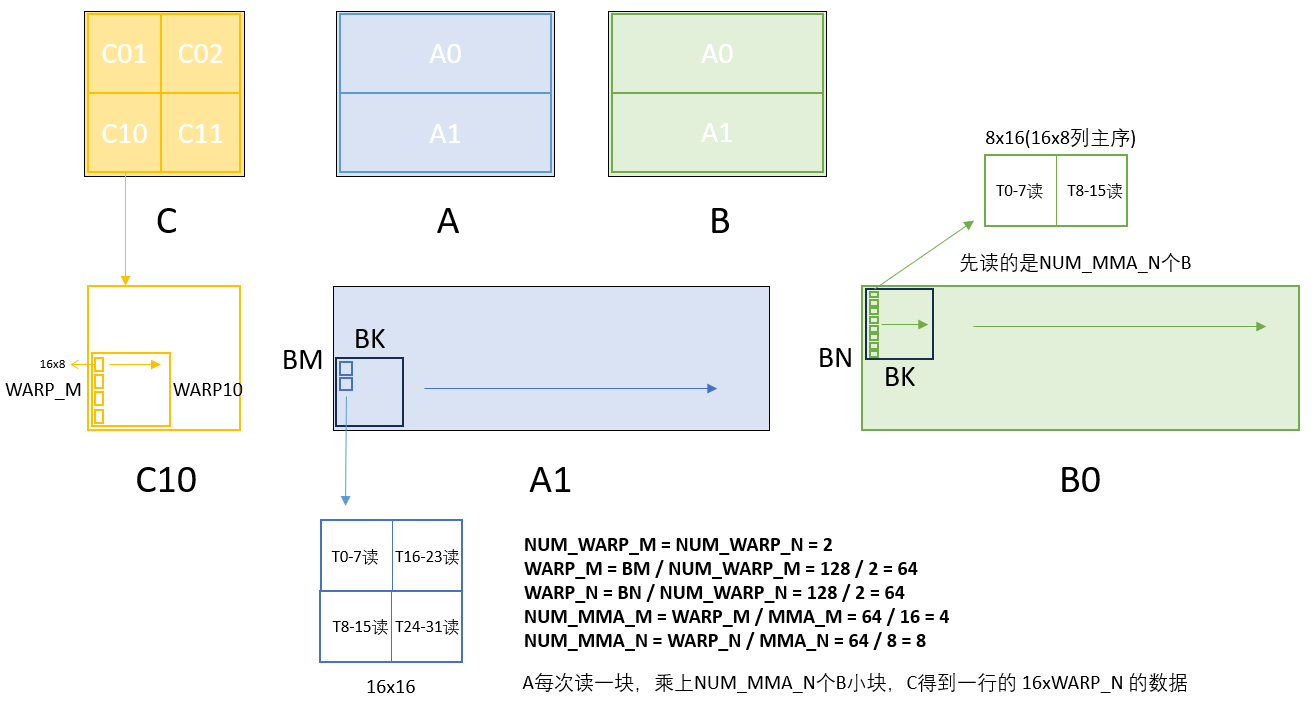
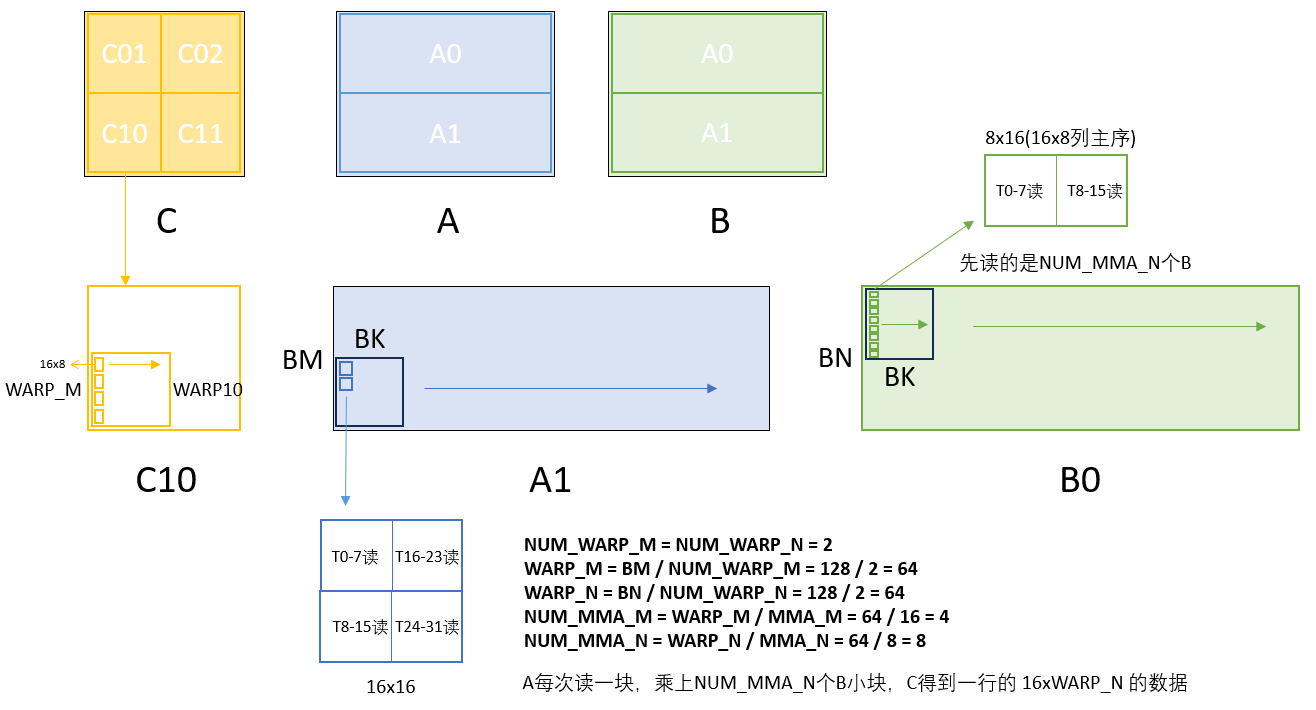
本篇是对SM120架构下Tensor Core GEMM实现的源码解读笔记。代码来源于仓库:
https://github.com/gau-nernst/learn-cuda
在上一篇中,我们已经看过了SM80的Tensor Core GEMM,通过基本的优化方法和对cp.async,在5060上实现了大约33TFLOPs的性能,大约是峰值的90%,距离cublas以及峰值还有一些差距,这些差距来自于没有利用TMA来进行数据搬运。
TMA是Hopper架构新增加的拷贝DMA引擎,目的是解决大块显存拷贝中的多次地址计算等操作。TMA支持大块bulk的异步显存拷贝,可以减少拷贝指令数量,并支持多维度的显存块拷贝,sharedMemoryGlobalMemory的异步数据拷贝。
对于SM120,没有SM100的TMEM以及tcgen05,2-SM-MMA等,只要充分利用SM90-TMA就可以达到峰值性能,因此在利用了TMA后,gemm实现可以实现峰值性能。本文是对代码仓库02c-sm120的解读。
仍然是从指令开始,逐步介绍gemm实现,一些之前sm80代码实现已经包含的优化不再单独介绍。
1 指令 ldmatrix等指令略过。
1.1 elect.sync elect.sync是用于从一个WARP中选出一个线程作为领袖线程的指令。因为TMA指令的发射是单线程完成的。单条指令设置的是谓词寄存器,指令原型如下:
1 2 elect.sync dest_mask | dest_pred, source_mask;
配合一个条件赋值,来让一个线程拿到pred=1。
1 2 3 4 5 6 7 8 9 10 11 asm volatile ( "{\\n" ".reg .pred P;\\n" "elect.sync _|P, %1;\\n" "@P mov.s32 %0, 1;\\n" "}" : "+r" (pred) : "r" (0xFFFF'FFFF ) ) ;
1.2 mbarrier mbarrier是在SM80就引入的指令,但在SM90中开始扩展加强并配合TMA广泛使用。接下来是相关的指令:
mbarrier.init是TMA搬运的初始化指令,这个指令会设置初始计数和barrier的初始状态。这个初始化只由领袖线程调用。
1 2 3 4 5 6 7 8 9 mbarrier.init{.shared::cta}.b64 [addr], count; __device__ inline void mbarrier_init (int addr, int count) { asm volatile ("mbarrier.init.shared::cta.b64 [%0], %1;" :: "r" (addr), "r" (count)) ; }
mbarrier.init初始化后,mbarrier.arrive表示达到的动作,相应的指令原型为:
1 2 3 4 5 6 7 8 9 10 mbarrier.arrive.release.cta.shared::cta.b64 _, [addr]; __device__ inline void mbarrier_arrive (int addr) { asm volatile ("mbarrier.arrive.release.cta.shared::cta.b64 _, [%0];" :: "r" (addr) : "memory" ) ; }
这条指令会更新屏障的计数器,如果计数器归0,则屏障已完成,停止mbarrier等待的线程。
SM90引入的加强指令就是基于arrive添加一个增量的拷贝数量,原有的arrive只统计线程数量,而mbarrier.arrive.expect_tx会增加一个字节计数器值,当TMA搬运了指定字节数量的数据,barrier才会到达。
1 2 3 4 5 6 7 mbarrier.arrive.expect_tx.release.cta.shared::cta.b64 _, [addr], tx_count; __device__ inline void mbarrier_arrive_expect_tx (int addr, int size) { asm volatile ("mbarrier.arrive.expect_tx.release.cta.shared::cta.b64 _, [%0], %1;" :: "r" (addr), "r" (size) : "memory" ) ; }
上述指令配合的一个典型工作流是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (elect_sync()) { mbarrier_init(bar_ptr, 1 ); mbarrier_arrive_expect_tx(bar_ptr, 2048 ); tma_copy_2d(dst, src, ..., bar_ptr); mbarrier_arrive(bar_ptr); } mbarrier_wait(bar_ptr, phase);
而mbarrier的等待如下所示,是一个轮询的过程,并可以通过phase控制相位。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 __device__ inline void mbarrier_wait (int mbar_addr, int phase) { int ticks = 0x989680 ; asm volatile ( "{\\n\\t" ".reg .pred P1;\\n\\t" "LAB_WAIT:\\n\\t" "mbarrier.try_wait.parity.acquire.cta.shared::cta.b64 P1, [%0], %1, %2;\\n\\t" "@!P1 bra.uni LAB_WAIT;\\n\\t" "}" :: "r" (mbar_addr), "r" (phase), "r" (ticks) ) ;}
1.3 TMA TMA指令的原型是cp.async.bulk.tensor,支持多维的数据拷贝,2d数据块的拷贝原型:
1 cp.async.bulk.tensor.2 d.shared::cta.global.mbarrier::complete_tx::bytes [%0 ], [%1 , {%2 , %3 }], [%4 ];
.mbarrier::complete_tx::bytes
[%0] dst: 共享内存的目标起始地址。
%1,指向 Tensor Map 的 64 位指针。
%2,%3: 张量的 2D 坐标 (x, y)。注意,这里是坐标 而非偏移量。
[%4] (mbar): mbarrier 对象的地址。
该条指令会根据Tensor Map描述的逻辑去进行地址映射,硬件自动计算真正的物理地址,做数据搬运,这也是相较于SM80的cp.async的重要的优化。
wrapper:
1 2 3 4 5 6 7 __device__ inline void tma_2d_g2s (int dst, const void *tmap_ptr, int x, int y, int mbar_addr) { asm volatile ("cp.async.bulk.tensor.2d.shared::cta.global.mbarrier::complete_tx::bytes " "[%0], [%1, {%2, %3}], [%4];" :: "r" (dst), "l" (tmap_ptr), "r" (x), "r" (y), "r" (mbar_addr) : "memory" ) ;}
2 matmul with TMA 1 2 3 4 5 M=4096, N=4096, K=4096 CuBLAS: 3.9797 ms 34.53 TFLOPS 95.58% SOL Inductor Triton: 3.8247 ms 35.93 TFLOPS 99.46% SOL v0: 3.8688 ms 35.53 TFLOPS 98.33% SOL cp.async v1: 3.8039 ms 36.13 TFLOPS 100.00% SOL TMA
2.1 init tensor map CutensorMap是一个描述符,描述tensor的size,步长等信息,以及搬运到sharedMemory的块和步长信息。在计算开始前,需要初始化CutensorMap。
rank:n Dimension张量,对于2D tensor,值为2
size:张量大小,最快变化维度到最慢变化维度,因此对于行主序数据,是width height
stride:步长,第一个维度默认是连续的,所以stride数组有rank-1个值
box_size:搬运到shared Memory的块大小
elem_stride:跳跃元素数,需要读取连续的数据时,都是1
CUtensorMapSwizzle:swizzle模式,和smem_width的字节数是对应的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 static void init_tensor_map ( CUtensorMap *tmap_ptr, const nv_bfloat16 *gmem_ptr, uint64_t gmem_height, uint64_t gmem_width, uint32_t smem_height, uint32_t smem_width ) { constexpr uint32_t rank = 2 ; uint64_t size[rank] = {gmem_width, gmem_height}; uint64_t stride[rank - 1 ] = {gmem_width * sizeof (nv_bfloat16)}; uint32_t box_size[rank] = {smem_width, smem_height}; uint32_t elem_stride[rank] = {1 , 1 }; CUtensorMapSwizzle swizzle = CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE; if (smem_width == 16 ) swizzle = CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_32B; else if (smem_width == 32 ) swizzle = CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_64B; else if (smem_width == 64 ) swizzle = CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B; auto res = cuTensorMapEncodeTiled( tmap_ptr, CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, rank, (void *)gmem_ptr, size, stride, box_size, elem_stride, CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE, swizzle, CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE, CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE ); if (res != CUDA_SUCCESS) { const char *error_msg_ptr; if (cuGetErrorString(res, &error_msg_ptr) != CUDA_SUCCESS) error_msg_ptr = "unable to get error string" ; std ::cerr << "cuTensorMapEncodeTiled error: " << error_msg_ptr << std ::endl ; } };
2.2 entrance 核函数的入口处进行init_tensor_map,传入初始化的A_tmap和B_tmap,并且需要为mbarrier的使用预留shared memory的空间,每个mbarrier占用8字节空间,需要nstage个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void matmul_v1 (const nv_bfloat16 *A, const nv_bfloat16 *B, nv_bfloat16 *C, int M, int N, int K) { assert(is_power_of_two(M) && "M must be a power of 2" ); assert(is_power_of_two(N) && "N must be a power of 2" ); assert(is_power_of_two(K) && "K must be a power of 2" ); const int BLOCK_M = 128 , BLOCK_N = 64 , BLOCK_K = 64 ; const int NUM_WARP_M = 2 , NUM_WARP_N = 2 ; const int NUM_STAGES = 2 ; auto kernel = matmul_v1_kernel<BLOCK_M, BLOCK_N, BLOCK_K, NUM_WARP_M, NUM_WARP_N, NUM_STAGES>; const int TB_SIZE = NUM_WARP_M * NUM_WARP_N * WARP_SIZE; const int grid_size = cdiv(M, BLOCK_M) * cdiv(N, BLOCK_N); const int smem_size = (BLOCK_M + BLOCK_N) * BLOCK_K * sizeof (nv_bfloat16) * NUM_STAGES + NUM_STAGES * 8 ; CUtensorMap A_tmap, B_tmap; init_tensor_map(&A_tmap, A, M, K, BLOCK_M, BLOCK_K); init_tensor_map(&B_tmap, B, N, K, BLOCK_N, BLOCK_K); launch_kernel(kernel, grid_size, TB_SIZE, smem_size, A_tmap, B_tmap, C, M, N, K); }
2.3 kernel 核函数的开头仍然是对形状和大小的检查,确保数据尺寸是可处理的,和SM80是完全一样的,block swizzle也在这里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 template <int BLOCK_M, int BLOCK_N, int BLOCK_K, int NUM_WARP_M, int NUM_WARP_N, int NUM_STAGES> __launch_bounds__(NUM_WARP_M * NUM_WARP_N * WARP_SIZE) __global__ void matmul_v1_kernel ( const __grid_constant__ CUtensorMap A_tmap, const __grid_constant__ CUtensorMap B_tmap, nv_bfloat16 *C, int M, int N, int K ) { constexpr int WARP_M = BLOCK_M / NUM_WARP_M; constexpr int WARP_N = BLOCK_N / NUM_WARP_N; static_assert (BLOCK_M % NUM_WARP_M == 0 ); static_assert (BLOCK_N % NUM_WARP_N == 0 ); static_assert (WARP_M % MMA_M == 0 ); static_assert (WARP_N % MMA_N == 0 ); const int tid = threadIdx.x; const int bid = blockIdx.x; const int warp_id = warp_uniform(tid / WARP_SIZE); const int lane_id = tid % WARP_SIZE; const int warp_id_m = warp_id / NUM_WARP_N; const int warp_id_n = warp_id % NUM_WARP_N; constexpr int GROUP_M = 8 ; const int grid_m = cdiv(M, BLOCK_M); const int grid_n = cdiv(N, BLOCK_N); const int group_size = GROUP_M * grid_n; const int group_id = bid / group_size; const int group_off_m = group_id * GROUP_M; const int group_m = std ::min(grid_m - group_off_m, GROUP_M); const int bid_m = warp_uniform(group_off_m + ((bid % group_size) % group_m)); const int bid_n = warp_uniform((bid % group_size) / group_m); const int off_m = bid_m * BLOCK_M; const int off_n = bid_n * BLOCK_N; constexpr int A_size = BLOCK_M * BLOCK_K * sizeof (nv_bfloat16); constexpr int B_size = BLOCK_N * BLOCK_K * sizeof (nv_bfloat16); constexpr int AB_size = A_size + B_size;
然后是sharememory的地址偏移处理,之前提到的PTX指令都接收的是u32的指针,所以这里要通过__cvta_generic_to_shared对地址进行转换,转换后区分global/shared等位将被移除,只剩偏移量。
1 2 3 4 5 6 extern __shared__ __align__(1024 ) char smem[];const int smem_addr = static_cast<int >(__cvta_generic_to_shared(smem));const int A_smem = smem_addr;const int B_smem = A_smem + A_size;const int mbar_addr = smem_addr + NUM_STAGES * AB_size;
mbarrier的初始化后要插入一个fence,因为SM内部会分为执行代理和异步代理,执行代理执行的mbarrier_init必须对于异步代理是可见的:
1 2 3 4 5 6 7 if (warp_id == 0 && elect_sync()) { for (int i = 0 ; i < NUM_STAGES; i++) mbarrier_init(mbar_addr + i * 8 , 1 ); asm volatile ("fence.mbarrier_init.release.cluster;" ) ; } __syncthreads();
寄存器声明:
1 2 3 4 int A_rmem[WARP_M / MMA_M][BLOCK_K / MMA_K][4 ];int B_rmem[WARP_N / MMA_N][BLOCK_K / MMA_K][2 ];float acc[WARP_M / MMA_M][WARP_N / MMA_N][4 ] = {};
为后续计算读取准备的Asmem和Bsmem swizzle基址,这里可以回看SM80时绘制的图,对于WARP10来说,要处理的是A1的在sharedMem中下半的部分,B0在sharedMem上半的部分,而基址就是这两块的起点,后续线程只要更新K维度上的偏移。
1 2 3 const int A_smem_thread = A_smem + swizzle<BLOCK_K * sizeof (nv_bfloat16)>(warp_id_m * WARP_M + (lane_id % 16 ), lane_id / 16 );const int B_smem_thread = B_smem + swizzle<BLOCK_K * sizeof (nv_bfloat16)>(warp_id_n * WARP_N + (lane_id % 8 ), lane_id / 8 );
读取函数这里就是mbarrier重点优化的地方,在SM80实现中,我们需要计算每个线程要搬运的数据的起始地址,然后通过cp.async共同启动搬运,并且需要多轮次搬运,而在使用TMA后,这里只需要warp0的一个线程启动TMA数据搬运。
1 2 3 4 5 6 7 8 9 auto load_AB = [&](int iter_k, int stage_id) { if (warp_id == 0 && elect_sync()) { const int this_mbar_addr = mbar_addr + stage_id * 8 ; const int off_k = iter_k * BLOCK_K; tma_2d_g2s(A_smem + stage_id * AB_size, &A_tmap, off_k, off_m, this_mbar_addr); tma_2d_g2s(B_smem + stage_id * AB_size, &B_tmap, off_k, off_n, this_mbar_addr); mbarrier_arrive_expect_tx(this_mbar_addr, AB_size); } };
计算部分则没有什么变化,仍然是从sharedMem中读取数据到寄存器,然后m16n8k16进行计算。但是这里我们不用ldmatrix_x2来读取数据,而是使用ldmatrix_x4来一次读取两个B tile,减少指令数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 auto compute = [&](int stage_id) { for (int m = 0 ; m < WARP_M / MMA_M; m++) for (int k = 0 ; k < BLOCK_K / MMA_K; k++) { int addr = A_smem_thread + stage_id * AB_size; addr += m * MMA_M * BLOCK_K * sizeof (nv_bfloat16); ldmatrix_x4(A_rmem[m][k], addr ^ (k * 32 )); } for (int n = 0 ; n < WARP_N / MMA_N; n++) for (int k = 0 ; k < BLOCK_K / MMA_K; k += 2 ) { int addr = B_smem_thread + stage_id * AB_size; addr += n * MMA_N * BLOCK_K * sizeof (nv_bfloat16); ldmatrix_x4(B_rmem[n][k], addr ^ (k * 32 )); } for (int m = 0 ; m < WARP_M / MMA_M; m++) for (int n = 0 ; n < WARP_N / MMA_N; n++) for (int k = 0 ; k < BLOCK_K / MMA_K; k++) mma_m16n8k16(A_rmem[m][k], B_rmem[n][k], acc[m][n]); };
multi-stage流水线计算,对于数据搬运的同步,只需要warp0进行mbarrier,其他warp通过__syncthreads()进行等待,避免大量线程轮询,每次nstage个搬运结束后,都要翻转相位。在开始的时候需要先进行num_stage-1次预取,确保内存总线总是处于满载状态。虽然大多数时候num_stage是2,只有一次预取,但从pipeline设计的角度来说是要进行num_stage-1次预取,而不是1次预取就进入流水线。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 const int num_k_iters = cdiv(K, BLOCK_K); for (int stage = 0 ; stage < NUM_STAGES - 1 ; stage++) load_AB(stage, stage); int stage = 0 ; int phase = 0 ; for (int iter_k = 0 ; iter_k < num_k_iters - (NUM_STAGES - 1 ); iter_k++) { __syncthreads(); const int prefetch_iter_k = iter_k + NUM_STAGES - 1 ; load_AB(prefetch_iter_k, prefetch_iter_k % NUM_STAGES); if (warp_id == 0 ) mbarrier_wait(mbar_addr + stage * 8 , phase); __syncthreads(); compute(stage); stage = (stage + 1 ) % NUM_STAGES; if (stage == 0 ) phase ^= 1 ; } for (int iter_k = num_k_iters - (NUM_STAGES - 1 ); iter_k < num_k_iters; iter_k++) { if (warp_id == 0 ) mbarrier_wait(mbar_addr + stage * 8 , phase); __syncthreads(); compute(stage); stage = (stage + 1 ) % NUM_STAGES; if (stage == 0 ) phase ^= 1 ; }
最后是数据的写回,与SM80的实现一致。
1 2 3 4 5 6 7 8 9 10 C += (off_m + warp_id_m * WARP_M) * N + (off_n + warp_id_n * WARP_N); for (int m = 0 ; m < WARP_M / MMA_M; m++) for (int n = 0 ; n < WARP_N / MMA_N; n++) { const int row = m * MMA_M + (lane_id / 4 ); const int col = n * MMA_N + (lane_id % 4 ) * 2 ; float *regs = acc[m][n]; reinterpret_cast<nv_bfloat162 *>(C + (row + 0 ) * N + col)[0 ] = __float22bfloat162_rn({regs[0 ], regs[1 ]}); reinterpret_cast<nv_bfloat162 *>(C + (row + 8 ) * N + col)[0 ] = __float22bfloat162_rn({regs[2 ], regs[3 ]}); }