
《并行计算与高性能计算》简记
并行计算与高性能计算》阅读简记。
第一部分 并行计算介绍
并行计算的基本定律:
- Amdahl定律
- 强标度:总体问题规模确定,处理器数量增加,求解时间的变化。
- 弱标度:单个处理器处理的问题规模确定,处理器数量增加,求解时间的变化。
并行方法(模型):共享内存,消息传输,数据并行,流处理(GPU)。
- 算数强度:每个内存(4/8字节的数据)执行浮点运算次数。
- 理论性能峰值:虚拟核心数 × 频率 × 向量位 × FMA / (32或64)。
- 理论内存带宽:传输速率 × 通道数 × 访问字节数 × 插槽数。
- 实证测试:stream、cpufp。
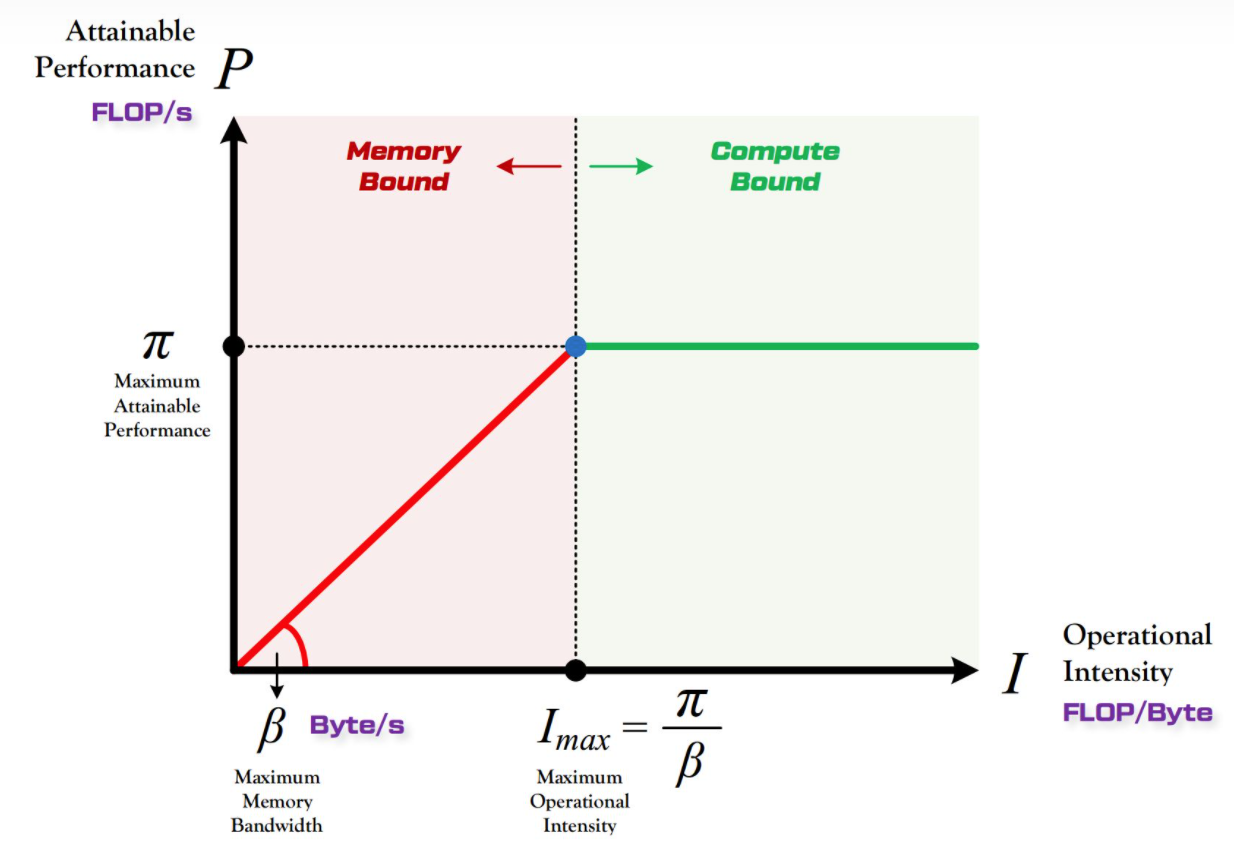
- Roofline模型
- 面向内存带宽的数据结构设计:
- 连续的二维数组分配。
- 结构数组、数组结构、混合结构,根据数据的使用情况确定合适的方式。
- 除了尽量将连续访问的内存分配在一起,一次完成可预知大小的分配比碎片化的分配要效果更好
第二部分 CPU并行
向量化的部分介绍了手动向量化和编译器自动向量化的方式,比较常规。
OpenMP多线程并行
OpenMP的部分除了介绍基本用法外,还介绍了一些重要的影响性能的细节:
- first touch:内存位置会分配到在第一次访问该地址的线程所在的位置,在此之前仅存在于虚拟地址空间的页表中,因此让每个线程first touch需要计算的数据有利于访存
- 高级OpenMP:当程序有多次OpenMP并行时,可以只启动并行段一次,将整体程序全部包含在其中,串行的部分通过线程号控制主线程处理,并且通过nowait最小化barrier和可能的同步操作
书中给出了几个示例。这里也尝试一下前面提到的内存相关的优化效果。
Example: SplitStencil
| opt | time |
|---|---|
| baseline | 27.459721 |
| memopt | 14.876064 |
| omp4线程 | 10.687703 |
| omp(一次并行启动4线程) | 10.937465 |
这里一次启动没有什么效果,暂不确定原因。但是memopt作用很明显。另外多线程效果也非常差。在另一台机器上多线程效果好一些,一次启动同样没有明显的效果,可能是启动开销并不大,memopt也没有效果,应该是原本的分配方式也刚好malloc到了统一的内存位置。关于性能上的差异和产生的问题,需要进一步profile才能确定原因。
Example: PrefixScan
排他前缀和的并行算法,首先将数据整体进行分块,每个线程首先计算自己块内的排他前缀和,此时每个线程的第一个位置为0,然后由主线程串行更新偏移,设定每个线程j的第一个位置为前j-1个线程的排他前缀和,这个值为j-1的起始位置+线程j-1的最后一个位置的排他前缀和+最后一个位置的值,特殊处理线程块内只有两个元素的情况,此时上一区间没有排他前缀和或者说为0,已经在处理上一个线程数据时修改了。最后再并行将每个块的第一个值也就是真正的前缀加到块内每一个数据上。
1 | void PrefixScan (int *input, int *output, int length) |
这里把之前的前缀和放到了第一个位置,也可以换一种方式,对每个组最后一个元素求前缀和,这样每个组最后一个位置就是包含前面所有元素的前缀和,再更新整个组(除了最后一个位置)就可以了。
最后一节介绍了OpenMP的任务并行,使用#pragma omp task进行任务并行,然而仅给出了一个求和示例,没有更详细的介绍子句的用法,如果需要使用,还要阅读OpenMP的文档进一步学习。
MPI并行
第三部分 GPU加速程序运行
1 GPU架构及概念
介绍了很多概念性的基本知识,没有这本书的电子版,有一些图表不方便放上来。内容对于没接触过GPU计算的都很基础和必要,这里只记录一些概念。
- 计算GPU的理论峰值:时钟频率(MHz)x计算单元数量(CU/SM)x处理单元数量(cores per CU)xflop/周期。对于NVIDIA最新的V100,CU有80个,单精度浮点core per CU为64,频率为1530MHz,其理论峰值为2(FMA) 1530 80 * 64 / 10^6 = 15.6Tflop(单精度)。
理论带宽:内存时钟速率x内存总线(bit)x(1/8)x事务因子
测量GPU带宽:GPU stream benchmark,除了工具测量,带宽和roofline还可以在nsight compute看到。
1 | git clone git@github.com:UoB-HPC/BabelStream.git |

- PCI总线是CPU与GPU之间的数据传输桥梁,版本目前称为PCI Express,已有六代。PCI总线的理论带宽为通道数x传输速率x开销因子x字节/8bit,新代的PCIe数据编码成本很小,因此开销因子接近100%。lspci可以获取PCI信息。或者桌面系统的NVDIA控制台也可以看到:

- 多GPU平台和MPI:多GPU平台通常需要使用MPI+GPU实现并行化,单个计算节点可以配置多个GPU,多个计算节点可以网络连接。当大量数据进行移动时,数据通过PCI总线发送可能称为性能的主要限制,在同一个计算节点,NVDIA GPUDirect或AMD DirectGMA可以在GPU之间传输数据,减少内存在GPU到处理器及系统内存之间的移动。NVDIA还退出了NVLink,取代GPU到GPU和GPU到CPU之间的连接,使用NVLink,数据传输速率可以达到300GB/s。
- 能耗的测量:使用制造商的热设计功率TDPx运行时间x处理器数量可以估计能耗上限。GPU的TDP比CPU一般更高,但是计算时间也更短。
2 GPU编程模型
CUDA部分单独阅读了一本书,内容都在另一份笔记里了。


