Qwen3.5 Gated Delta Linear Attention
Qwen3.5采用了混合注意力机制,每四层注意力中,有三层是Gated Delta Attention,一层是带门控的Full Attention。GDN是一种线性注意力机制,要理解其结构,要从理解线性注意力机制开始。
1 线性注意力机制
在标准的Attention机制当中,我们执行的是:
这其中,Q是[seqlens,nhead,headdim]的张量,K和V则是[seqlens,nkvhead,headdim]的张量,计算复杂度是$O(S^2d)$。S表示seqlen。
对于$QK^TV$这三个矩阵的运算,如果没有softmax和因果掩码,则可以根据矩阵乘法结合律来先计算$K^TV$,这样就变成了Q乘上一个[headdim,headdim]的矩阵,整体的复杂度是$O(Sd^2)$,时间复杂度和序列长度是线性关系,这就是线性注意力机制的根源。
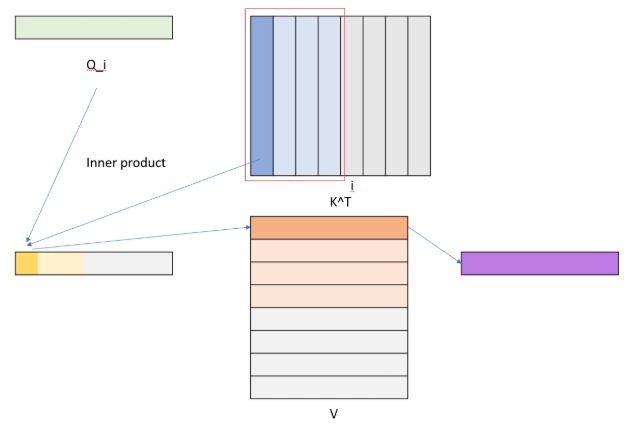
先暂时不考虑去掉softmax的影响,我们首先要把因果掩码加回来,这一点上,我们把QK^TV这个计算做一个拆分,按照每个token来考虑,每个Qi先和Kj计算注意力分数,然后和V的向量j乘,得到结果的一个分片。
公式上表示为:
注意力分数作为标量可以移到后面去(vj移到前面将被视为列向量),而向量内积可以交换位置(交换后q_i为列向量,kj^T为行向量)
从而得出我们的Oi可以根据累积的v和k得到:
累加矩阵被定义为Si,由v和k的外积构成,由于kj本来就是以行向量存储在内存当中,所以读取的时候可以直接把他按照行向量读进来,而v则需要转置。
这样只要保存状态矩阵S,每次计算oi时更新Si,同时以线性复杂度计算注意力。v是[seqlen,nkvhead,headdim],k是[seqlen,nkvhead,headdim],向量一一对应做外积得到[nkvhead,headdim]的S。
上述的这种累积式逐步更新的S解决了因果掩码的问题,但是softmax被去掉的问题仍然还在,在常规注意力机制下,softmax会通过指数运算重点保留注意力高分的位置,再通过V得到结果,去掉softmax后,所有的K和V的信息都不经缩放累加到了S上,导致信息模糊。有不同的处理办法来解决这个问题,典型方法包括:
- 添加衰减因子:$S_t = \lambda S_{t-1} + v_t k_t^\top$
- 门控机制
- 更复杂的核函数来映射q和k
2 Gated DeltaNet linear Attention
针对信息模糊的问题,DeltaNet提出了一种通过取出旧的value,删除旧的kv外积,再写入融合后的外积的方法,来控制信息的写入和更新。
怎么取出之前的v呢,假设 S 矩阵目前只存入了两对信息:$(k_1, v_1)$ 和 $(k_2, v_2)$。那么当前的S为:
可以用当前的k来检索,假设当前k是k3:
得到的就是我们认为的需要消除的旧记忆,在更新S的时候,要去掉这部分旧记忆,而新的vt则是旧的v值和新的v值的一个根据β控制比例的融合,和k^T做外积计算累加到S上。

根据上图描述,DeltaNet可以展开,提取公因式紧凑的写为:
Gated DeltaNet进一步引入了遗忘门,来控制信息的衰减,其S的更新进一步添加了α参数,变为了:
3 Qwen3.5 GDN
之前的介绍只是介绍了GatedDeltaLinearAttention的S更新原理,实际的Qwen3.5线性注意力机制要包含更多内容,比如在下图中,我们可以看到QKV会先进行一个kernel为4的Conv1D + SiLU,这一步是为了补偿线性化导致的表达能力下降,关于其具体的原因, 为什么线性注意力要加Short Conv?中给出了进一步的解释,不过对于infra或者说inference的角度来说,恐怕还是有点难理解,这里我们就浅显的理解为是为了通过交互周围的token,来提高表达能力。
这张图看过去,除了上述的Conv1D,还有一些其他值得注意的地方,这些有些是linear Attention的常见技巧,如果是第一次了解一种linear attention,可能不太熟悉
- Q和K的维度是相同的,而V的head更多:V决定读写什么内容,可以用更多的 value heads 提升表达能力/通道数,同时是 per-value-head 的门控参数:让不同 value heads 即使共享,也能用不同的衰减/更新强度形成差异化记忆[2]。
- 新的参数:A_log,delta_bias,两个向量参数
- 衰减因子的定义:α=exp(g),g = -exp(A_log) softplus(a + delta_bias)
- QKV之外的投影:
- b,学习率β=sigmoid(b)
- a,用于衰减因子g的生成,图里的A Proj对应的是下面的a,与A_log无关
- z,用于门控
- L2Norm:防止Q和K数值爆炸
- 输出门控与归一化:使用 RMSNorm 和门控处理输出。
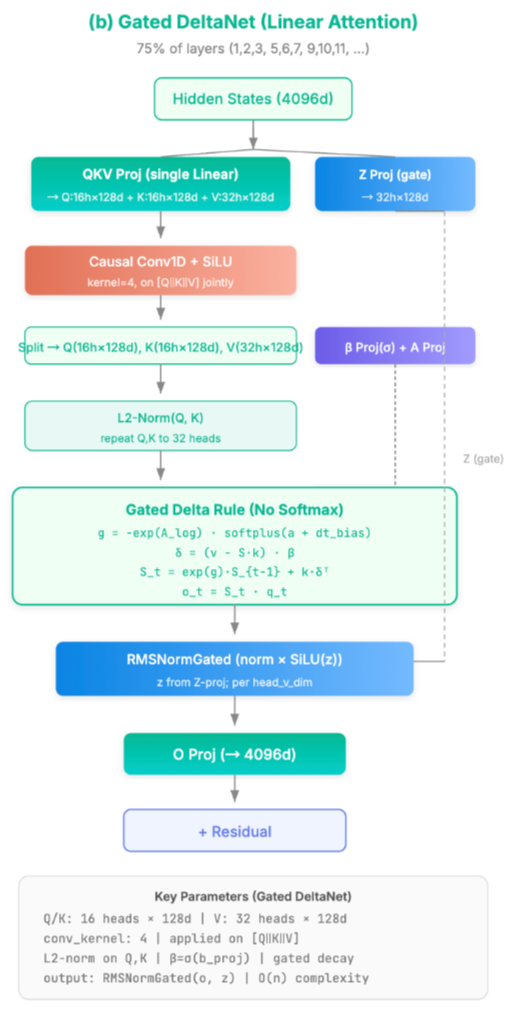
结合第2节的公式以及上述的补充,Qwen3.5的Gated Delta linearAttention的大体计算流程就可以理解了。下一小节,我们再结合代码看一下GDN计算的流程。
4 GDN
在site-packages/transformers/models/qwen3_5/modeling_qwen3_5.py下,可以看到GDN的具体计算过程。我们逐步来过一遍计算过程中的tensor变化,以qwen3.5-0.8b为例。
输入的tensor为[B, S, d]
1 | def forward(self, hidden_states, cache_params=None, cache_position=None, attention_mask=None): |
对QKV的投影:
1 | mixed_qkv = self.in_proj_qkv(hidden_states) |
对于0.8B的qwen3.5,num_k_heads和num_v_heads都是16,更大尺寸中,k的头数会少于v的头数,后面的计算会需要repeat k。
接下来是门控和参数的投影,b和a对于每个头来说是标量
1 | # z: 输出门控分支,用于最后的归一化融合 |
casual conv:
1 | if use_precomputed_states: # Decoding 模式 (推理阶段,seq_len=1) |
卷积后的QKV拆分:
1 | mixed_qkv = mixed_qkv.transpose(1, 2) # 恢复形状 (B, S, 6144) |
衰减和学习参数的计算:
1 | beta = b.sigmoid() # (B, S, 16) 范围 (0, 1)。作为写入权重,决定当前信息存入状态的比重。 |
GatedDeltaRule,结合之前的流程图,可以注意到QK的l2norm被融合到了该算子当中去
1 | if not use_precomputed_states: # Prefill |
- core_attn_out:
(B, S, 16, 128)。注意力机制提取后的特征。 - last_recurrent_state:
(B, 16, 128, 128)。这是一个庞大的二阶状态矩阵,存储了关联记忆。
最后是门控的处理:
1 | # 展平准备进入高效的 Norm 算子 |
5 recurrent Gated Delta Rule
这通常是decode阶段的更新,因为这个阶段我们并不需要考虑seq维度的累加,但是其对于prefill阶段也是适用的,只要迭代更新seqlen次。对于输入,首先做qknorm,并把H调整到前面[B, H, S, Dk]
1 | initial_dtype = query.dtype |
状态的初始化,如果有存储了last state,那么会通过initial_state传入
1 | core_attn_out = torch.zeros(batch_size, num_heads, sequence_length, v_head_dim).to(value) |
状态更新,其实如果是普通的每个batch一个token的decode,这里的seqlen应该是1,q_t等是取出第i步的长度为head_dim的向量 [B,H,head_dim]
1 | for i in range(sequence_length): |
Reference
[1] Gated DeltaNet :Qwen和Kimi都在用的线性注意力机制 - Vinci叽里呱啦的文章 - 知乎 https://zhuanlan.zhihu.com/p/1971671251123705351
[2]【LLM】Qwen3.5解剖 - Plunck的文章 - 知乎 https://zhuanlan.zhihu.com/p/2005306558997882654
[3] 以Qwen3Next为例,从Inference视角学习LinearAttention - CodeLearner的文章 - 知乎 https://zhuanlan.zhihu.com/p/1993467979799732563