__device__ inline voidcp_async(uint32_t dst, constvoid *src) { // .ca means cache to L1 and L2. .cg means cache to L2 only. // .cg only accepts cp-size=16 // .ca results in significantly slower kernel, probably because it uses up L1 resources // + additional copy, which is unnecessary, since we already manually cache it in shared memory. asmvolatile("cp.async.cg.shared.global [%0], [%1], 16;" ::"r"(dst), "l"(src)); };
voidmatmul_v2(const nv_bfloat16 *A, const nv_bfloat16 *B, nv_bfloat16 *C, int M, int N, int K) { assert(is_power_of_two(M) && "M must be a power of 2"); assert(is_power_of_two(N) && "N must be a power of 2"); assert(is_power_of_two(K) && "K must be a power of 2");
// A is row-major, B is column-major, C is row-major A += offset_m * K; B += offset_n * K; C += (offset_m + warp_id_m * WARP_M) * N + (offset_n + warp_id_n * WARP_N);
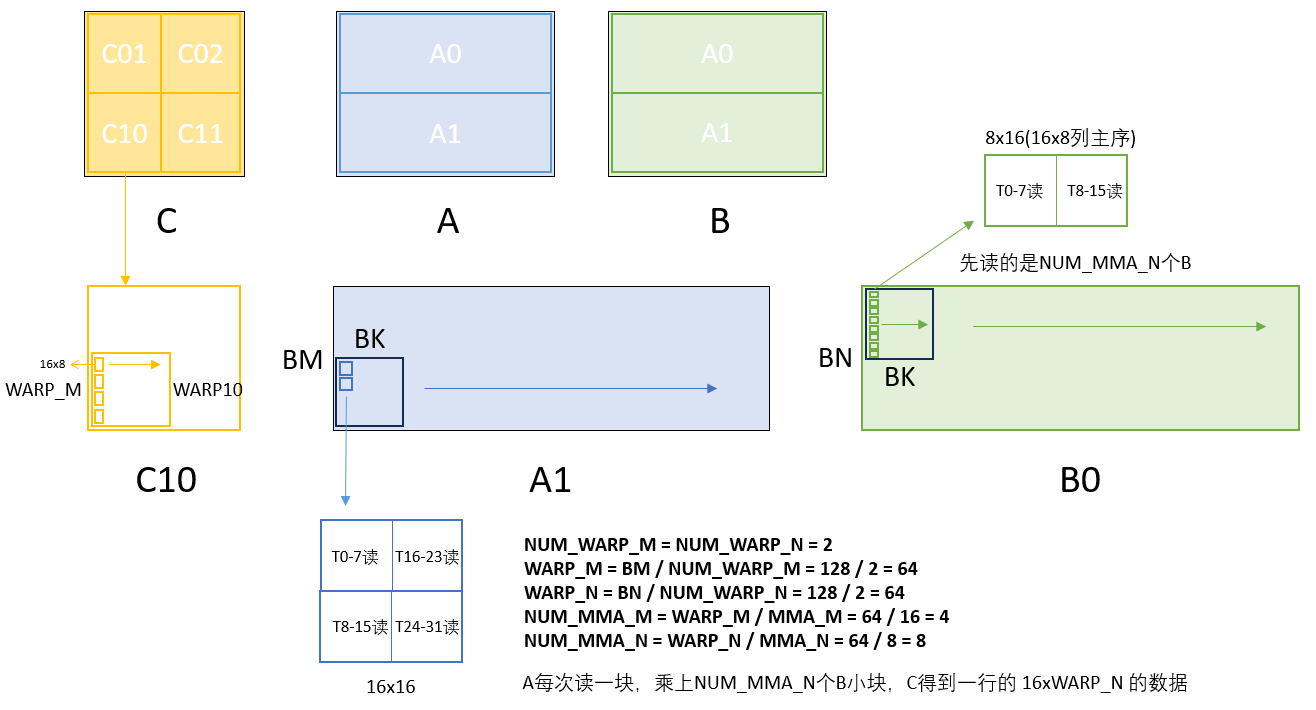
用于累加的寄存器是FP32的,所以每个线程需要的数量就是MMA_M * MMA_N / WARP_SIZE,而读取的A和B是BF/FP16数据存放在32位寄存器,所以要乘sizeof(nv_bfloat16) / 4。而用于累加的寄存器,由于迭代计算过程中,K是外层循环,M和N是内层,所以需要留出每个WARP计算的NUM_MMA_M x NUM_MMA_N个块。
1 2 3 4 5 6 7 8 9 10 11 12
// all registers are 32-bit (4-byte) // - we accumulate to FP32, which is exactly 32-bit // - our inputs are FP16/BF16, hence each register holds 2 elements // - inputs and accumulate are distributed across 32 threads in a warp // for m16n8k8, each thread holds // - 4 output float // - 4 input A FP16/BF16 // - 2 input B FP16/BF16 constexpr int num_acc_regs = MMA_M * MMA_N / WARP_SIZE; constexpr int num_A_regs = MMA_M * MMA_K * sizeof(nv_bfloat16) / 4 / WARP_SIZE; constexpr int num_B_regs = MMA_N * MMA_K * sizeof(nv_bfloat16) / 4 / WARP_SIZE; float acc[NUM_MMA_M][NUM_MMA_N][num_acc_regs] = {};
计算的部分是先读入B,然后轮流读入A,使用mma指令完成每个WARP负责的NUM_MMA_M x NUM_MMA_N 个块的计算。为什么先读入和存着B呢,这是一个寄存器使用数量上的考虑,因为mma计算的是m16n8k16,B用的寄存器对于单个mma来说少一些,所以暂存B的寄存器压力比较小,但是每个WARP要计算NUM_MMA_M x NUM_MMA_N个tile,对于当前配置:
for (int mma_k = 0; mma_k < BLOCK_K; mma_k += MMA_K) { // for m16n8k8 // <https://docs.nvidia.com/cuda/parallel-thread-execution/#warp-level-matrix-fragment-mma-1688> // A\\B [8x8-0] // [8x8-0] // [8x8-1] // where each [8x8] matrix can be loaded from shared memory with ldmatrix // <https://docs.nvidia.com/cuda/parallel-thread-execution/#warp-level-matrix-instructions-ldmatrix>
// select the tile this warp is responsible for const nv_bfloat16 *A_shm_warp = A_shared + (warp_id_m * WARP_M) * SHM_STRIDE + mma_k; const nv_bfloat16 *B_shm_warp = B_shared + (warp_id_n * WARP_N) * SHM_STRIDE + mma_k;
这里会注意到B在shared Memory当中是N x K存储的,这是因为mma m16n8k16要求row.col的输入,所以我们得把数据转置过来,这样ldmatrix不需要加.trans,直接读取到的就是需要的数据。这里并不需要在意本身的B是转置(列主序)还是行主序,只要搬运进来是NxK就对了,计算AxB^T,和计算Ax列主序的B是完全相同的,而行列主序仅仅只是步长有变化,在读入时global_to_shared_async传入正常的步长,就可以读到NxK的数据。
ifconstexpr(GROUP_M == 0) { // no swizzling bid_m = bid / grid_n; bid_n = bid % grid_n; } else { // threadblock swizzling to improve L2 cache hit rate // <https://triton-lang.org/main/getting-started/tutorials/03-matrix-multiplication.html> // each group is [GROUP_M, grid_n], tile from top (small M) to bottom (large M). // the last group might be shorter than GROUP_M if grid_m % GROUP_M != 0. constint group_size = GROUP_M * grid_n; constint group_id = bid / group_size; constint group_off_m = group_id * GROUP_M; constint group_m = std::min(grid_m - group_off_m, GROUP_M); // actual group height
// loop invariance: there is always NUM_STAGES - 1 prefetch stages in-flight // thanks to pipelining, this loop now only has 1 __syncthreads() for (int k_iter = 0; k_iter < num_k_iters; k_iter++) { // wait for previous MMA to finish using the shared buffer __syncthreads();
// prefetch the next stage. add 1 more stage to the pipeline load_AB(k_iter + NUM_STAGES - 1);
// wait for the 1st stage to finish. remove 1 stage from the pipeline // -> restore loop invariance cp_async_wait_group<NUM_STAGES - 1>(); __syncthreads();
// A shared->regs...
// B shared->regs...
// do MMA. NUM_STAGES-1 prefetch stages are still on-going }

/image-20260302172558660.png)
/image-20260302172607405.png)
/image-20260302172616776.png)
/image-20260302172627155.png)
/image-20260302172633650.png)
/image-20260302172728766.png)
/image-20260302172750756.png)
/image-20260302172754931.png)