
CUDA笔记1
CUDA 笔记
CUDA笔记。
Reference:
- https://face2ai.com/program-blog/#GPU编程(CUDA)
- https://github.com/HeKun-NVIDIA/CUDA-Programming-Guide-in-Chinese
- CUDA by example
主要参考是Professional CUDA C Programming这本书和第一个链接博主的笔记。
1 CUDA 编程模型
1.1 CUDA并行编程模型概述
1.1.1 内存管理
CUDA提供了API分配管理设备上的内存,这些API也可以分配管理主机上的内存。这些API和标准库的内存管理API是对应的。
API: cudaMalloc cudaMemcpy cudaMemSet cudaFree
其中cudaMemcpy实现主机到设备的数据拷贝:
1 | cudaError_t cudaMemcpy(void * dst,const void * src,size_t count, |
cudaMemcpyKind kind:
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
返回的结果有两种, cudaSuccess或cudaErrorMemoryAllocation,可以用以下接口得到详细信息:
1 | char* cudaGetErrorString(cudaError_t error); |
CUDA的内存层次可以大概用以下模型描述:
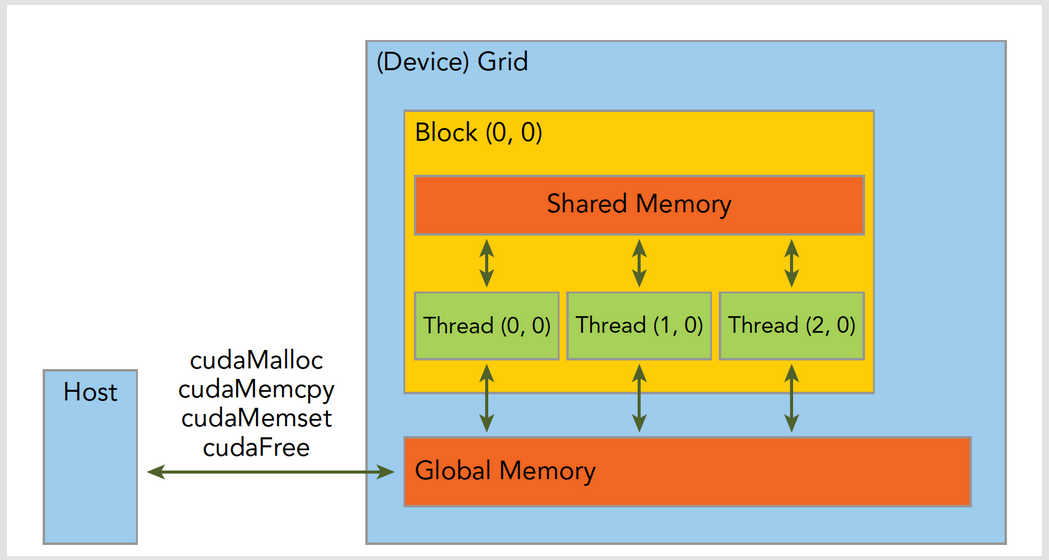
为了区分设备和主机内存,在分配时可以给变量添加后缀_d和_h。从而避免混用设备和主机的内存地址。
1.1.2 线程管理
组织GPU的线程是进行并行化时的一个主要问题。在GPU中,一个核函数包含一个grid,一个grid包含多个块,每个块中有多个线程。
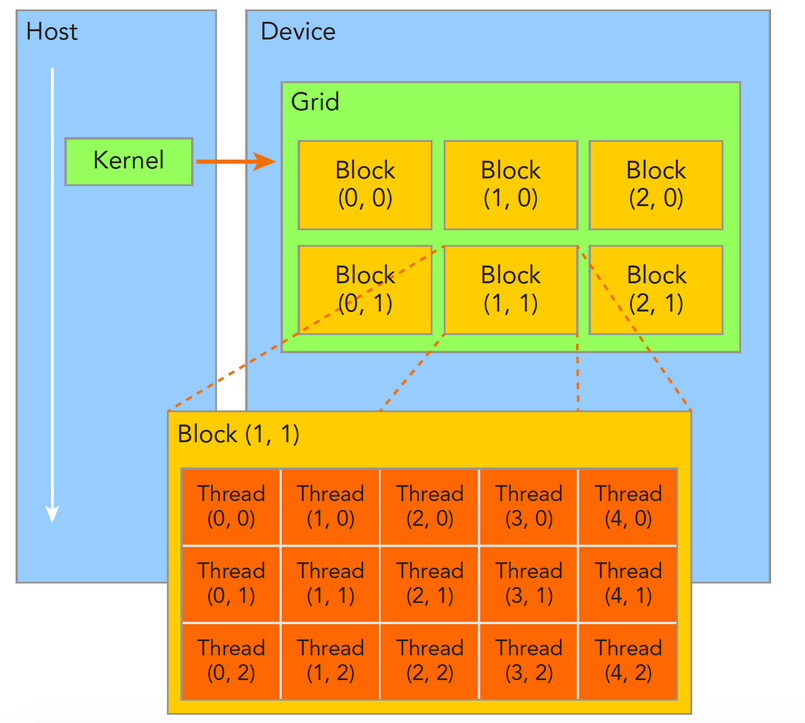
一个线程块中的线程可以进行同步,并共享内存。线程的编号是由两个结构体确定的:
- blockIdx:块在网格中的索引。
- threadIdx:线程在块内的索引。
这两个结构体都包含三个无符号整数字段x,y,z。还有两个结构体保存上述x,y,z字段的范围:
- blockDim
- gridDim
这两个结构体同样包含x,y,z三个字段。为dim3类型。
一个网格通常被分为二维的块,每个块常被分为三维的线程。dim3是在主机定义的,不可修改。其各维度的限制后续介绍。
1.1.3 核函数
核函数是在GPU上运行的代码,这部分代码是NVCC编译的。核函数都通过以下方式启动:
1 | kernel_name<<<grid,block>>>(argument list); |
可以使用dim3类型的grid和block配置内核函数运行,也可以直接使用常量/int变量初始化。例如:
1 | kernel_name<<<4,8>>>(argument list); |
对应的线程布局为:

当主机启动核函数,控制流会回到主机代码。可以通过以下API进行同步:
1 | cudaError_t cudaDeviceSynchronize(void); |
以上是显式进行同步。在启动核函数之后,cudaMemcpy等API也会进行隐式的同步。
核函数的声明限定符有三种,分别为:
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
| __global__ | 设备 | 主机或计算能力3以上的设备 | 返回void |
| __device__ | 设备 | 设备 | |
| __host__ | 主机 | 主机 | 可省略 |
核函数有以下限制:
- 只能访问设备内存
- 必须返回void
- 不支持可变数量参数
- 不支持静态变量
- 显式异步
1.1.4 错误处理
由于CUDA核函数是异步执行的,为了处理和方便发现错误,要检查调用的返回值,例如如下的宏:
1 |
在编写代码时,处理错误信息可以方便找到错误。在release版本中可以去掉错误检查。
1.2 核函数计时
性能优化时常常对函数运行时间进行计时。然而,核函数的启动和返回本身是需要时间的,因此在启动前开始计时,同步后计时结束的时间和执行时间有偏差。
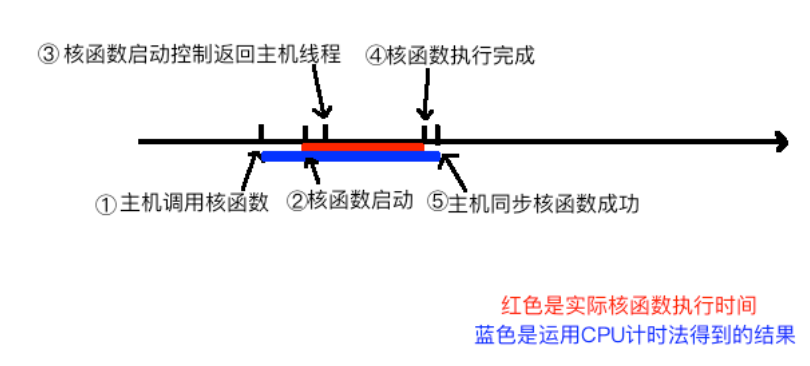
和c/c++程序使用perf进行性能分析一样,CUDA程序也可以使用一个名为nvprof的工具进行性能分析。
nvprof需要开启权限,在linux上sudo运行,在win上需要通过nvdia控制面板的开发者模式开启权限。win上还可能提示缺少.dll文件,可以在安装路径/extras下寻找.dll移动到bin下。
1 | nvprof [nvprof_args] <application>[application_args] |
更详细的profile参数和指导见https://docs.nvidia.com/cuda/profiler-users-guide/index.html#。
nvprof已经不支持计算能力7.5以上的设备,只能做基本的计时,现在的设备基本都需要使用nsight system(nsys)进行详细性能分析,需要注意nsys分析需要应用路径合法。
1.3 组织并行线程
在2.2.2节已经初步介绍了线程的可组织方式。对于二维网格,下图可以直观的体现每个线程的编号:
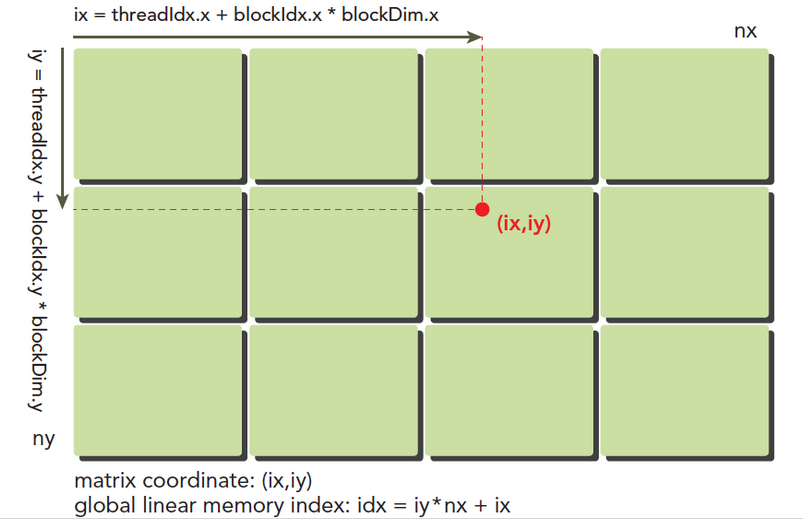
这是用ix iy表示线程,如果用全局ID表示线程编号,为blockDim.x*blockDim.y*gridDim.x*blockIdx.y + blockDim.x*blockDim.y*blockIdx.x+threadIdx.y*blockDim.x+threadIdx.x。
当然,在设备上,数据都是线性存储的,例如一个二维矩阵:

线程和数据的映射关系可以自行设计,最简单的方式就是ix,iy的线程处理二维的(ix,iy)的数据。不同的线程的组织方式能得到不同的性能,在后续章节会介绍具体的原因。
1.4 设备信息查询
CUDA C提供了cudaGetDeviceCount获取设备数量,并可以使用cudaGetDeviceProperties( &prop, i )获取设备的具体信息,从而选择合适的设备。可以为prop赋值,然后通过cudaChooseDevice( &dev, &prop )条件筛选合适的设备,cudaSetDevice( dev )决定使用的设备。CUDA by example提供了一份输出主要设备信息的示例代码,包含以下的信息:
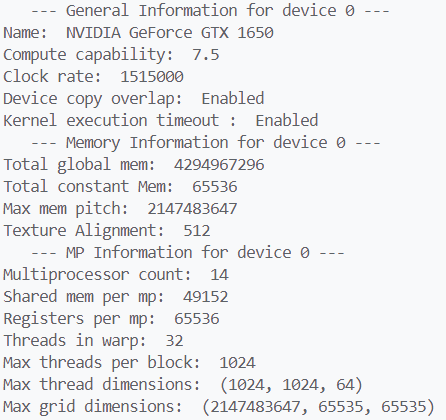
2 CUDA 执行模型
2.1 架构概述
GPU架构是基于流式多处理器(SM)搭建的。GPU中包含多个SM,SM的结构如下图:
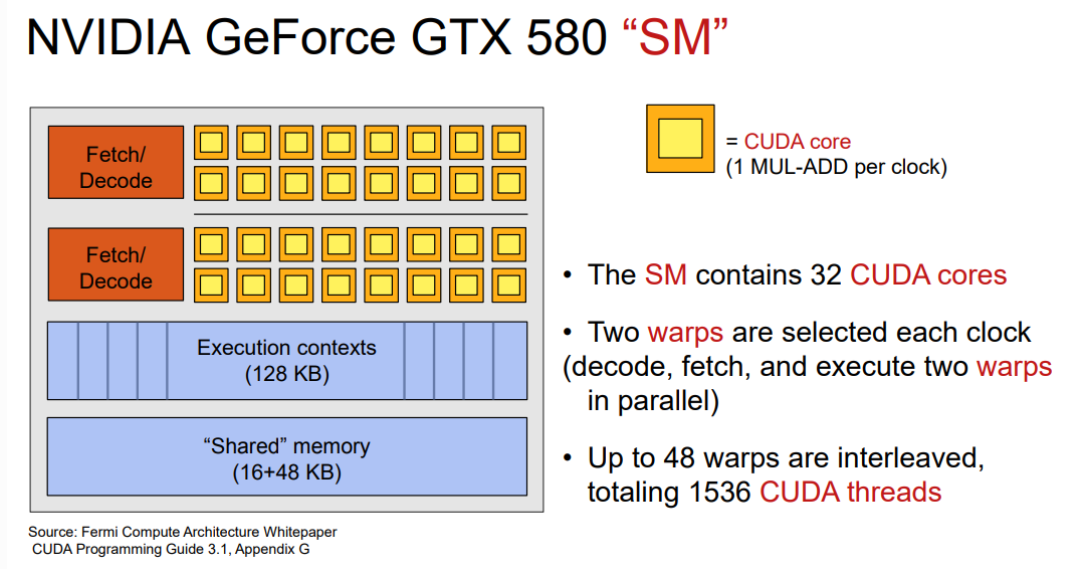
这张图还省略了一些其他组件,例如寄存器文件和线程束调度器。CUDA使用SIMT并行。调度执行线程束,不同设备有不同线程束大小,通常为32。每个SM可以被分配到多个block,一个block可以有多个线程,但SM每次只执行一个线程束。线程块被分配到SM上时,会被分成多个线程束,线程束在SM上交替执行。
2.2 线程束执行
2.2.1 线程束分化
线程束执行时执行的是相同的指令,处理自己的数据。如果一个线程束的不同线程包含不同的控制条件,就会导致线程束的分化。例如一个if else条件选择块,每个线程都会执行所有的if和else部分,一部分线程执行if的部分,而其他线程只能等待,然后所有线程进入else代码块,上一步等待的线程再执行else的部分,其他线程等待。
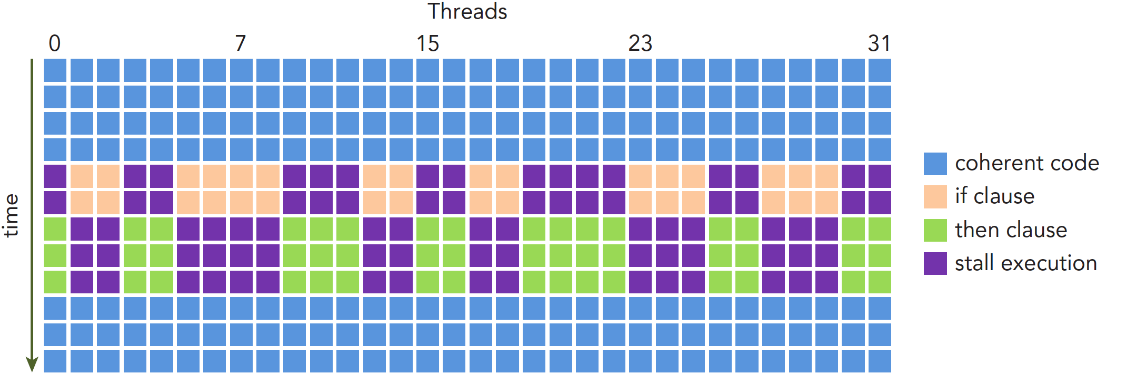
如果线程束所有的线程都执行if或else时,就不会产生上述问题,因此可以控制一个线程束的线程进入同一个分支,例如:
1 | __global__ void mathKernel2(float *c) |
2.2.2 线程束执行的资源分配
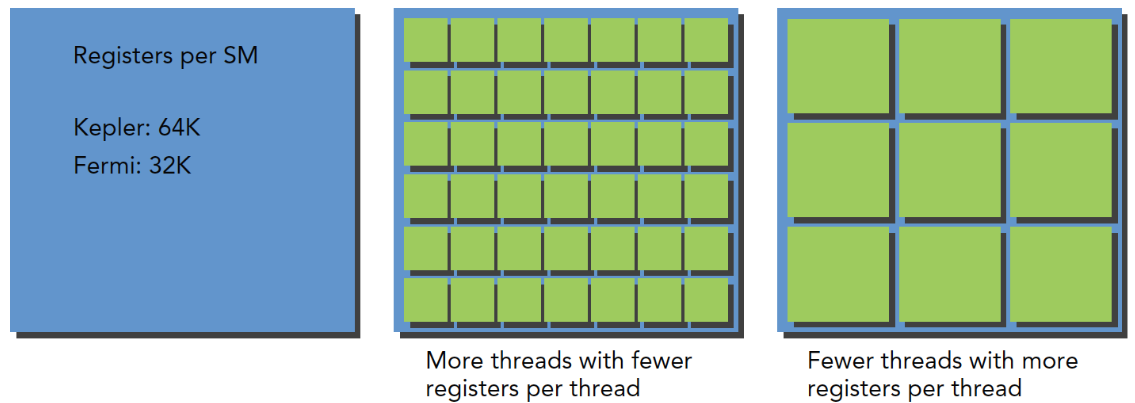
线程束可以是已经执行的,也可以是已经分配到SM,但还未进行资源的分配。
每个SM上有多少个线程束可以处于执行状态,取决于寄存器等资源。kernel占用的资源越少,更多的线程就能同时执行。
2.2.3 隐藏延迟
延迟有两种,计算延迟和访存延迟。必须有足够的线程束用于调度,才能最大效率使用计算资源和带宽。对于计算延迟,所需线程束是延迟 * 吞吐量。延迟是计算指令需要的时钟周期,吞吐量是单周期能进行的操作。
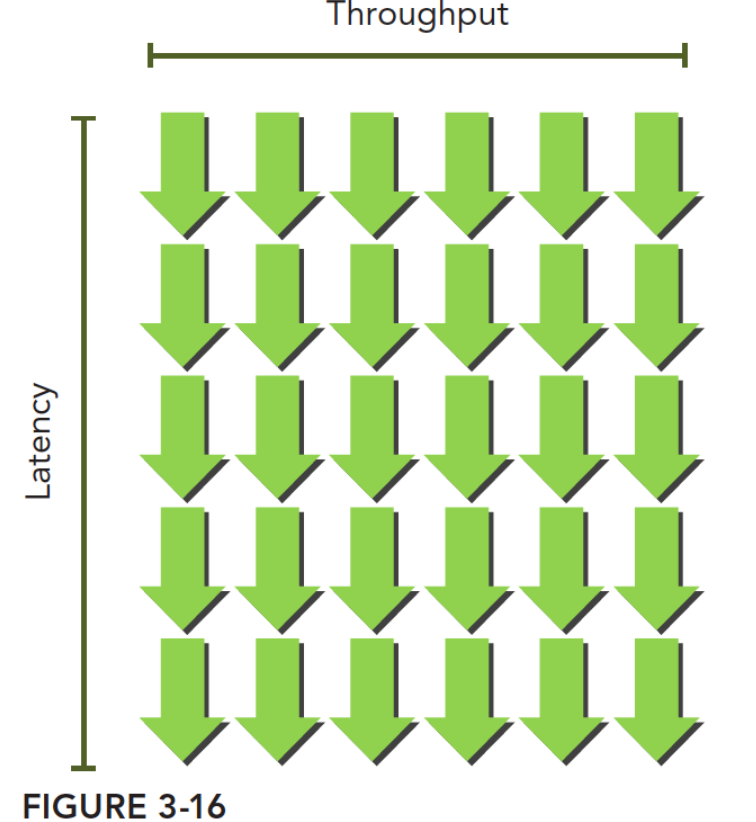
类似的,访存延迟的隐藏需要访存延迟*每个时钟周期可读取的数据量才能充分利用到GPU带宽。
线程束的下界为计算核心数单条指令延迟、例如一个计算的延迟为32个时钟周期,则最少需要32\20个线程使设备满载。
2.3 并行性表现
本节通过修改核函数的配置,进行性能分析,进一步理解线程束执行的过程。本节使用的核函数为矩阵加法。
1 |
|
使用nsys做profile,自己的gpu为gtx1650,metrics-set为tu11x,可以通过--gpu-metrics-set=help看支持的metrics-set。
1 | nsys profile --gpu-metrics-set tu11x --gpu-metrics-devices 0 --stats=true ./main |
profile后较为细节的数据都在sqlite里面,可视化界面打开nsys-rep报告可以直观看到数据。但是nsys得到的是整体宏观的数据,不便观察更详细的核函数运行数据,因此用另一个工具nsight compute再做profile,记录不同线程块配置的一些数据:
| block-size | Achieved Occupancy | time |
|---|---|---|
| 32x32 | 87.34 | 0.000054 |
| 16x32 | 82.68 | 0.000084 |
| 16x16 | 85.65 | 0.000077 |
| 32x16 | 82.68 | 0.000083 |
可以看到规整的threadBlock有更好的效果,对于当前这个小计算任务,32x32的较大threadBlock的SM Occupancy是最高的,这也符合前面隐藏延迟的理论,因为这个计算并不复杂,占用的资源并不多,尽可能多的线程可以在SM上充分利用硬件资源完成计算。
除了achieved occupancy,nsight compute还能测量许多其他的指标,在调优时可能都需要关注。例如访存相关的数据:
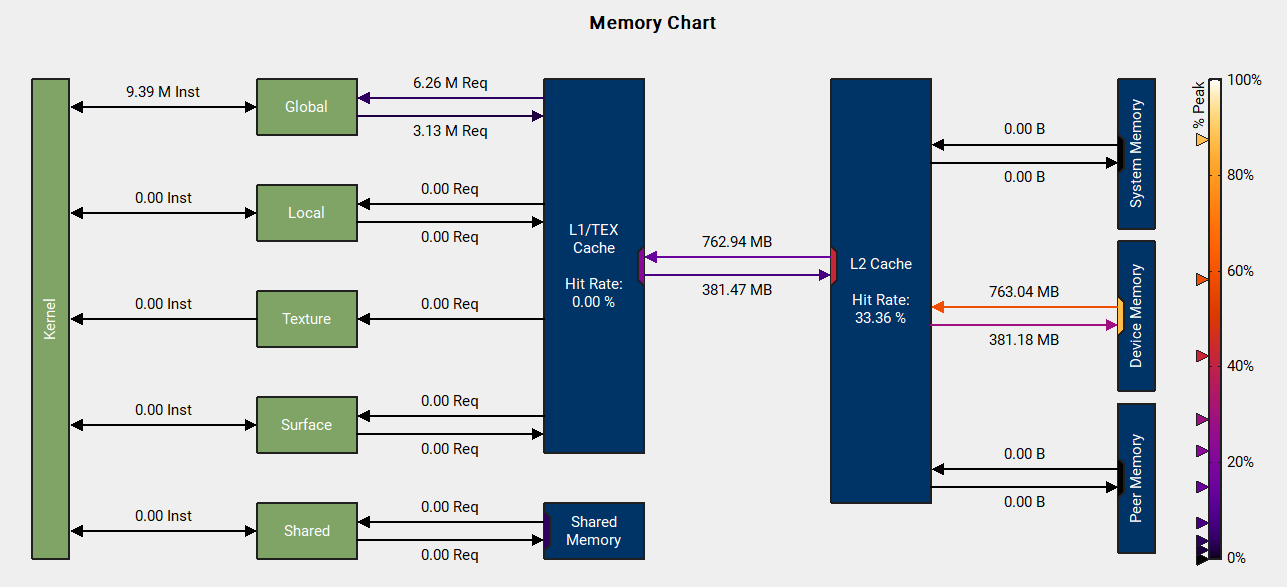
说明这个程序的线程组织方式完全没有利用到L1 Cache,仍有很大的改进空间。
2.4 避免分支分化
本节从并行归约问题出发,学习GPU并行编程时避免分支分化的方法。
归约是常见的并行化的步骤,用于对分块的结果进行处理。首先考虑最简单的规约,对向量求元素和。并行时各个线程计算一组元素,得到的结果归约迭代求和。常见的元素划分方式有两种:相邻元素配对和交错配对。
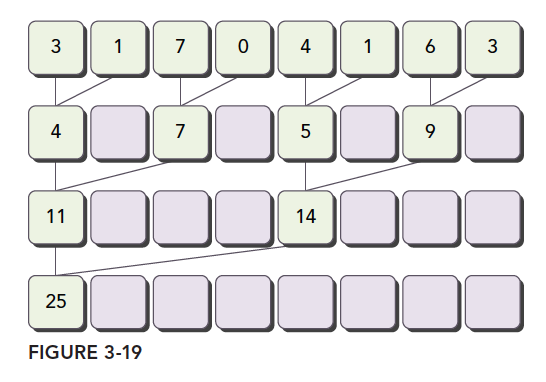
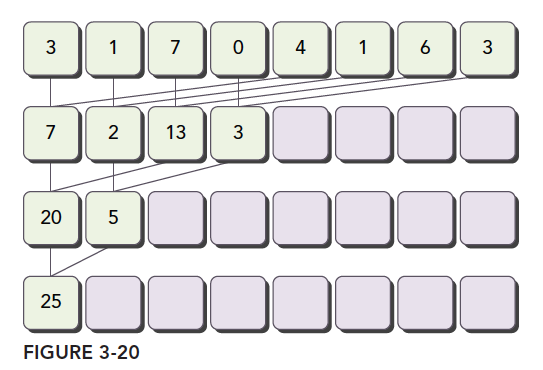
以下是CPU的交错配对归约:
1 | int recursiveReduce(int *data, int const size){ |
在GPU上,首先编写相邻元素配对的核函数,每个线程块计算一组数据,最后归约所有线程块的结果。这里假定了数据的总数是2的幂次方,如果不是需要考虑边界问题。
1 | __global__ void reductSum(int *in, int *out, int size) { |
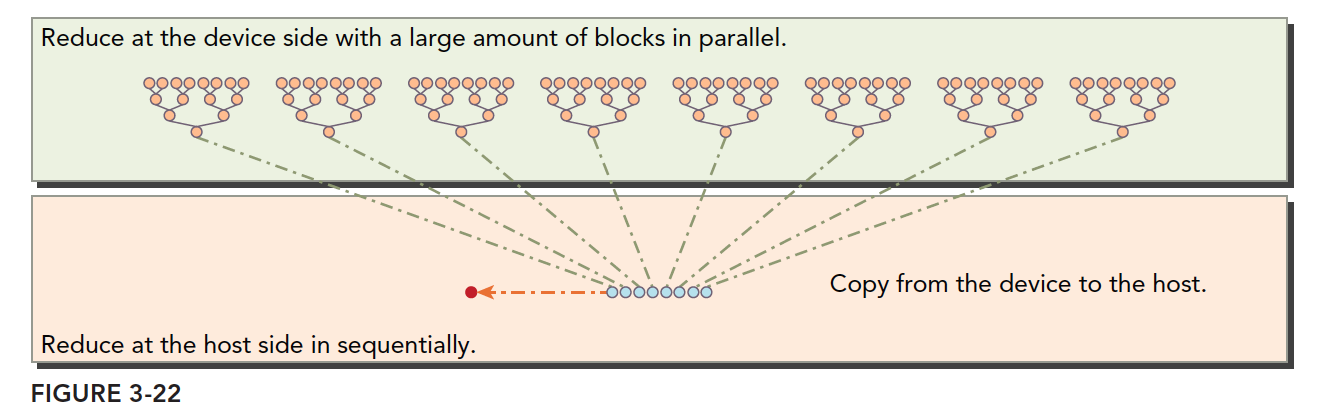
线程从一开始就只有1/2会进行计算,其他都在进行分支判断后等待,每一个线程束都只有一半的线程计算,却会使用整个SM。如果能将计算的线程控制在一起,不计算的线程控制在一起,不计算的线程的分支都不执行,SM就不会调度运行包含这些线程的线程束,节省了资源,从而提高了效率。
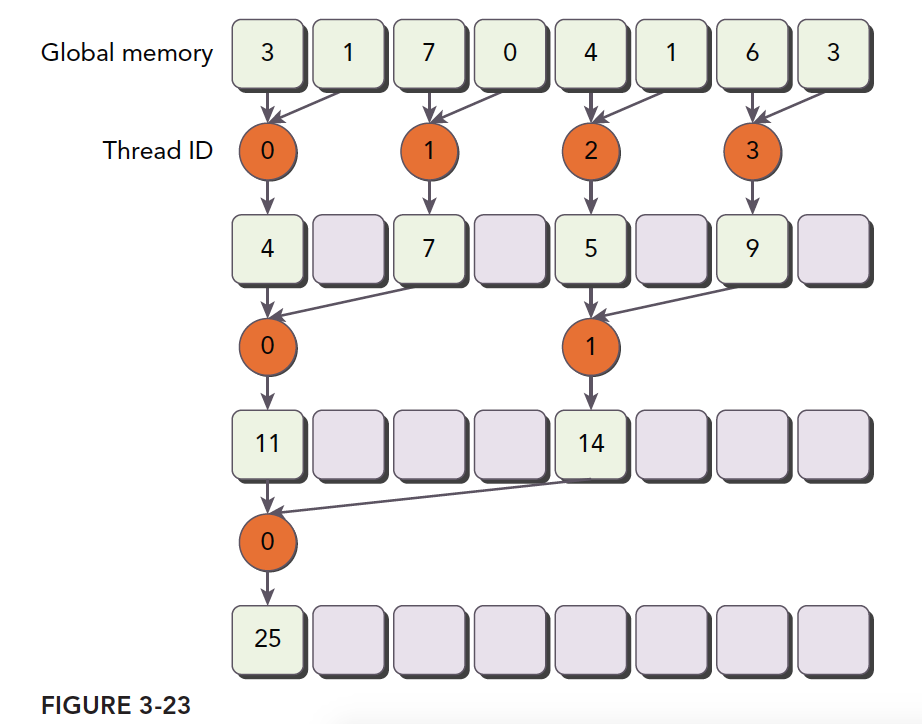
1 | __global__ void reductSumOpt(int *in, int *out, int size){ |
执行结果如下:
1 | Correct. basic ver T=0.006428 |
实现了1.7x的提升。这是非常显著的,和参考博客作者的性能提升也类似,说明实际的硬件执行情况是符合预期的。接下来对采集数据进行分析,nsight compute没有inst_per_warp这个指标了,但是指令相关的数据也还是可以观察到明显的不同:


调整线程分支处理后,执行的指令数下降了,未参与计算的线程束的分支指令没有调度执行。另外,访存的效率也提升了,MemoryThroughput从23.74提升到了44.56。
除了以上的方式,改用交错配对的方式也能将计算的线程控制在一起,如下图所示:
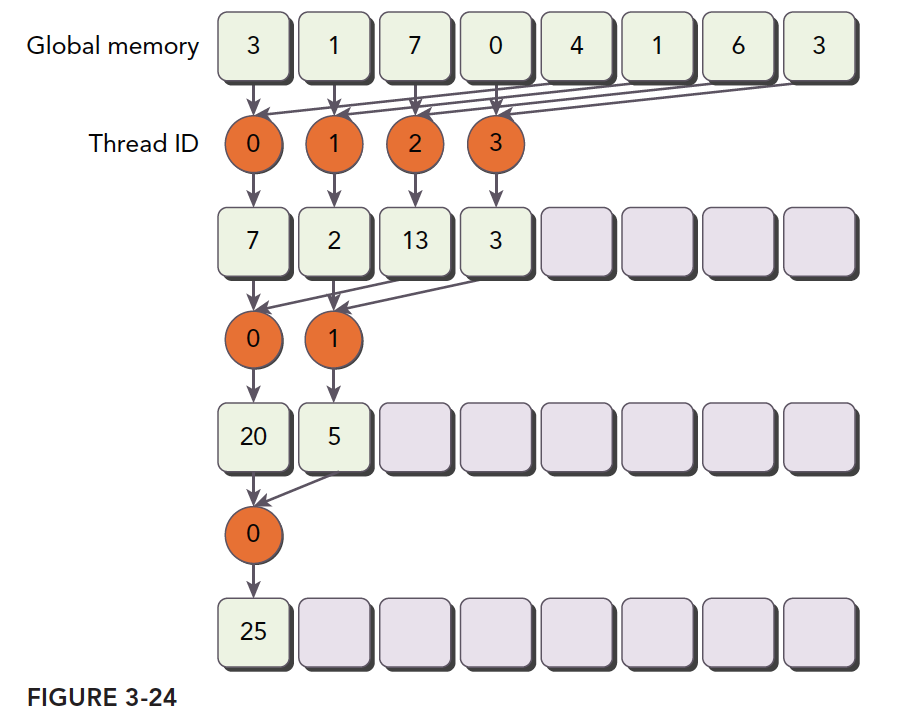
1 | __global__ void reductSumInterleaved(int *in, int *out, int size){ |
执行结果:
1 | Correct. basic ver T=0.006622 |
执行效率与上面的优化方式是一样的。从分支的角度考虑,和上面的优化一样,让靠后的线程束内的线程全部不进入分支,避免被调度执行从而提高了效率。同样的,从profile数据来看是否执行情况是符合预期的。
指令的执行情况如下,比上面的方式要略好一些,但是具体的原因还不太明确。

从访存的角度来看,MemoryThroughput降低到了35,L1Cache和L2Cache的缓存命中率都下降了,这是符合预期的,因为起初的访存跨度是最大的,此后逐渐减小,而前两种方式的访存跨度是一开始较小,后面更大,后面跨度大时,数据已经载入到缓存了。因为截至这一节尚未学习内存模型,因此也可能和设想的这个原因不同。此外,虽然缓存命中率明显下降,但却没有影响性能,这是因为写回的数据变少了,上面两种方式写回L2cache的数据是这种的四倍,因为写入的数据是交错的,导致不需要写入的数据也进行了写入。这也充分说明了最佳的性能要通过访存和指令执行(运算)等多方面权衡得到。
2.5 循环展开
CPU执行代码中的循环展开很多时候编译器都可以完成,GPU执行的代码,,编译器是否能进行循环展开优化,考虑到编译器也在不断更新,还是需要实际测试一下。
上一节中的交错归约每个线程只处理了对应部分的数据,为了提高线程块的负载,对其进行循环展开,考虑用一个线程块处理多块数据。在一开始的时候就将相邻块的数据添加到线程对应位置上。

1 | __global__ void reductSumInterleavedUnroll(int *in, int *out, int size){ |
执行时间如下,有显著的性能提升:
1 | Correct. basic ver T=0.006359 |
除了上面这种直接先将块的数据加到当前数据位置的方式,我还尝试了直接对两个块的数据进行交错归约,时间和上述方式基本一致。如果改变线程块的计算块数量,性能还会有进一步提升:
| 块数量 | 执行时间 |
|---|---|
| 2 | 0.002182 |
| 4 | 0.001600 |
| 8 | 0.000957 |
到了这里已经实现了相对于最基础的版本4.8x的加速比。用nsight compute观察一下各项指标的变化:


最直观的是指令数减少了,只有之前版本的16%,因为线程束减少了,每个线程都承担了原来8个线程的计算,但只增加了if分支内的8条语句,MemoryThroughput翻了一倍,因为每个线程都需要8个数据块的数据,这也导致了缓存命中率的下降,但并不影响性能的提升,最后,从L2cache写回DeviceMemory的数据也变成了原来的1/8,降低了写入开销。还有一些其他指标下降了,SM Throughput和SM Busy%等,这再次说明了好的性能是多个方面的均衡,要找到真正的性能瓶颈,对瓶颈优化可以牺牲其他方面的效率。
接下来考虑能不能将最后的64个数的计算进行展开。在交错归约的过程中,每计算一轮,有效线程数和数据都会减半。当线程数小于32时,就会出现最后一个线程束内有线程不进入(tid1
2
3
4
5
6
7
8
9
10
11
12
13
14
15for(int stride = blockDim.x/2; stride>32; stride/=2){
if(tid < stride){
a[tid] += a[tid + stride];
}
__syncthreads();
}
if(tid<32){
volatile int *vmem = a;
vmem[tid] += vmem[tid+32];
vmem[tid] += vmem[tid+16];
vmem[tid] += vmem[tid+8];
vmem[tid] += vmem[tid+4];
vmem[tid] += vmem[tid+2];
vmem[tid] += vmem[tid+1];
}
第一次计算是32个线程加上64个数据的后半部分,第二次计算时是前16个线程加上前32个数据的后16个,后16个线程也参与了计算,但计算的数据是无意义的,虽然这后16个线程会修改自己的数据,但是SM上线程的执行是同步的,当这16个线程要修改自己的值时,前16个线程已经读取了需要的后16个线程的上一轮数据,并计算完写入了,这也是要用volatile写入和读取数据的原因。
在实际的测试中,这个优化并没有效果,和上面的8次展开的计算时间是基本完全一致的,说明上述的问题对性能影响不大,但展开的思路仍然是值得学习的。
这里要指出,参考博客的作者通过本步优化得到了可见的性能提升,经过我自己的测试,发现性能的提升并不来源于这里,而很可能是来自于以下代码:
1 | if(idx + blockDim.x*(blockPerthread-1) < size){ |
如果每个语句都是a[tid]的+=操作,时间刚好是作者测试的8次展开的0.0012左右的时间,修改为以上后,时间变为了0.0010xx甚至0.00095,优化了对a[tid]的写入。这里对cpu编程这样的代码编译器会不会自动优化没有印象,但至少GPU是不会的,因此可以得到可见的性能提升。
2.6 动态并行
CUDA支持在内核中启动内核,能让复杂内核更加有层次,这样就可以动态调整负载,并且通过内核中启动内核减少数据传输消耗及启动开销。在频繁启动内核的场景下,这是有必要的。有些类似openmp的task并行。
内核中启动的子线程网格和线程全部结束后,父线程和网格才可以结束。线程启动子网格是隐式同步的,即所有线程会同步启动子网格和子线程。
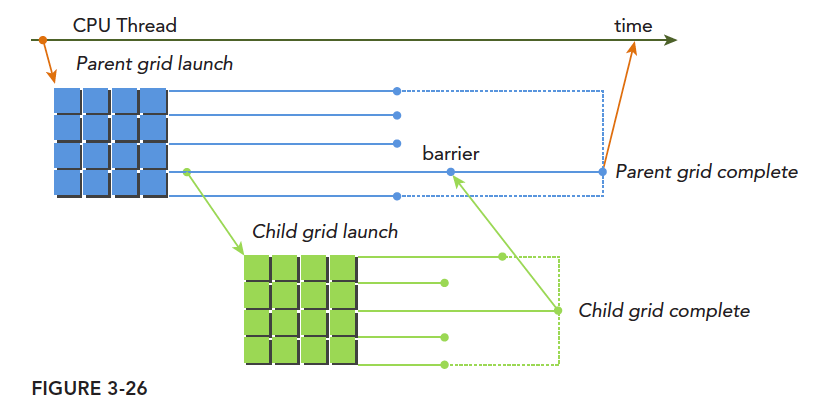
核函数内部以相同的方式启动新的子网格,完成嵌套启动,书中给出了嵌套启动helloworld和嵌套规约的例子。
3 全局内存
3.1 概述
CUDA的内存模型比CPU要更丰富一些,GPU上的内存设备有:
- 寄存器
- 共享内存
- 本地内存
- 常量内存
- 纹理内存
- 全局内存
每种内存都有自己的作用域,生命周期和缓存行为。每个线程都有自己的私有的本地内存,而共享内存是线程块内所有线程可见的,所有线程都能读取常量内存和纹理内存,但这两部分是只读的。全局内存,常量内存和纹理内存都有相同的生命周期。
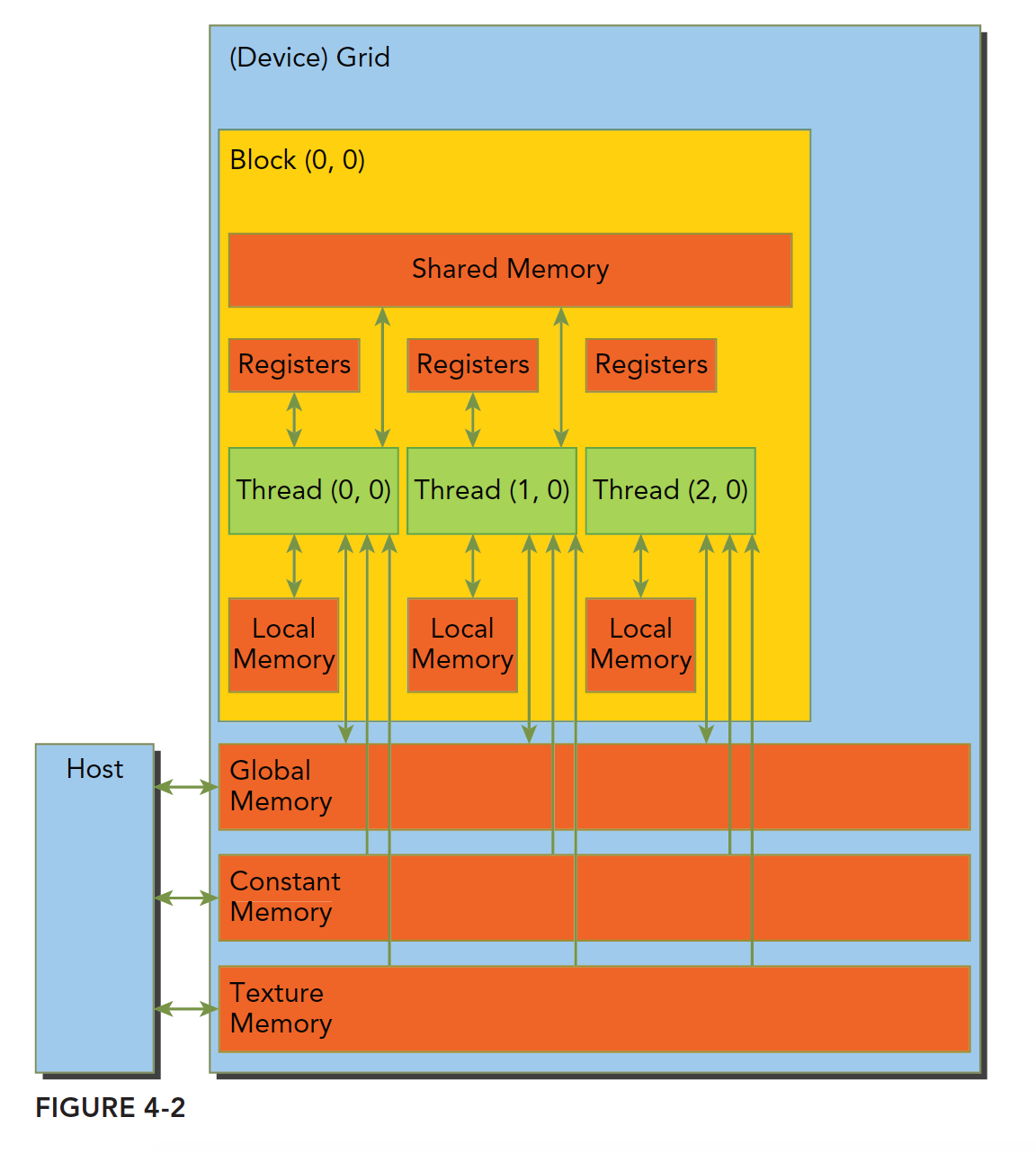
寄存器
寄存器是速度最快的内存。GPU的寄存器比CPU要更多。核函数内声明的变量都存储在寄存器中,定义的常数长度的数组也是在寄存器中分配地址的,而不像CPU在主存上。
寄存器是线程私有的。生命周期是核函数内部。Fermi架构中每个线程最多63个寄存器,Kepler结构最多255个寄存器。如果线程使用的寄存器越少,常驻线程块就越多。SM上并发的线程块越多。
如果变量太多导致寄存器溢出,数据就会存储在本地内存。可以在编译选项中加入-maxrregcount=32控制一个编译单元里所有核函数使用的寄存器最大数量。
本地内存
本地内存的存储的变量只可能是使用未知索引引用的本地数组,可能占用大量寄存器空间的数组或结构体,溢出的变量。现在的设备,本地内存都存储在每个SM的一级缓存或设备的二级缓存上。
共享内存
核函数中__share__修饰的内存称为共享内存。每个SM都有一定数量的由线程块分配的共享内存,共享内存是片上内存,延迟低,带宽高。其类似于一级缓存,但是可以被编程。共享内存和寄存器一样,需要避免使用过多导致活跃线程束数量减少。
共享内存在核函数内声明,生命周期和线程块一致。因为共享内存是块内线程可见的,所以就有竞争问题的存在,需要通过同步避免内存竞争。
1 | void __syncthreads(); |
注意,__syncthreads();频繁使用会影响内核执行效率。
SM中的一级缓存,和共享内存共享一个64k的片上内存,他们通过静态划分,划分彼此的容量,运行时可以通过下面语句进行设置:
1 | cudaError_t cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache); |
这个函数可以设置内核的共享内存和一级缓存之间的比例。cudaFuncCache参数可选如下配置:
1 | cudaFuncCachePreferNone//无参考值,默认设置 |
Fermi架构支持前三种,后面的设备都支持。
常量内存
常量内存驻留在设备内存中,每个SM都有专用的常量内存缓存。内存常量通过__constant__在核函数外声明。对于所有设备,只可以声明64k的常量内存,常量内存静态声明,并对同一编译单元中的所有核函数可见。常量内存被主机端初始化后不能被核函数修改,初始化函数如下:
1 | cudaError_t cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count); |
当线程束中所有线程都从相同的地址取数据时,常量内存表现较好,比如执行某一个多项式计算,系数都存在常量内存里效率会非常高,但是如果不同的线程取不同地址的数据,常量内存就不那么好了,因为常量内存的读取机制是:
一次读取会广播给所有线程束内的线程。
纹理内存
纹理内存驻留在设备内存中,在每个SM的只读缓存中缓存,纹理内存是通过指定的缓存访问的全局内存,只读缓存包括硬件滤波的支持,它可以将浮点插入作为读取过程中的一部分来执行,纹理内存是对二维空间局部性的优化。
总的来说纹理内存设计目的应该是为了GPU本职工作显示设计的,但是对于某些特定的程序可能效果更好,比如需要滤波的程序,可以直接通过硬件完成。
全局内存
一般在主机端代码里定义,也可以在设备端定义,不过需要加修饰符,只要不销毁,是和应用程序同生命周期的。使用__device__在设备代码中静态声明全局内存变量。
因为全局内存的性质,当有多个核函数同时执行的时候,如果使用到了同一全局变量,应注意内存竞争。
缓存
与CPU缓存类似,GPU缓存不可编程,其行为出厂是时已经设定好了。GPU上有4种缓存:
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
每个SM都有一个一级缓存,所有SM共用一个二级缓存。一级二级缓存的作用都是被用来存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。Fermi,Kepler以及以后的设备,CUDA允许我们配置读操作的数据是使用一级缓存和二级缓存,还是只使用二级缓存。
与CPU不同的是,CPU读写过程都有可能被缓存,但是GPU写的过程不被缓存,只有加载会被缓存。
每个SM有一个只读常量缓存,只读纹理缓存,它们用于设备内存中提高来自于各自内存空间内的读取性能。
静态全局变量
除了cudaMalloc的动态分配全局内存,还可以在全局内存上静态分配变量,调用的是常量的memCpy接口:
1 |
|
注意与常量不同的是参数是变量标识符,而不是取址。并且这个内存也不能通过cudaMemcpy赋值。
3.2 内存管理
3.2.1内存的分配,释放与数据传输
在全局内存分配和释放方面,GPU和CPUS是类似的,使用cudaMalloc分配数据,并通过传输获取主机的数据。CPU到GPU的内存传输非常慢,因此要尽可能减少传输。
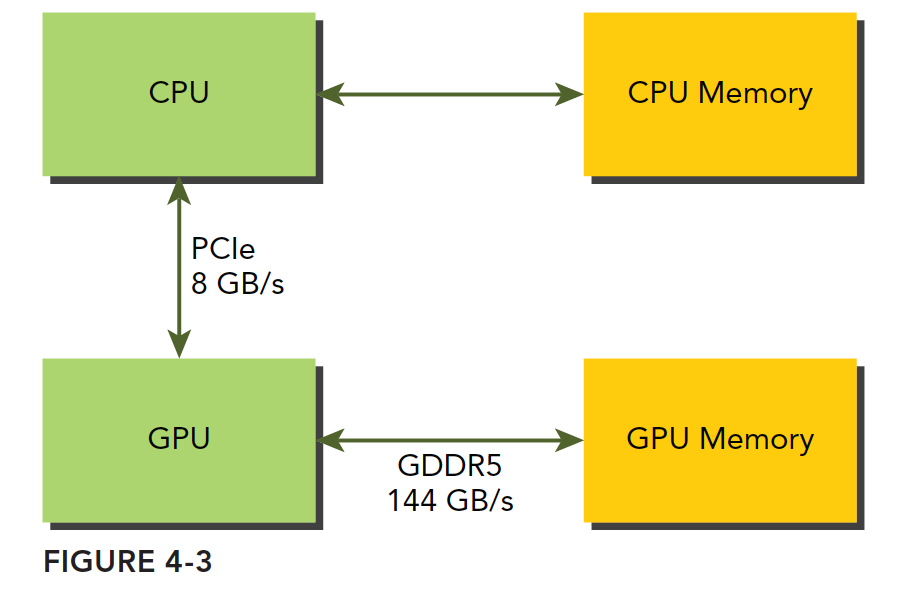
主机内存是分页管理的,一块内存可能在不连续的页上,可能发生物理换页,为了避免传输操作中出现换页,CUDA驱动会锁定页面,或分配固定的主机内存,再进行两次数据移动。
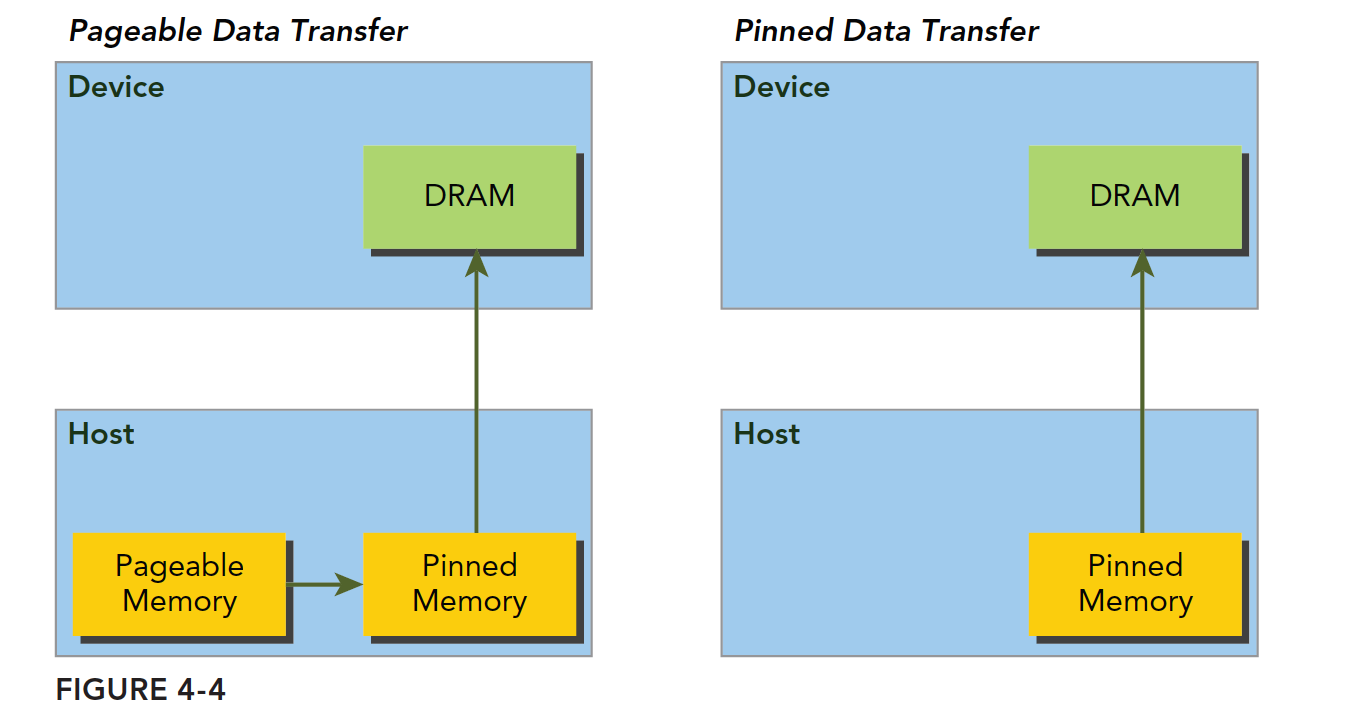
左侧就是两次数据移动。如果要使用右侧得到预先分配固定内存,需要使用以下函数:
1 | cudaError_t cudaMallocHost(void ** devPtr,size_t count) |
这些内存的数据可以直接传输到设备,因此memcpy的时间比主机普通malloc内存进行传输的时间更短。但是这样的固定内存的释放和分配成本比可分页内存高,而且会影响实际的可用物理内存空间。
3.2.2零拷贝内存
一般情况,主机不能访问设备内存,设备不能直接访问主机内存,但零拷贝内存是个例外。GPU可以直接访问零拷贝内存,这部分内存在主机内存。
零拷贝内存是固定内存,不可分页,并且使用时要注意与主机的内存竞争。使用以下方式分配:
1 | cudaError_t cudaHostAlloc(void ** pHost,size_t count,unsigned int flags) |
- cudaHostAllocDefalt
- cudaHostAllocPortable
- cudaHostAllocWriteCombined
- cudaHostAllocMapped
cudaHostAllocDefalt和cudaMallocHost函数一致,cudaHostAllocPortable函数返回能被所有CUDA上下文使用的固定内存,cudaHostAllocWriteCombined返回写结合内存,在某些设备上这种内存传输效率更高。cudaHostAllocMapped产生零拷贝内存。
零拷贝内存虽然不需要显式的传递到设备上,但是设备还不能通过pHost直接访问对应的内存地址,设备需要访问主机上的零拷贝内存,需要先获得另一个地址,这个地址帮助设备访问到主机对应的内存,方法是:
1 | cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags); |
FLAGS必须为0,。零拷贝内存比设备主存更慢,在CPU和GPU共用内存等特殊情况下才有较好的表现。
3.2.3统一虚拟寻址
在设备架构2.0后,NVIDA提出了UVA,设备内存和主机内存就都映射到相同的虚拟内存地址空间,使用上面的零拷贝内存,就不需要获取DEVICE POINTER了。
3.2.4统一内存寻址
设备在6.0版本后,NVIDIA又提出了统一内存寻址。统一内存中创建一个托管内存池,内存池中的空间可被主机和设备用相同指针访问。底层系统会自动进行设备和主机间的数据传输,是完全透明的。 在后续小节会介绍统一内存寻址。
3.3 内存访问模式
许多应用都是访存受限型,最大程度的利用全局内存的高带宽是非常重要的。前述的执行模型已经说明了cuda执行的基本单位是线程束,本节要研究的是线程束对全局内存的访问情况。
全局内存在硬件上大致是下图所示。
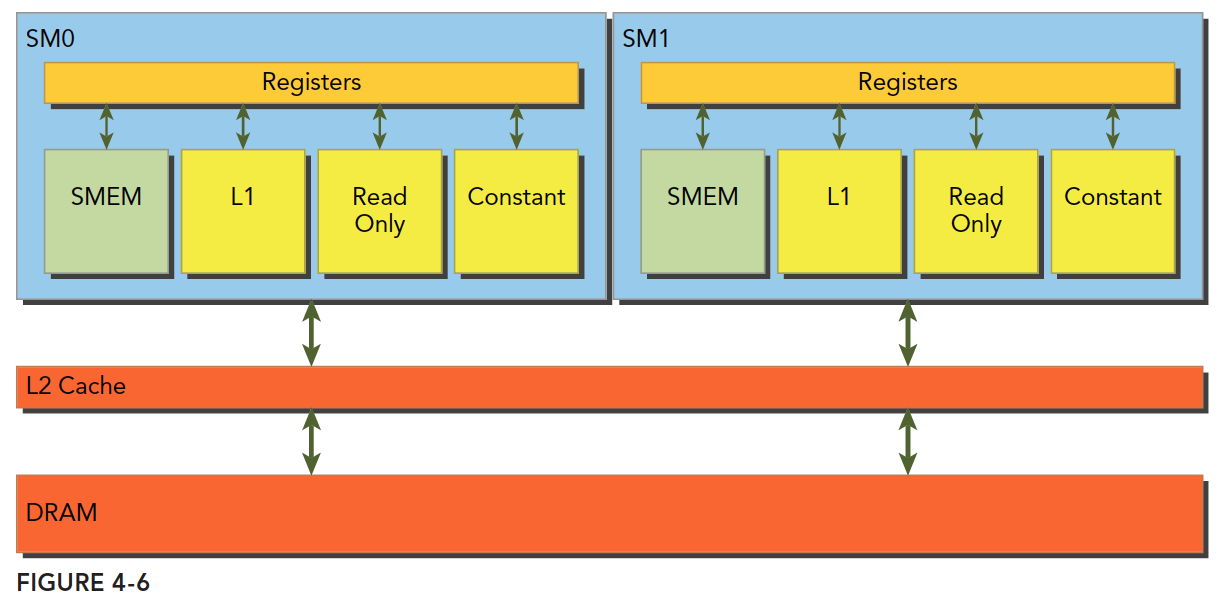
SM独占L1,共享L2,还有常量缓存和只读缓存。
核函数从全局内存读取数据只有两种粒度:32字节 / 128字节。(有点类似缓存行)
如果启用一级缓存,加载数据的粒度为128字节,如果通过编译指令停用L1只用L2,粒度是32字节。
SM执行的基础是线程束,只要有一个线程访存,其他31个线程也要访存,因此最小粒度是32。
在优化内存访问的时候关注的是两个特性:
- 对齐内存访问
- 合并内存访问
以下图为例,如果访存刚好是128-255,一次访存就可以

如果是127-255,就会需要两次(0-127和128-255),用利用率来衡量的话,取得数据只有一半是用到的,利用率只有一半。更极端的场景下,利用率最低只有1/128。
全局内存读取
尝试从全局内存读取数据的过程为L1->L2->DRAM,编译选项-Xptxa -dlcm=cg会关闭L1,访存直接从L2开始,有些GPU的L1只用来存储溢出的寄存器,不用来缓存。
下面是一些访问缓存的对齐情况,非常直观所以不做说明。





没有L1缓存的情况是类似的,只是粒度变成了32,好处是可能提高利用率,尤其是对上述的第五种分散访存的情况。
只读缓存
只读缓存最初是留给纹理内存的,但在3.5以上的设备,只读缓存也可以和L1一样缓存全局内存数据,粒度为32。有两种方法指导内存从只读缓存读取。
- 使用函数_ldg
- 在间接引用的指针上使用修饰符
1 | __global__ void copyKernel(float * in,float* out) |
全局内存写入
内存的写入和读取通常在缓存中有不同的策略。对于Fermi和Kepler GPU上L1不能用于写入,写入是从L2开始的,粒度同样为32.
结构体数组与数组结构体
AoS是数组,元素是结构体,SoA是结构体,成员是数组。显然对于GPU而言,每个线程访问的成员是一样的,如果使用AoS,数据是不连续的。使用SoA效果会更好。

3.4核函数可达到的带宽
在之前我们已经学习了两种方法改善内核性能:
- 最大化线程束的数量隐藏内存延迟
- 对齐和合并访问
如果内存访问模式本身是效率不高的,上述方式可能没有很好的效果,本节以矩阵转置为例来说明如何优化核函数的内存访问。
本节研究的二维矩阵的转置如下:
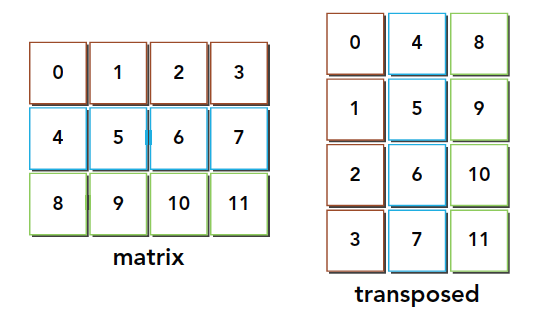
由于在内存中数据都是一维的,所以读取时数据是连续的,写入时将是分散的:
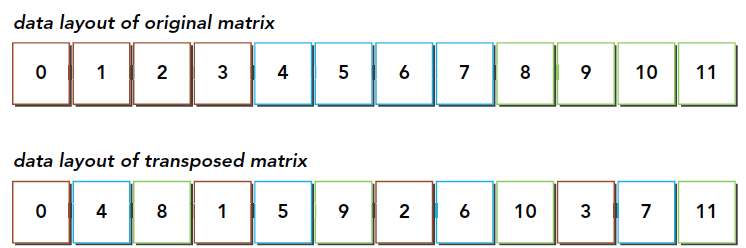
因此如果按行读取数据,就是连续读和不连续写,而如果按列读取数据,就是不连续读和连续写。
实际上,对于有限范围大小的数据,即便是非连续的读,数据也在L1中可以待后续读取使用。因此读取的利用率并没有那么低。但是反过来就不一样了,因为写入是不会写回到L1缓存,直接写回L2缓存的,因此写回是连续的效果会更好。
测量不同读写方式下的矩阵转置之前,需要知道GPU的理论带宽,才能知道利用了带宽的多少。这里直接使用babelStream来测量,当然不测量也是可以的,因为nsight compute提供的报告会有带宽利用率。
1 | git clone git@github.com:UoB-HPC/BabelStream.git |
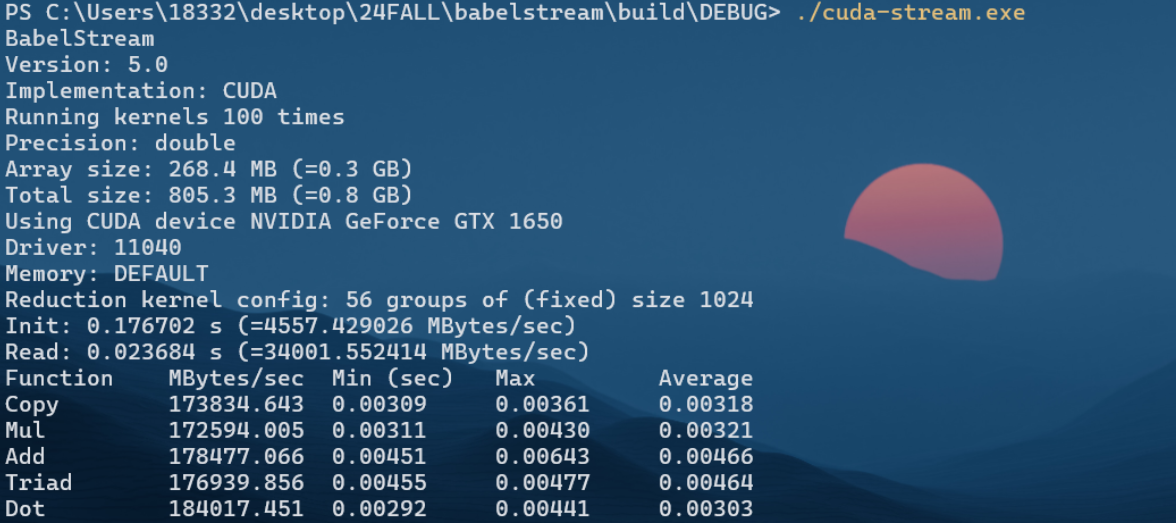
接下来就可以试试按行读取,不连续写入和按列读取,连续写入这两种方式的带宽:
1 |
|
差距是相当明显的。上面代码连续运行了两个函数,为了排除缓存的影响,实际测试时每次只运行其中之一:
1 | method 1:0.004210 |
连续读不连续写

连续写不连续读,显然写回的数据量有明显下降。内存吞吐量也有显著提升,利用的带宽明显比上一种高。

2.5节介绍了循环展开,对于转置这个例子也尝试进行展开,然而性能却没有什么变化,这里个人认为是因为这个核函数主要是访存受限,而循环展开在访存上并没有显著提升。我尝试运行了作者的代码,也没有性能提升,和原文记录的数据不符。
另外一个优化尝试是调整块的大小,发现调整块大小为8*32,在两种方式上都有显著提升,在第一种方法上性能甚至翻倍了。通过nsight comput可以看到是L2写回主存利用的带宽大大提升了,这里很可能是因为L2是共享的,并且写回的性能比读的性能更关键,减小块的大小,有利于写回时命中L2,从而实现更高的写入带宽。
8*32的连续读不连续写,核函数的时间为1.7msec。

8*32的连续写不连续读,吞吐量甚至略超过了babel stream测量的带宽,时间为1.5msec。

最后书上还提到了DRAM的读取如果太集中可能会排队,可以考虑让相邻的线程块映射到不相邻的数据块,避免这个问题。不过这个问题根据参考博客,是否真实存在存疑,并且上述修改块大小后,吞吐量已经略超过带宽峰值,应该不会有显著性能提升了,这里也不做测试了。


