
type size x numberOfLanes _t
例如int16x4_t是一个有4个16bit的short int的向量。float32x4_t是有4个32-bit浮点的向量。

intrinsics的输入和输出可以是这些类型。有些intrinsics使用向量元素构成的数组,包含2,3,4个相同的向量元素,这样的类型为:
type size x numberOfLanes x lengthOfArray _t
这些类型是C结构体,包含一个val的数组。这样的类型可以通过NEON的指令一次加载或存储4个向量寄存器的值。
1 | struct int16x4x2_t |
这些类型只能使用load,store,transpose,interleave,deinterleave指令。可以通过下标访问单个寄存器,例如var_name.val[0]。
🔰initialize:vector data type不能赋值初始化,可以使用load指令初始化或使用vcreate intrinsic初始化。
4.3 Prototype of NEON Intrinsics
NEON intrinsics的指令格式如下:
opname flags_type
例如:
- vmul_s16,将两个含16bit signed的向量相乘
- vaddl_u8,将两个存储unsigned 8bit值的64bit向量相加,得到128bit的存储unsigned 16bit向量
flag可以取q,表示计算操作是针对128bit向量的。
🔰Note:含有__fp16的指令只用于支持半精度扩展VFP的架构。
4.4 Using NEON intrinsics
intrinsics含q的表示在Q寄存器操作,不含q的表示在D寄存器操作。例如:
1 | uint8x8_t vadd_u8(uint8x8_t a, uint8x8_t b); #64bit |
有些指令没有q后缀,也是会使用Q寄存器的。
1 | uint16x8_t vaddl_u8(uint8x8_t a, uint8x8_t b); |
一些NEON intrinsics指令会使用32bit的通用寄存器作为输入存储标量。例如以下这一些指令:
1 | vget_lane_u8 #get single value |
使用intrinsics时,使用不同的类型操作会比较困难,因为编译器会跟踪寄存器存储的类型。寄存器也会调度程序流及调整程序加快执行。
以下是一个将4lane 32bit向量元素翻倍的例子:1
2
3
4
5
uint32x4_t double_elements(uint32x4_t input)
{
return(vaddq_u32(input, input));
}
4.5 Variables and constants in NEON code
这一节主要是一些example code:
1 | //declaring variable |
4.6 Accessing vector types from C
C中的数据格式正如上述,写为uint8x16_t或者int16x4_t这样的类型。标量和vector之间必须通过intrinsics指令处理,例如result = vget_lane_u32(vec64a, 0)。
4.7 Loading data from memory into vectors
intrinsics使用vld1_datatype加载连续的数据,以下是一段示例代码:
1 |
|
4.8 Constructing a vector from a literal bit pattern
NEON intrinsics通过vcreate_datatype来从常量值创建向量,以下是一段示例代码:
1 |
|
4.9 Constructing multiple vectors from interleaved memory
NEON支持交错load数据。交错模式由n指定,指令为vldn_datatype,正如在第三章介绍的那样。
1 |
|
4.10 Programming using NEON intrinsics
NEON编程需要考虑到算法怎样能够实现并行,以下是一个计算数组和的例子,假设n是4的倍数。
1 |
|


