
ICT鲲鹏性能挑战赛复盘
ICT鲲鹏HPC性能挑战赛赛后复盘,虽然拿到了一等奖,但是犯的错误很多,有必要进行复盘。
题目一
Hypre求解优化。核心优化是使用了粗化策略,使求解网格规模更小,以及调整其他配置,在setup时间和solve时间取得均衡。赛后与其他队伍交流发现在编译配置上还有其他可优化的内容,没有发现的原因是后期走入了读热点优化的误区,热点部分并没有优化空间,另外配置的一些测试赛前没有仔细整理,导致有忽略的内容。
题目二
实现SME求解HGEMM。优化方法如下,有一些提升指的是相对于整体性能,有可见的超过10%GFlops的提升。
- 线程并行:最外层,GOTO算法的线程并行策略是内层分块,但是经过我们赛前自行实测和赛中测试及其他原因,外层内层差别不大,不是限制性能的主要原因。
- 分块策略:GOTO算法的6层分块,单次计算的矩阵块(对N、K、M维各切分一次后)包括A块+B块+C块使用了1/2 的L2 Cache,SME单次计算的micro Kernel的数据量4/5 L1 Cache,计算数据不超过Cache大小是大幅度影响性能的最关键因素。
- 向量化打包:由于SME计算的读取连续性,数据需要打包为Z/N型的块,在此过程中数据不连续,采用了SVE的zip指令等来做打包,性能有一些提升。
- SME计算:一次计算了一块A×两块B,用了两个ZA tile同时计算,因为最内部的计算是沿着K方向进行的,ZA tile的累积有顺序,所以不这么做是无法利用所有ZA tile的,使用后性能有一些提升。
优化空间/比赛中犯的重大错误:
- 一开始由于习惯行主序,把分块按行主序写了,实际上后面采取的打包和计算顺序,都是列主序更友好的。最后修改了一个kernel到列主序,有一定的性能提升,一开始就全都采用列主序比较好,或者采用行主序,但是分块划分的顺序可以进行调整,让打包和写回能尽量顺着存储方向移动。猜测改正这一点性能会有一些提升。
- 错误的使用了ZA tile的数量:由于实现的是FP16×FP16的矩阵乘法,错误认为ZA tile只有两个可用,但是实际上实现的FP16×FP16使用的是SMEFP16FP32,也即输入为FP16,输出为FP32,那么累积计算结果使用的ZA tile应该是FP32的大小,所以应该是4个,这应该是导致我们第二题没有拿到第一的关键原因,因为使用4个ZA tile可以一次计算4个C的块,同时读取使用两行组A,两行组B,更好得进行数据重用和利用寄存器。这也是比赛中犯的最大错误和最大遗憾,虽然不影响结果,但还是觉得没有做到完美,不该犯这种错😭。
只用了两块ZA tile,假设mc,nc为2*SVL(寄存器长度):
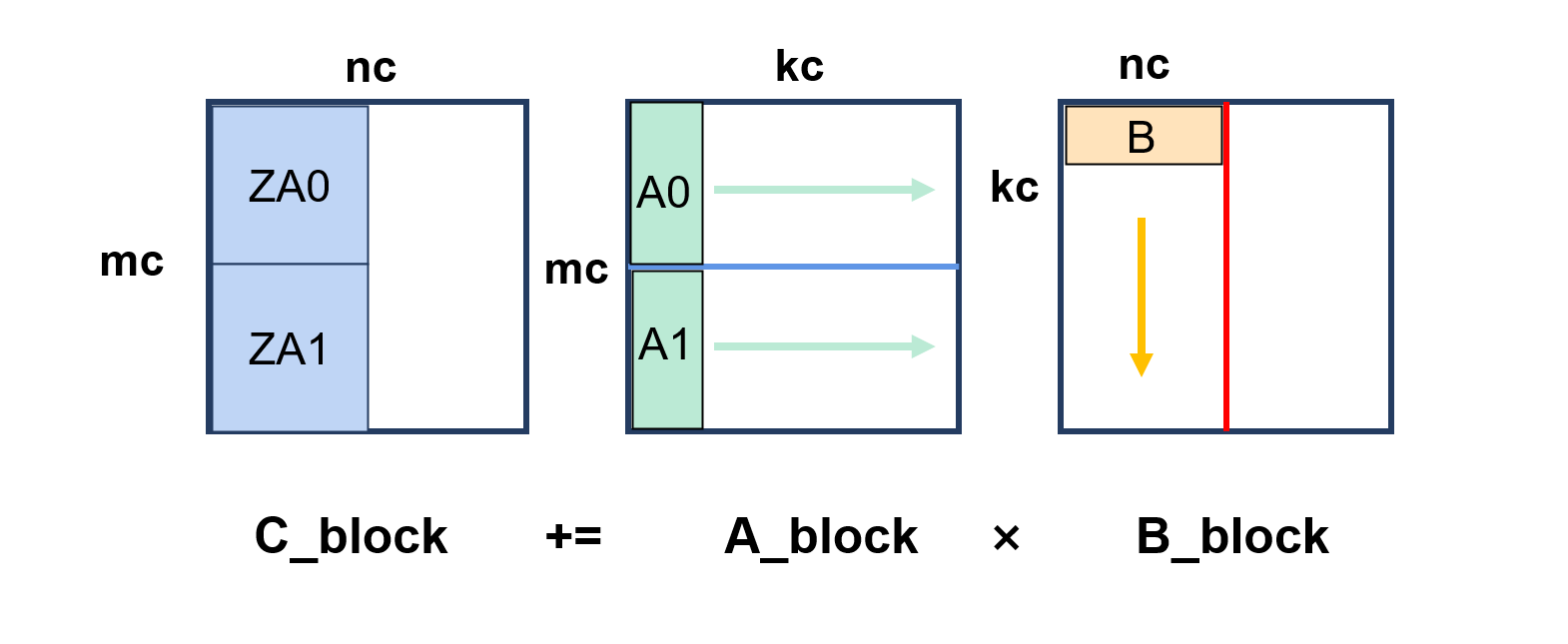
最后还有比赛中没遇到的一个问题,就是其他队伍提到了编译SME会有错误,但是我们按照测试框架编译测试代码是没有问题的,怀疑可能是我们是在给定软件包外独立安装了编译器编译,所以没遇到这个问题,无法再去弄明白了。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 橙的笔记本!


