高级计算机网络-测量
网络测量
1 FlowRadar
1.1 记录流量信息的常用数据结构
哈希表
哈希表有B个桶及相应索引,每个桶包含:
- flowID:例如一个五元组,用于标识网络流量
- Counter:计数器,记录流量的包数或字节数
一个流量 f 由索引为 h(f)%B 的桶进行跟踪。当流量 f 的一个数据包到达时,更新桶。在交换机上,使用链表解决冲突对软件来说成本较高,对硬件来说则不可行。
布隆过滤器
布隆过滤器用于近似决定一个元素是否属于某个集合。是一个包含 m 个位(bits)的数组,用于表示一个包含 n 个元素的集合 S。初始化时,所有位都设置为 0。使用 $k$ 个独立的哈希函数 $h_1, …, h_k$,每个哈希函数的取值范围是 $\{1, …, m\}$。每个哈希函数将集合中的每个元素映射到一个在范围 $\{1, 2, …, m\}$ 内的随机数。

检查值是否在S中的方式是是否K个bit全是1,如果不是,值一定不在S当中,否则认为在,但是不保证一定在。并且总是假定kn<m。

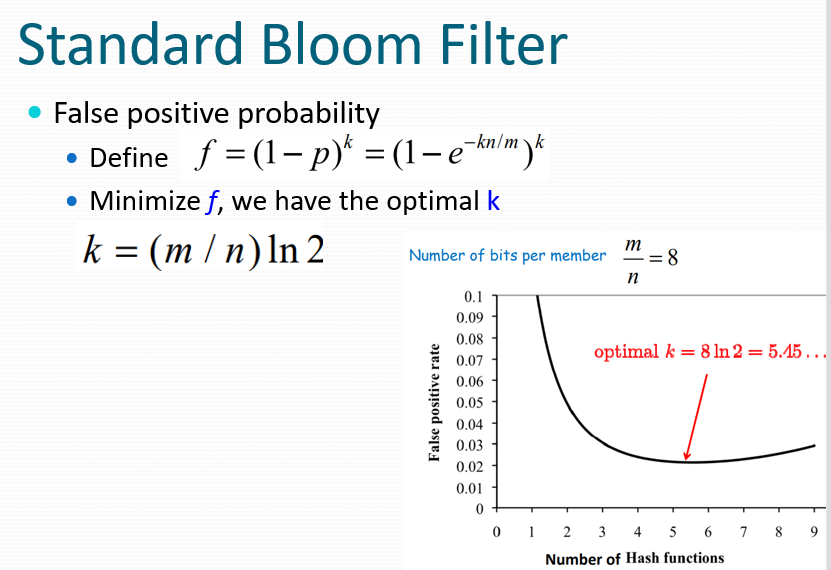
可以推出最佳的K值。
计数布隆过滤器
计数布隆过滤器的每个entry是一个值而不是一个位。当元素加入集合,计数位+1,删除时减一,查询时返回k个hash的最小计数值,如果是0,元素一定不在集合中。

1.2 概况
NetFlow是CISCO开发的监控网络流量的软件,在哈希表中存储流字段(例如,5元组)和记录(例如,数据包计数器、流开始时间、流最后被看到的时间等)。可以通过SNMP(简单网络管理协议)进行查询。其问题是:
- 移除旧流:需要扫描整个哈希表。当哈希表很大时,会消耗时间和CPU资源。
- 数据包处理:对于一个40Gbps的端口,每个数据包的处理时间为120纳秒,这不足以完成哈希表的读-比较-更新-写操作。所以只能采样,例如采样率为1/100,即只监控1%的流量。
FlowRadar的架构:
- 在交换机捕获编码的流量计数器:每个数据包具有恒定的插入时间,使用固定内存。不进行采样,捕获所有流量。以小的时间尺度(例如,10毫秒)向收集器报告。
- 在远程收集器解码和分析流量计数器:
交换机将捕获的流量编码成流量集,并定期报告给远程服务器。远程服务器接收到编码的流量集后,进行解码,提取出流量和计数器信息。解码后的流量和计数器信息被发送到分析器进行进一步分析。
使用的场景包括:
瞬态环路/黑洞检测:在非常短的时间内循环或丢弃少量数据包。Netflow如果流量没有被采样,NetFlow可能会错过错误。而FlowRadar能检测到
匹配动作表中的错误:损坏导致数据包丢失。基于采样的NetFlow或sFlow的局限性:很难检测到这类错误。FlowRadar可以监控所有数据包,这类错误很容易被检测到。
- 每流的丢包情况:目的是理解网络内部的丢包情况。基于采样的解决方案(如NetFlow)无法捕获未被采样的流的丢包。FlowRadar可以直接获取所有流的每个流丢包率的整体映射。
- 实时攻击检测:例如,小规模的流量突发可能会触发TCP超时。NetFlow在长时间内计算流中的包数。FlowRadar可以在小的时间尺度上,例如10毫秒,进行计数。
1.3 设计
解决冲突的方法:使用布隆过滤器。不维护昂贵的链表,而是对冲突流的记录进行异或(XOR)操作。这种方法避免了在哈希表中为每个冲突维护链表的需要,从而节省了空间和处理时间。异或操作可以用来合并具有相同哈希值的流记录,因为它是一种可逆的操作,可以在需要时恢复原始记录。
编码流组
使用一个标准的布隆过滤器,检测数据包是否属于某个流。以及一个计数表,统计流计数器,每个表项记录FlowXOR,Flow Count,Packet Count。

当接收到流的时候,首先检查流是否存储在布隆过滤器中,如果是新流,加入过滤器,并更新计数表。如果是存在的流,更新Packet Count。

解码
singleDecode
交换机每一些ms后就会像收集器发送流组编码信息。首先查找只包含一个流的单元格,即单元格中的FlowCount等于1。对已解码的流执行哈希函数,以定位其他单元格,然后从单元格中移除该流,并继续解码更多的流。

NetworkDecode
在网络中的不同交换机上,可以采用不同的哈希函数集来处理流数据。这样可以增加解码的灵活性和准确性。如果一个流在一个交换机上的编码流集中无法解码,它可能在另一个交换机上的编码流集中被解码。这是因为不同的哈希函数集可能会产生不同的哈希值,从而帮助识别和解码流。
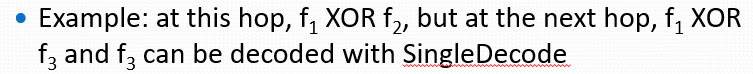
流集解码算法FlowDecode:


就是用已经从其他流集解码出的单流,在其他流集寻找是否出现,如果已经出现,就能将其移除,从而逐步解码。

上述算法可以解码流ID,但是不能处理packet counter,因为包可能丢失或者处于传输过程中。假设对于交换机S2,一个流集有mc个单元格和n个流,通过解mc个方程来求解n个变量。可以使用Matlab或其他工具来解这些方程。加速方法:如果一个流出现在S1和S2中,并且其计数器在S1上已被解码,那么可以在S2上使用S1上解码的计数器值来搜索方程的解。这个过程通过解方程来恢复每个流的数据包计数,利用已解码的计数器值来加速解码过程。
2 Elastic Sketch
2.1 背景
网络测量的内容:
- 有多少不同的流
- top-k的重流
- 给定流量的五元组,估计流量的大小,用于监控和管理流量
- 流量大小的分布
基于Sketch的测量,sketch包括:哈希表,Count-min,布隆过滤器,PCSA过滤器。
哈希表存储流的方式前面已经提到过了,主要介绍Count-min(CM)这个结构,CM有d行计数器数组,每行w个计数器,使用d个成对的hash函数将流量映射到每行的一个值。介绍到一个流的数据包时,更新每一行中相应的counter,估计流量的大小时,返回d行中的最小值。CM会因为hash碰撞而导致高估流的数据包数量,永远不会低估。这个数据结构适用于大数据流的流量计数,能够在有限的空间内提供对流量大小的快速估计。
通过合理设置 w 和 d,可以确保计数CM在指定的误差范围和概率内提供准确的估计。
Sketch方案的挑战:
- 需要有足够的带宽传输sketch:Sketches在交换机或host,需要传输到解析服务器,并且需要压缩,同时不能失去太多准确性
- 高数据包到达率:每个数据包到达时都需要更新,当数据包到达率很高时,需要丢弃不重要的信息以维持系统的高效运作。
- 不确定的流大小分布:流通常都是一部分elephants flow和大量mouse flow构成。我们通常对大流更感兴趣,需要动态分配空间应对变化的流
2.2 Elastic sketch
数据结构:
- 对于重流:使用哈希表记录,每个桶包含flowID五元组,Positive votes (vote+): 属于该流的数据包数量,Negative votes (vote-): 其他流的数据包数量,flag:是否轻流的CM中包含这个流的vote+。
- 轻流:CM记录
插入
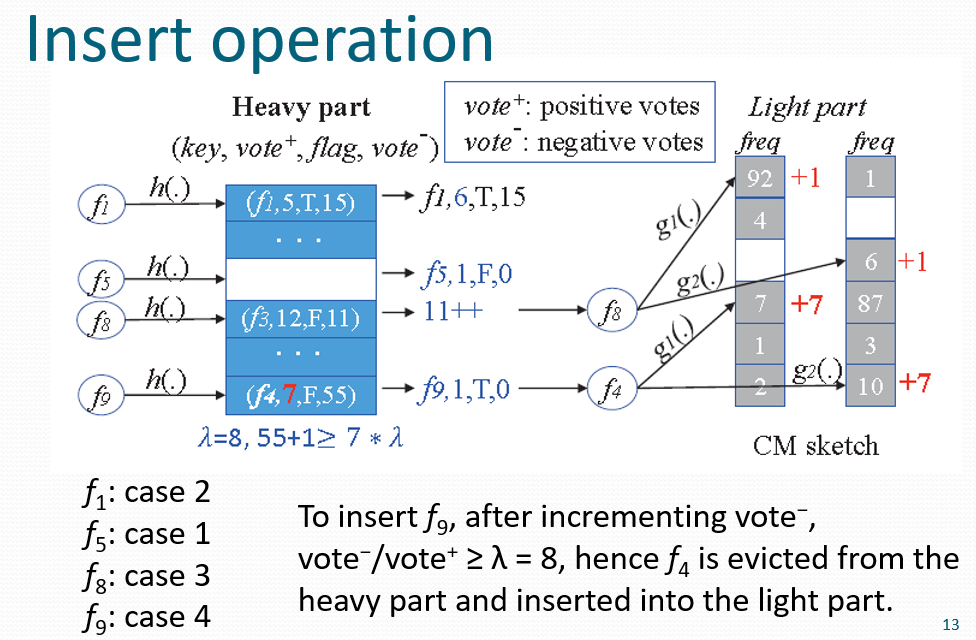
当接收到流f的时候,首先映射到hash表,分case处理:桶表示为(f1, vote+, flag1, vote-)
- 如果桶是空的,插入(f, 1, F, 0)
- f=f1,增加vote+
- f≠f1,vote-/ vote+< λ,增加vote-,将f更新到CM
- f≠f1,vote-增加后vote-/ vote+> λ,将f插入为(f, 1, T, 0),f1会成为victm,在CM中增加counter的值,加上vote+
查询
如果f不在heavie part,根据CM中的值返回
如果f在heavy part,flag是F,则直接返回vote+,否则返回vote+和CM的结果的和

压缩sketch的方式可以将A分成z个列组,将每个列组内的列合并,合并方式可以是求和或者压缩。这里的列组是跨步分组,而不是连续的列分为一组。


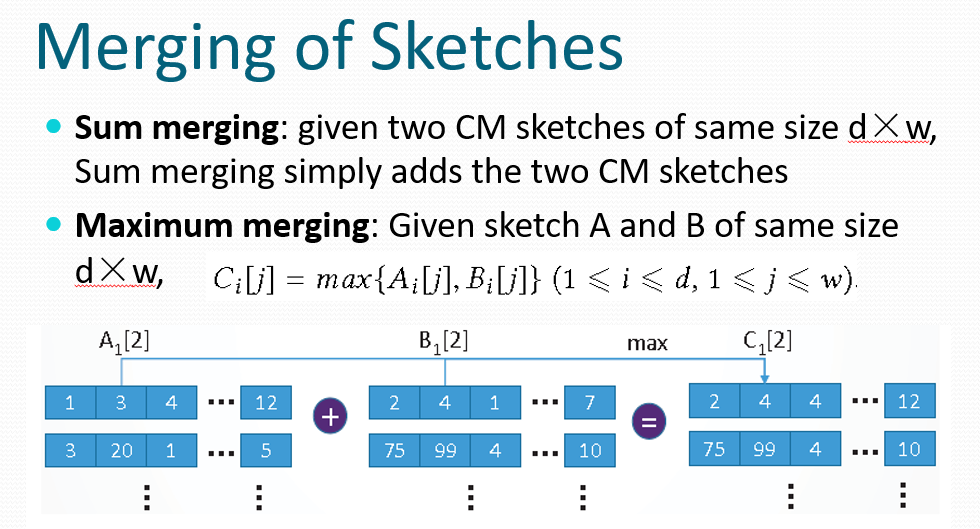
服务器会从测量节点接收到许多sketch,需要进行合并后发送给收集器。合并方式同样可以max或sum。
适配数据包达到率的方式,如果数据包在队列中的长度超过阈值:
- 只允许传入的数据包访问heavy part的处理
- 如果一个流被另一个流替换,直接用新流f的大小设置为原流的大小,例如:

适应流量分布:
- heavy part初始化较小内存
- 监视器确认如果vote+和vote-超出T2,就认为桶满了,并监察满的桶是否超出T1
- 拷贝和结合heavy part,改变流的映射
3 Loss Radar
LossRadar:快速检测到数据中心的丢包。
数据中心的丢包
网络测量需要快速检测(数十ms)到丢包,并且缩小原因范围。需要确定导致数据包丢失的设备位置,包括交换机、网卡(NIC)或主机。并需要捕获数据包头信息,包括5元组(源IP、目的IP、源端口、目的端口、协议),数据包ID。
大体来说,丢包有以下几种类别:
- 拥塞:由多个流量竞争同一输出端口引起,且总速率超过了该端口的容量。
- 持续黑洞:由于匹配-动作规则损坏,交换机持续丢弃符合特定“模式”的所有数据包。
- 瞬态黑洞
- 随机丢弃:交换机持续随机丢弃数据包且不报告,通常由组件问题引起,例如未正确安装的线路卡或故障链路。
Loss Radar设计的概念:
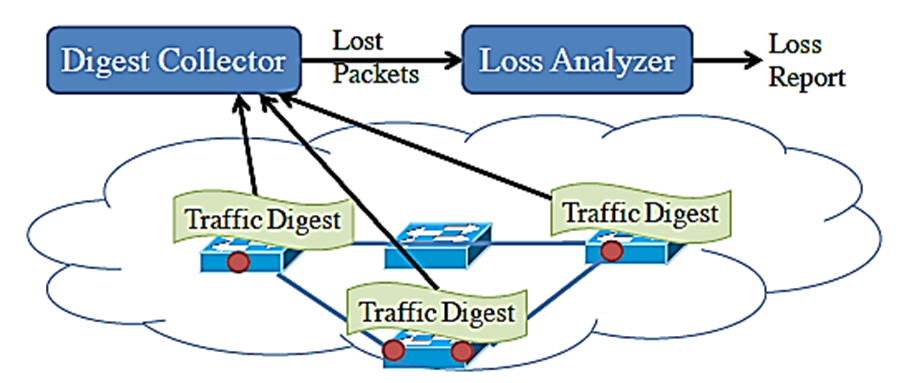
- 在网络中安装计量器(meters),以捕获单向流量。这些计量器位于流量进入和离开网络域之前和之后,称为上游(upstream)和下游(downstream)计量器。
- 每个计量器将数据包的唯一标识符编码成一个流量摘要(traffic digest),并定期将这些流量摘要报告给一个中央的LossRadar收集器。
设计的主要挑战:
- 需要保持摘要足够小,以减少存储、带宽和处理开销。
- 需要确定合适的位置来安装计量器,以便这些计量器能够覆盖整个网络。
- 需要开发能够快速识别丢包根本原因(如黑洞、拥塞和随机丢弃)的时间和空间丢包分析算法。
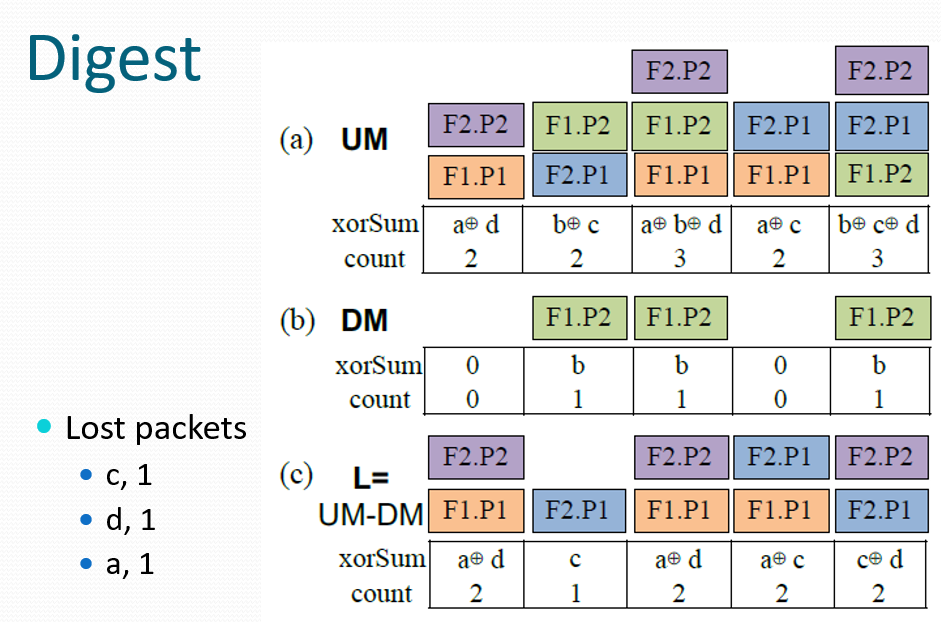
3.1 流量摘要
使用Invertible Bloom Filter (IBF),可逆布隆过滤器。
- 数据包x通过k个哈希函数(基于x.sig计算)映射到k个单元格。
- x.sig是数据包的唯一标识(如5元组和IP_ID等头部字段)。
- 每个单元格更新规则:
- 异或和:
xorSum = xorSum ⊕ x.sig - 计数器:
count = count + 1
- 异或和:
丢失数据包检测:通过比较发送端(UM)和接收端(DM)的摘要差异实现:
- 异或和差值:
L_i.xorSum = UM_i.xorSum ⊕ DM_i.xorSum - 计数差值:
L_i.count = UM_i.count - DM_i.count
若L_i.count=1且L_i.xorSum有效,则对应数据包可能丢失。
解码:
在差异摘要L中,找到计数为1的单元格(即count=1),称为纯单元格。此时,该单元格的异或和(xorSum)即为丢失数据包的唯一签名(x.sig)。根据哈希映射关系,将该数据包从所有k个关联的单元格中移除:
- 每个关联单元格的
xorSum更新为xorSum ⊕ x.sig - 每个关联单元格的
count减1
移除操作可能导致其他单元格变为纯单元格(count=1),需重复上述步骤,直到无纯单元格可解码。
LossRadar的优势:
- 摘要(digest)大小仅与丢失的数据包数量(nlost)成正比,而非总数据包量(ntotal)。
- 存储开销可预测且可控,适合大规模网络监控。
- 每个丢失数据包的摘要可包含丰富的网络层信息,例如:5元组(源/目的IP、端口、协议)中的流ID,用于精准定位通信流。IP_ID(数据包唯一标识)和动态调整的TTL。时间戳、载荷哈希等,便于后续分析。
丢包类型分类:
- 拥塞丢包:突发性丢包,连续丢包间的时间间隔极短(微秒级)。网络节点缓冲区溢出时,短时间内连续丢弃多个数据包
- 黑洞丢包:大流量特征:流内突发且连续的丢包。小流量特征:流内非突发但连续的丢包,且每个流仅丢失SYN握手包。本质问题:路由/防火墙策略错误导致流量被静默丢弃
- 随机丢包:核心特征:丢包事件在时间维度上均匀分布。常见原因:硬件错误、随机误码或负载均衡策略导致
- 环路丢包:识别标志:被丢弃数据包的TTL(生存时间)值为0。形成机制:路由环路导致数据包经过多次跳转后TTL耗尽
4 On-Off Sketch
针对持久性(Persistence)场景优化的新型sketch算法。
持久性定义
给定数据流中的项目e和T个非重叠连续时间窗口,e的持久性被定义为该项目在所有时间窗口中出现过的窗口数量。数学表达式为:
persistence(e) = |{t ∈ T | e appears in window t}|
典型应用场景:
- 攻击者通过长期维持低流量攻击规避传统检测,高持久性IP地址可能指示潜在攻击源
- 欺诈机器人会持续产生点击行为,高持久性用户ID可能对应虚假流量
核心研究问题:
- 如何高效计算特定项目在时间窗口序列中的出现频次
- 如何从海量数据中快速识别出持久性超过阈值的项目
4.1 2016 PIE
2016 PIE 提出的基础解决方案框架:
- 上层采用布隆过滤器(Bloom filter)进行数据去重:通过哈希映射识别重复元素(”0/1”二进制数组表示元素是否存在)
- 下层使用计数(CM Sketch)进行持久性估计:通过最小计数原理估算元素在时间窗口中的持续出现情况


4.2 On-Off Sketch
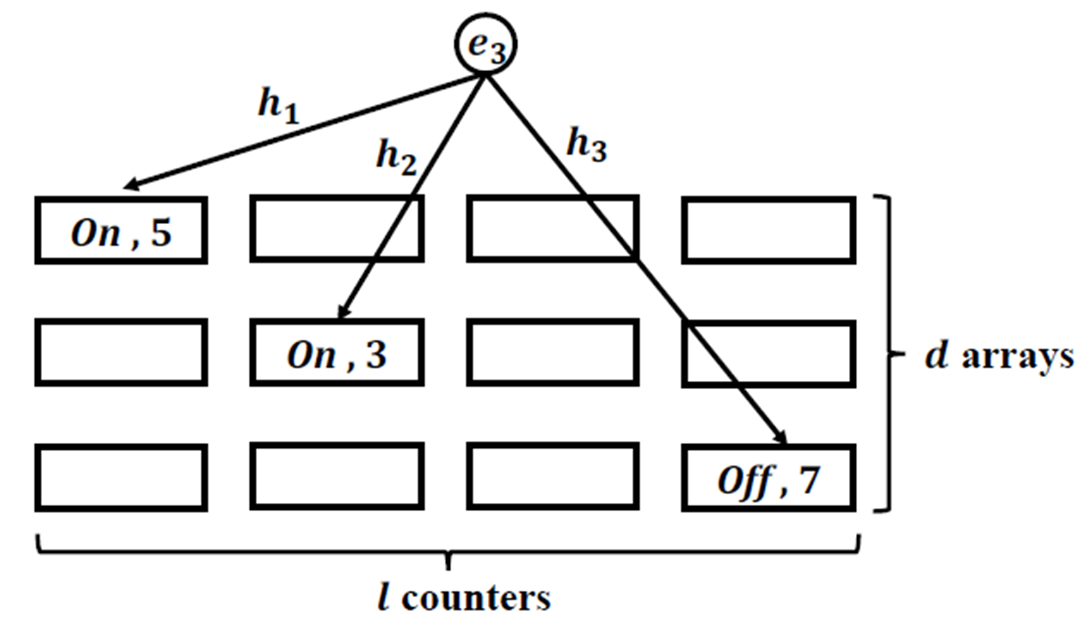
数据结构由d个独立数组构成,每个数组包含l个计数器,每个计数器包含计数值和一个On/off状态字段,初始状态所有计数器为0,状态字段为ON。使用d个独立的hash函数,映射到每个数组的位置。
插入与查询
对于待插入元素,计算hash值,将e映射到d个数组中的对应位置:
- 计数器状态为On:表示当前时间窗口内该计数器未被访问,计数器值+1,并将状态改为Off,实现窗口内去重(每个元素在单个窗口仅计数1次)。
- 状态为off:表示当前窗口已记录过该元素,保持计数器值和状态不变,避免同一窗口内重复计数
通过状态位(On/Off)显式区分不同窗口的计数,确保元素在每个时间窗口最多贡献1次计数,计数器总值反映元素出现的窗口数(持久性)。查询时取所有d个对应计数器的最小值。最小值策略可抑制哈希冲突导致的高估误差。
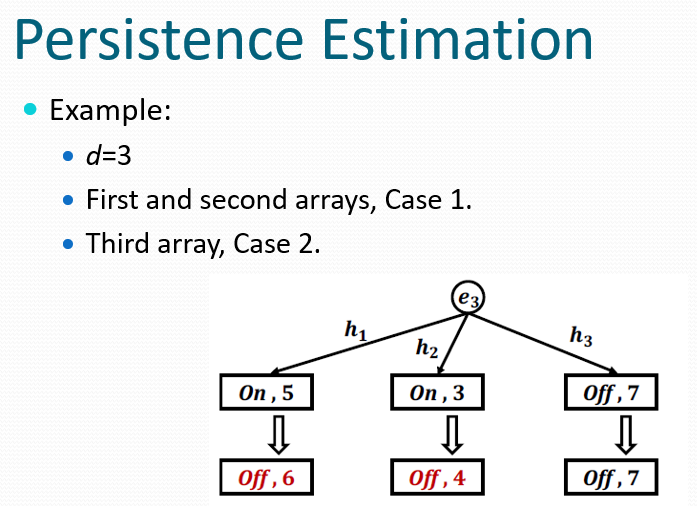
周期性重置机制:
每个时间窗口结束时执行:
- 将所有计数器的状态字段重置为”On”
- 保持计数器数值不变(跨窗口累积)
确定持久项
on-off sketch不会记录items的ID,设计了一个两部分的数据结构:
- 第一部分:l个counter的数组,每个counter有一个on/off状态,记录非持久项目的持久性。记为Ci
- 第二部分:一个有l个桶的数组,记为Bi,每个桶对应一个conter,每个桶有w个KV对,K是流的ID,值是对应的计数,并且也有一个On/off state。

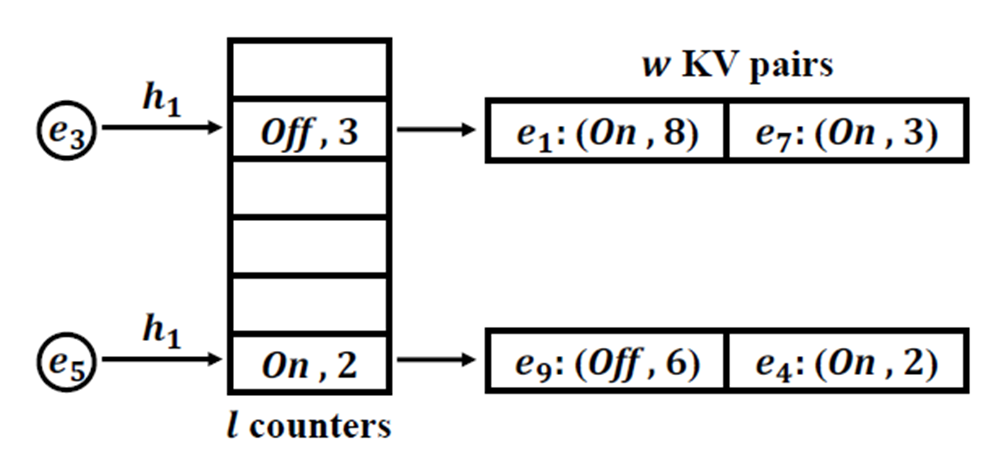
插入时如果e1哈希后记录在Bi,增加计数器,否则增加Ci,在插入后,比对Ci和Bi中的最小计数器,决定ei是否足够持久可以存储到桶Bi当中,并且如果大于最小计数的e2,那么会和e2交换位置。否则什么都不做。

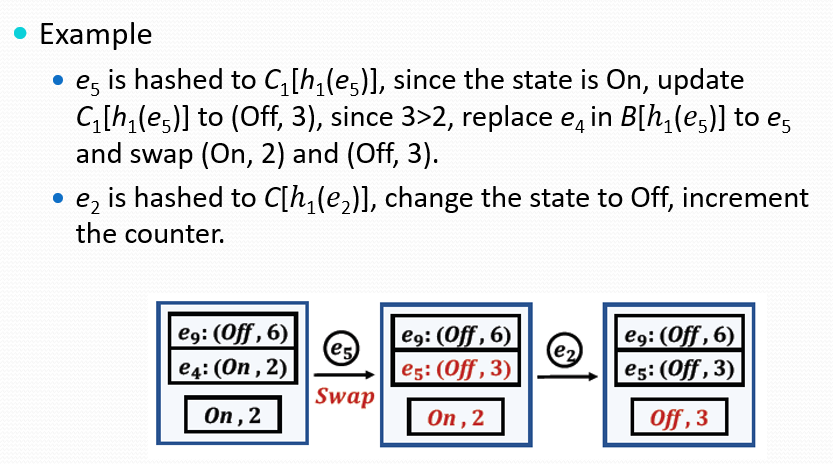
持久性查询时,遍历所有桶,检查每个计数器的值,当计数器值超过预设阈值时,记录对应项目ID。