论文选读-异构协同计算SpGEMM
最近的优化工作进行之后,发现CPU的空闲时间还是比较多的,如果后续确认计算瓶颈,考虑是否能把CPU也加入计算部分。集群上的CPU性能比较差,可能没有空间,不过还是阅读了两篇工作。
异构协同计算SpGEMM
1 Orchestrating Large-Scale SpGEMMs using
Dynamic Block Distribution and Data Transfer
Minimization on Heterogeneous Systems(行积)
ICDE 23
GPU加速SpGEMM的几个问题:
- 负载不均衡
- 通过预处理或后处理的方式调整负载的方式引入过多开销
- 非重负载节点数据量小,不适合GPU并行计算
- 瓶颈转移:随着GPU性能的提升,性能瓶颈逐渐转变为数据传输(D2H)
本篇工作提出的动态块分配器是面向异构系统的SpGEMM调度框架,实现高效的CPU-GPU协同计算。将目标稀疏矩阵划分为更小的块,根据每个块的工作负载类型和系统资源利用状态分配块给GPU或CPU执行。
使用几种方法减少数据传输开销:
- Row Collecting(行收集)
- I/O Overlapping(I/O 重叠)
- I/O Binding(I/O 绑定)
相比基线库 cuSPARSE(NVIDIA 官方稀疏库):
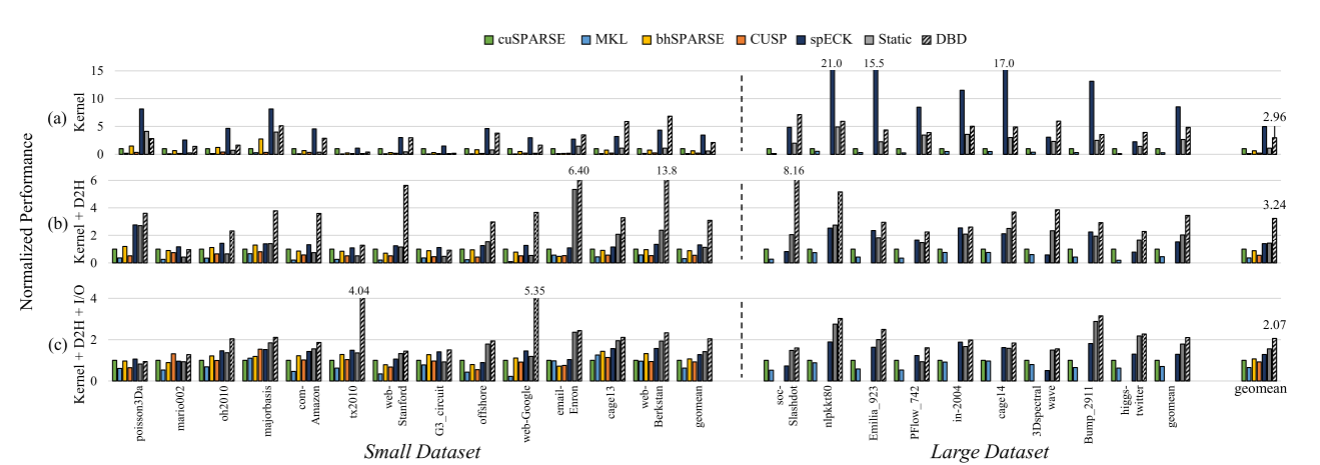
- SpGEMM 总延迟(包含 kernel 执行 + D2H 传输) 平均提升 3.24 倍;
- 整体执行时间 平均提升 2.07 倍。
INTRO
- GPU的潜在并行性没有充分利用
- 挑战是数据特性导致的负载不均衡
- 相关工作:对行进行分组,计算量小的行或列合并,计算量大的进行分割
本篇工作考虑的问题:
- 以前的方法没有认真考虑数据传输的开销,从GPU内存传输数据回内存的时间比内核计算时间要长,大部分现有的基于输入重排序的优化技术在计算部分结果后生成完整的结果,导致I/O和输出重排之间引入新的依赖(即需要还原才能写入磁盘或者进行下一步计算),阻碍了数据传输的进一步优化。
- CPU没有被利用,基于CPU的计算不需要传输数据,因此对负载较小的节点进行计算时,CPU可以替代GPU。
本篇工作提出一个动态块分发器DBD,将负载分为多个小块,按序分配给CPU和GPU,而不会在输入重排序方面产生任何开销。
- 输入矩阵分块,不重排
- 通过轻量级分析对块进行分类,分为CPU、GPU、中性
- 中性块根据负载启发式分配
- 按行积的方式执行乘法,这样结果是逐行写出的,计算和I/O可以重叠
- 减少D2H的传输开销
- Row collecting:对结果行进行收集和压缩
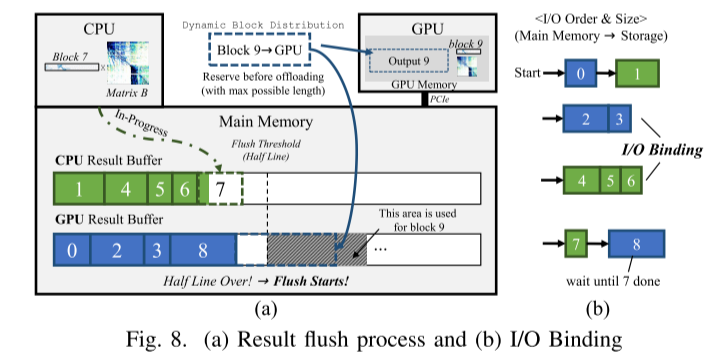
- I/O Binding:相邻块绑定成一个更大的I/O单元,一次性flush到存储
实验结果是kernel执行加速比为2.96x,包含kernel和数据传输的加速比为3.24x,整体性能2.07x(相对于cuSparse)。和其他的MKL,bhSPARSE,CUSP等也有性能对比。
BACKGROUND
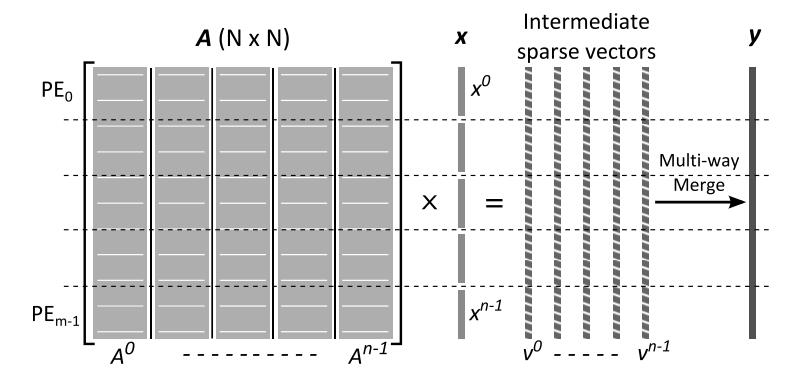
这部分主要包含GPU的介绍、CSR格式、基于行积的SpGEMM算法。
基于内积的是缓存性最差的,基于外积的需要大量内存空间来合并部分结果,基于行积的则缓存利用率高且分区友好,广泛应用于商业库,例如CUSP和cuSPARSE。在GPU上,通常每个线程生成一个部分结果,最后做归并累加得到C的一行。
MOTIVATION
- 传统行积的问题:行的特征不同导致负载不均衡,因此需要对行进行重排以及分组,分别用不同的kernel配置来计算,这导致需要在计算之后恢复原来的行序,导致输出无法和存储I/O重叠,以及有预处理和后处理开销。
- 以往的工作只关注计算kernel,但作者在3090测试多个矩阵,在整个流程中,其他部分也占用了很多时间:
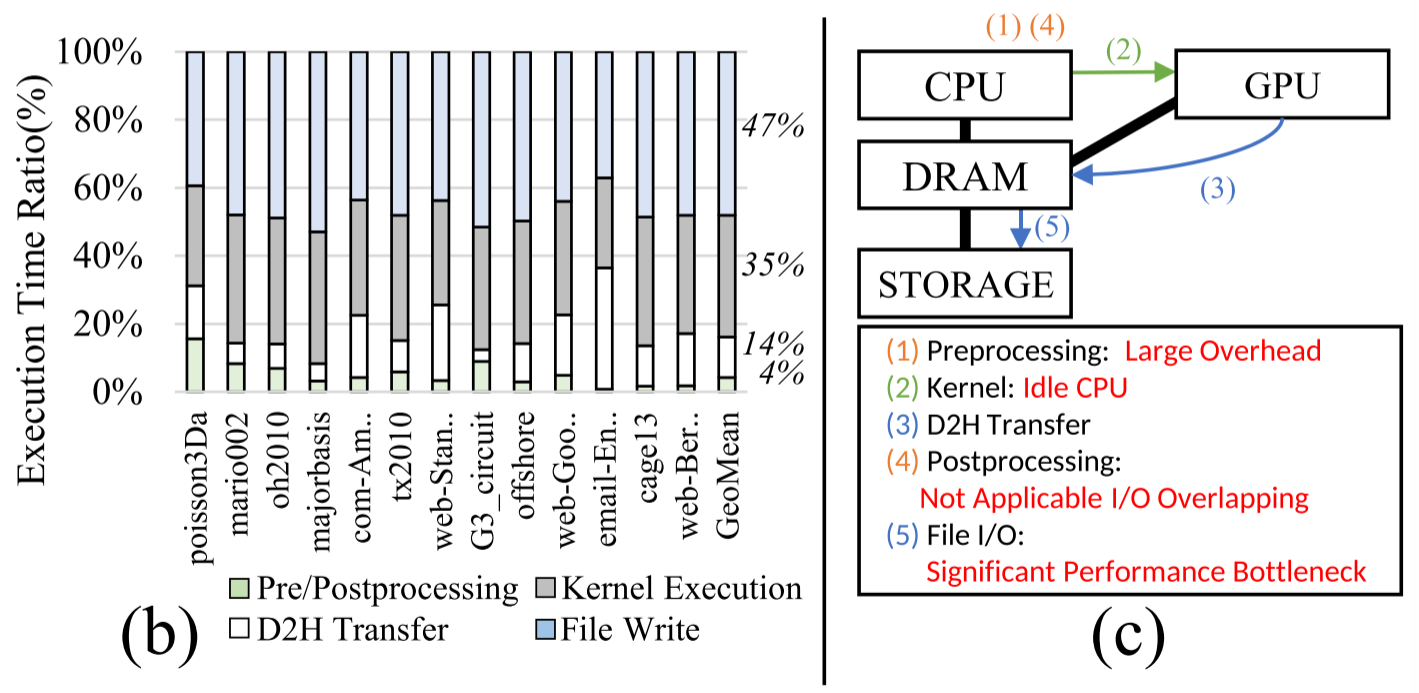
- 部分结果占用大量内存 会限制可扩展性
- I/O时间无法通过pipeline解决,被重排序卡住了
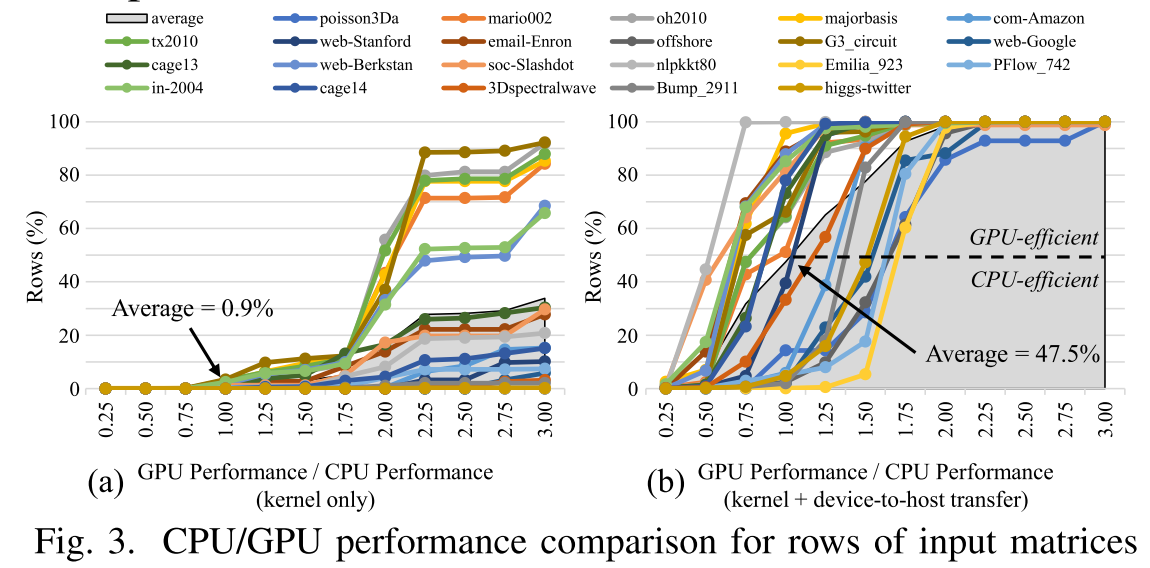
- 没有充分利用CPU,与GPU相比,不需要数据传输的CPU可以成为一个足够有竞争力的计算资源。如图3 (b)所示,当包括D2H传输延迟时,47.2%的部分工作负载在CPU上比在GPU上更快。
- 如果要利用CPU,就要做好负载均衡,因为GPU最快可以比CPU快150倍,一旦分配错误,就会带来显著的性能下降。
- Overall
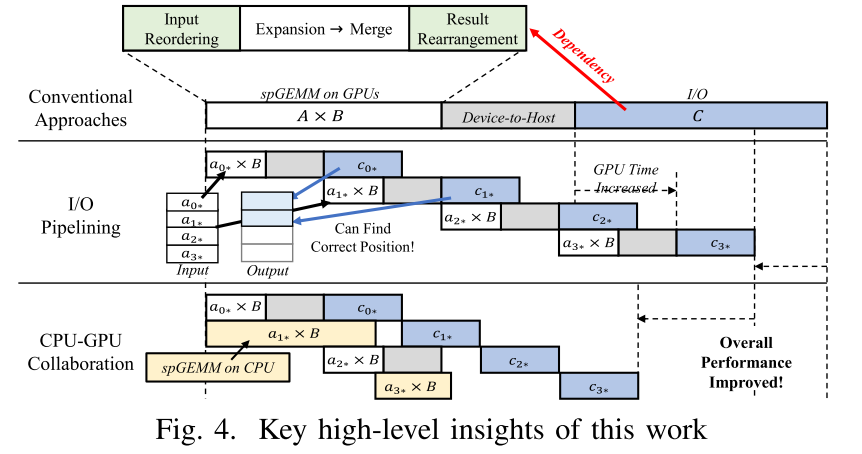
思考:加上CPU和舍弃重排序结合的原因可能是原来需要把轻负载的行放在一起,统一搬运到显存,但是CPU不需要,对轻负载的行可以直接启动计算。
DBD(动态块分配器)
DBD将工作负载分割为许多块,保持原始顺序卸载到CPU和GPU,并将结果存储,通过以下方式减少D2H传输和文件I/O开销:
执行针对块的优化和结果压缩;启用计算与I/O流水。
A. 输入矩阵分段
按行来划分负载太过细粒度,GPU的利用率低,因此DBD定义了block-unit SpGEMM,每个块指的是A的连续若干行,一个block-unit SpGEMM是A的行块乘上B,这样GPU可以充分利用资源来计算,并且块的大小可以灵活设定,I/O写出的时候也可以独立写出。
B.块分析
块的特征分布取决于稀疏矩阵的稀疏性分布。静态分配的问题是可能导致负载不平衡,CPU或GPU空闲,动态分配更均衡,但性能提升有限,也可能分配错误,所以DBD使用混合调度方案。
- 对那些 CPU/GPU 性能差距非常大的块:静态分配
- 对性能相近的块:运行时动态决定
一个block的最佳执行设备取决于两点:计算量&结果规模(影响D2H数据传输开销)。但结果规模是无法静态预测的,可能变化极大,因此DBD只使用计算量作为分类依据。计算量在行积SpGEMM中,预处理就会计算出这些信息,所以没有额外开销,并且这个大小刚好也是要分配的GPU中间结果buffer的大小。有大量计算量的块虽然D2H开销很大,但是CPU算起来很慢,所以视为GPU友好的块。
确定一个合适的阈值很困难,如图13所示,根据实验结果,作者将最优阈值设置为3%,计算量少于warp大小的块被归类为cpu友好型块。 这是因为GPU将多个线程分组为warp并以锁步方式执行它们; 因此,如果计算的数量少于warp的大小,那么warp的所有线程都不是有效的,并且一些内核在执行期间保持空闲[22]。 所有未分类的块被分类为中性块,要执行的设备在运行时确定。
C.动态块分配
DBD引入了CPU/GPU等待队列来有效处理对CPU/GPU友好的块。将CPU/GPU友好块插入队列。对于中性块,分配给准备就绪的设备。
D.block-unit SpGEMM
即便是GPU友好的块,计算特征也可能不同,因此DBD还需要进一步在GPU内部根据块特征微调执行方式。
GPU常见的SpGEMM累加中间结果的方式包括:
| 方法 | 核心思想 | 特点 |
|---|---|---|
| ESC (Expansion-Sort-Compression) | 把所有部分结果展开 → 排序 → 压缩重复项 | 简单但内存占用大 |
| Hashing | 用哈希表累加中间结果 | 空间效率高,但哈希冲突可能拖慢性能 |
| Merge | 把有序部分结果流进行多路合并 | 需要更多内存,但计算效率最高 |
分到 GPU 的 block 都是计算量很大的,所以DBD采用了merge base的累加中间结果的方式。
除了算法选择(Merge / Hash / ESC),DBD 还针对每个 block 调整 GPU kernel 的配置,DBD创建适当数量的线程,并根据块中的计算负载调整循环展开因子。
Merge 累加后,输出矩阵的每行可能有非零元素分散在不同位置,中间有很多 空洞(holes)。
传统方法直接把 整个 buffer(包括空洞) 拷贝到主存/存储;如果 block 很大,空洞很多 → D2H(Device to Host)传输成本极高。所以DBD遍历每行输出,将非零元素收集到连续空间,只将非零数据传回主存。这个过程在GPU上完成,开销很少。
而CPU的kernel,每个CPU核心计算一行,直接将乘加结果累加到数组。计算结束后压缩到CSR。全部在主存进行,使用OpenMP并行。
E.I/O绑定和结果写出
Experiement&EVALUATION
i7-11700K+3090GPU NVCC 11.7 and GCC 9.4.0。用于比较的除了MKL bhSPARSE cuSparse等,还对比了一个静态的CPU-GPU分配版本。所有的实验结果都包含了块分割和分析的开销。并且考虑了文件写操作的传输和开销。
2 ApSpGEMM:Accelerating Large-scale SpGEMM with
Heterogeneous Collaboration and Adaptive Panel
INTRO
对于大规模数据,单点上的GPU求解SpGEMM会所受到内存限制。
HPMaX这篇工作尝试了CPU/GPU混合的DGEMM计算,然而对于SpGEMM:
- NNz不可预测,随机而且不规则
- CPU和GPU差异大
- CPU和GPU之间的临时传输不可避免,显著增加了计算的等待延迟
针对上述的问题,本篇工作将矩阵拆分为子矩阵,命名为panel,panel大小取决于拆分算法和矩阵本身,这些panel是GPU和CPU上传输和计算的基本单元。
- 一个轻量分析器提取NZ的特征,并重排序和分割矩阵,来实现负载均衡
- 提出了一个核心亲和力的概念来适应异构核之间的任务分配
- 提出了一种异步乘算法,仔细设计了调度策略,来实现数据在不同核之间的传输核计算overlap
与最先进的GPU方法,算法提升了1.12到2.31倍的性能,大规模矩阵乘的性能提升了2.25到7.21倍,显著优于在单个设备上的性能。
Overview
整体的计算过程如下:
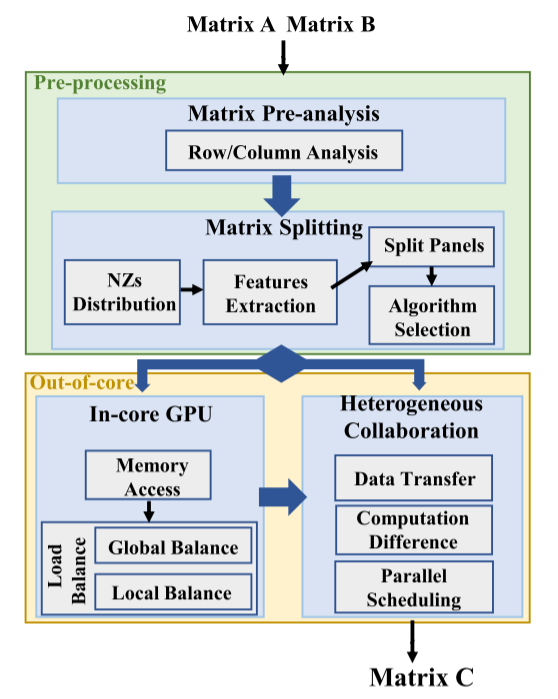
- 预分析是关键阶段,指导后续步骤,这个阶段的分析成本应该与潜在收益平衡,例如对于nsparse的例子,大约30%的时间用于预分析。
- 矩阵的Nz有各种分布特征,例如带状分布,集中分布和对角分布,这些特性显著影响核心的计算效率。因此需要算法来对矩阵进行最优拆分。
- in-core GPU:这一步涉及将来自A的panel与B的panel在GPU上相乘。算法与不同特征的panel有关,确认适合thread block的最佳panel size,分配线程块和线程都是重要且具有挑战性的任务。
- 异构协同:单卡内存不足以完成计算时,使用多个异构核的并发是有效的,但会引入传输延迟,复杂的调度协调等挑战,因此需要在GPU和CPU之间分配不同大小和特征的panel,并最小化通信和计算延迟。
Pre-processing
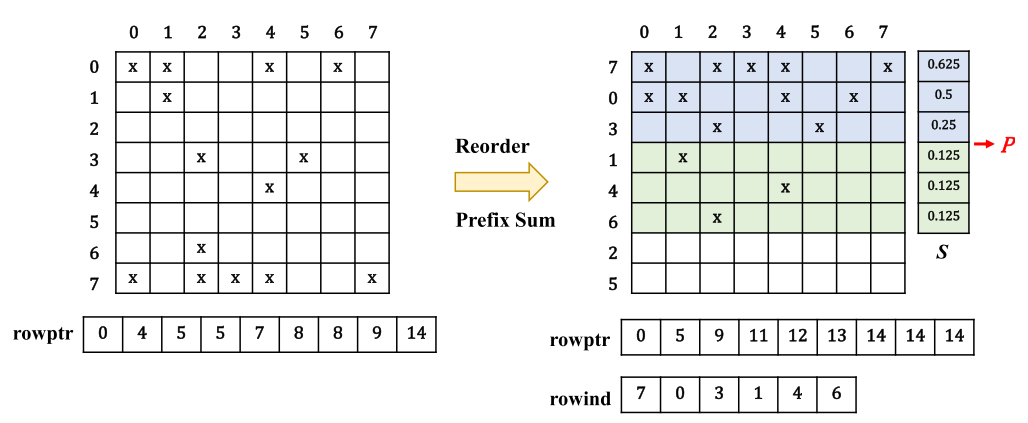
许多工作都会分析Nz的特征,例如32的工作,但是对于较大矩阵,这种分析的开销不可接受,并失去了可扩展性。因此应该尽可能精简提取的信息:对于ApSpGEMM,只提取a每一行的NNZ,B每一行的NNZ,a每一列的NNZ。
通过A中rowPtr的索引前缀和算法,可以快速确定每一行中的NNZ,此外,优于CSR的特性,同一列内的NZ在colPtr中有相同的索引,因此可以方便确定每列中的NNZ。
Matrix Splitting
为了对Nzs特征分布进行分类,定义了S=nnzi/Ni,将矩阵分为稀疏panel和密集panel。
在拆分矩阵A的行时,计算每行S后通过quickSort将行进行降序重排序,矩阵B也是同理,超过稀疏度阈值的行被分类为密集panel,否则为稀疏panel,对于许多应用,如果NZs的比例小于5%,则认为矩阵是稀疏的,所以定义阈值为0.05。
计算过程中将会出现:稀疏x稀疏,稀疏x密集,密集x密集,后续将介绍针对三种不同的矩阵乘法的优化技术。
Out-of-Core Computation
本篇工作采用的也是行积模式的矩阵乘,每个块计算不同panel的乘法,而每个线程则处理行中的相应Nz。这个过程中要考虑的问题有负载均衡和访存优化。需要为每个线程块分配最佳负载,过多的负载会导致频繁的全局访存,过于保守的分配可能导致共享内存资源的低效使用。
计算过程中的访存涉及线程从全局内存检索B中的行,加载到共享内存中,A中的每个Nz都需要一次全局内存访问,过高的负载可能导致内存访问的巨大开销。
为了解决负载均衡和内存访问这两个问题,本文提出了以下方案:
SpGEMM
- 使用系统的方法来实现全局负载均衡:将A中的连续行分类到离散的箱中,利用预处理步骤得到的信息,将箱分配给不同的线程块。每个分箱根据共享内存的大小分配不同数量的行。
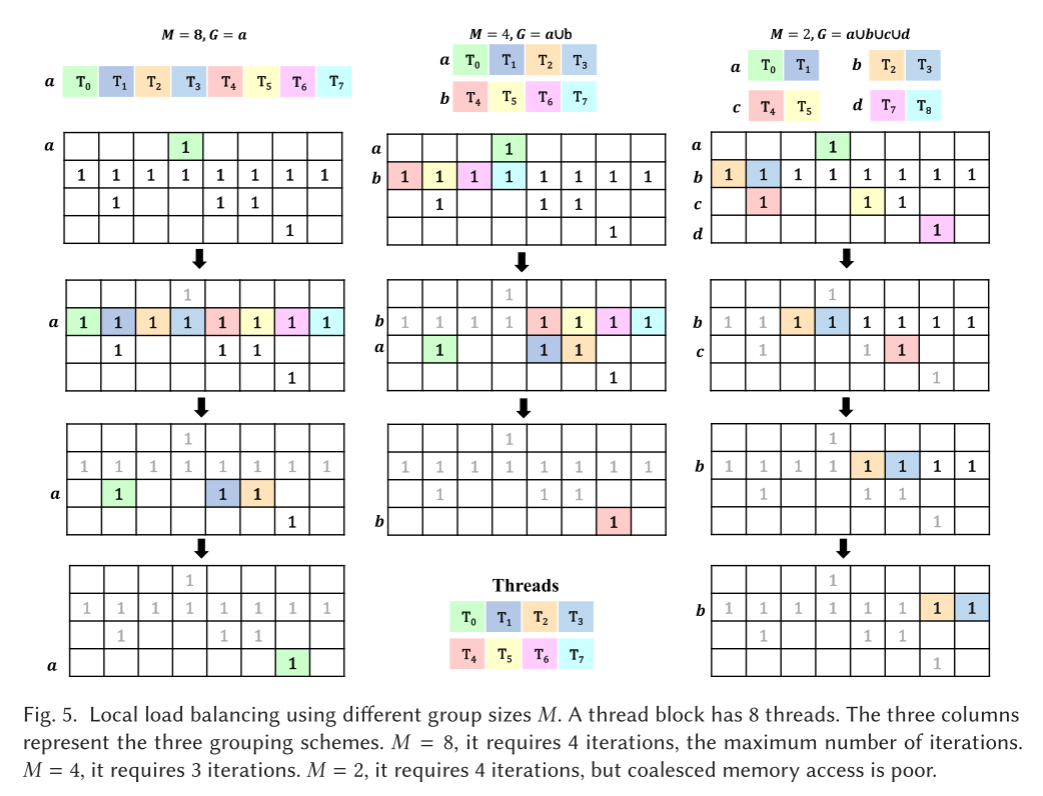
- 为一行分配合适的线程数:固定的分配方式回带来负载不均衡的风险,动态的决策可能带来很大的决策开销,对于一个有T个线程的线程块,将线程分为G组,每组包含M个线程。不同的线程组配置会影响行需要几次迭代来处理完成,如图所示。ApSpGEMM首先根据所有行的平均行长度初始化M的值,然后系统的将线程组分配给矩阵A,对于最长的行,一行中线程需要执行的最大迭代计数定义为iterthread = NNZmax/M,为了让这个值和每组要处理的行数接近一致,使用一种启发式的算法来确定M的值,如算法2所示。

SpMM
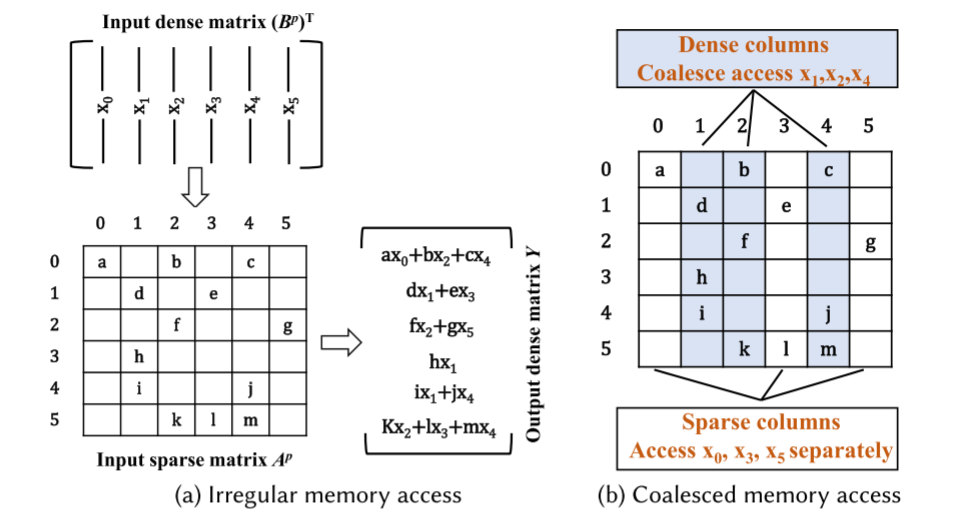
对于SpMM,需要将稀疏panel乘上密集panel,这个过程中大量的访存都是对B的读取,A的nz只占了共享内存的少部分空间。
为了提高A中的Nz的重用,A中同一列的Nz可以共用B中同一行的元素,因此同一列出现的NZs次数可以减少到一次,并且越多越好,基于这个特征,将密集列定义为具有一个以上NZ的列,让密集列共享数据,如图所示,只需要3个线程访问A中三列的数据,而不是每个线程在每行都访问一次。
DGEMM
本质上具有高度的数据重用,并遵循顺序元素访问模式,因此不需要专门讨论内核的优化。有一些工作例如AlphaZero[9]和Strassen通过减少乘法数量来降低计算复杂性,这些都可集成到ApSpGEMM。
配置
ApSpGEMM使用最大可用共享内存(在RTX 3080上为128 KB)和最大内核大小(1024线程)来保证充分利用硬件。 值得注意的是,RTX 3080的共享内存大小是64kb, L1缓存大小也是64kb。 ApSpGEMM结合了共享内存和L1缓存,在1024个线程之间共享。 在In-core Computation过程中,有些数据是只读的,例如行或列对应的NNZs信息、稀疏列表S、rowind索引等。 这些数据的特点是在内核执行期间经常被访问和只读。 为了最大限度地在共享内存中存储NNZs数据,ApSpGEMM在“ constant ”中定义了上述只读数据,并将其存储在常量内存(64 KB)中。
ApSpGEMM将目标bin加载到共享内存中,而相邻的bin则预加载到L2缓存中,从而减少了全局内存访问开销。
异构协同计算
协同计算有两个关键挑战:
- 同步CPU和GPU的计算时间,需要建立一个标准来将panel分配给CPU和GPU
- 异构内核之间有巨大的数据传输开销,需要优化数据传输过程
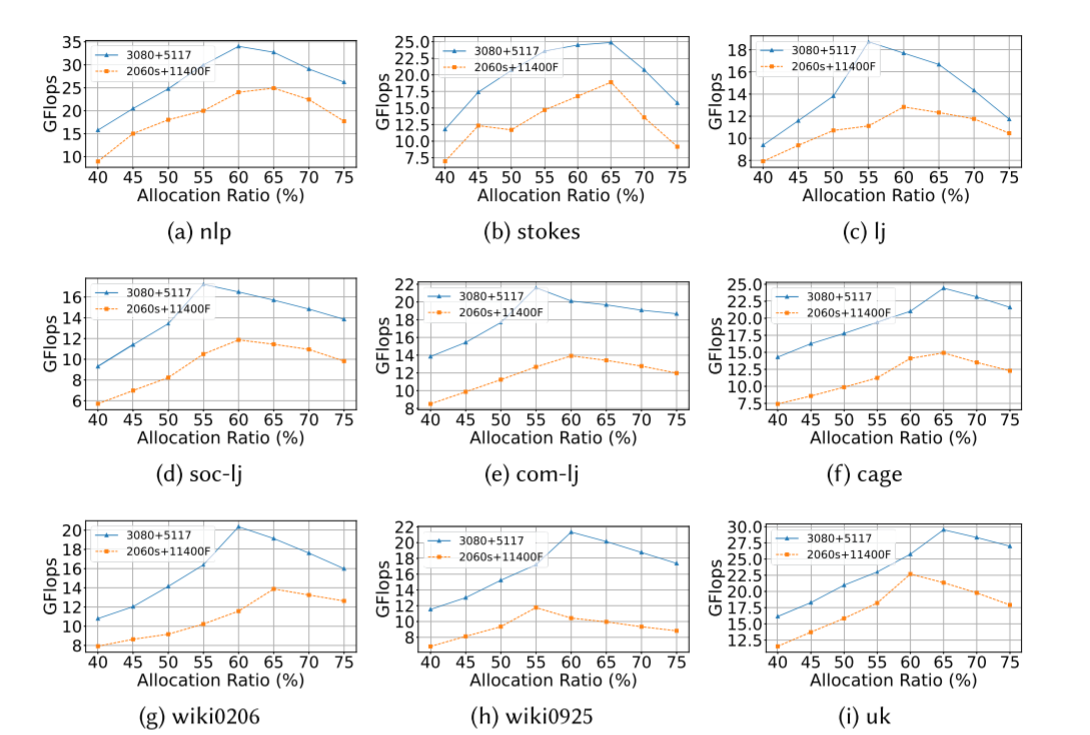
为了从经验上评估稀疏级别对计算的性能影响,ApSpGEMM进行了一系列测试,测量了具有不同稀疏级别的panel的计算时间,使用3080和Xeon 5117,如图A所示:
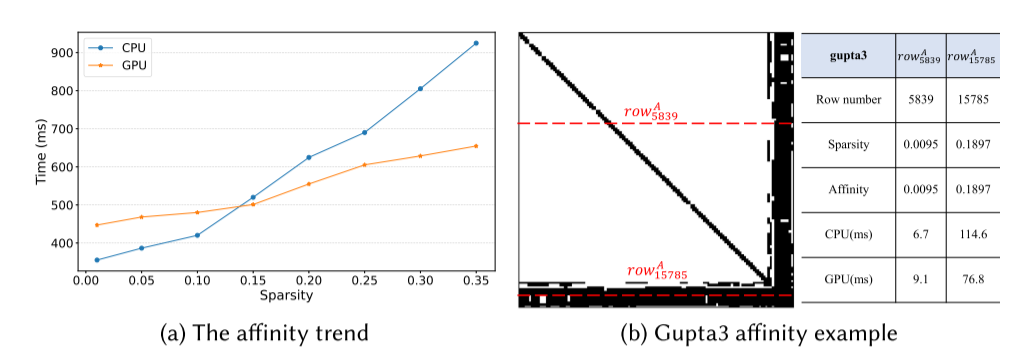
稀疏度(非零元)越多,GPU的性能更有优势,
为了同步异构核上的计算时间,确定面板的分配比例变得至关重要。 这个比率定义了如何分配面板在CPU和GPU上进行处理,旨在最大限度地减少它们在计算时间上的差异。 我们将计算系数定义为K = CPUexe/GPUexe,其中CPUexe和GPUexe分别表示CPU和GPU执行单个乘法操作的计算时间。 因此,我们推导出gpu与cpu的分配比率为R = K/(K + 1)。 根据我们的实验观察,我们已经确定,在我们特定的实验平台上,将R设置在60%到65%的范围内,可以获得输入矩阵的最佳性能。 然而,值得注意的是,R的最优值可能会受到CPU或GPU配置变化的影响。 因此,可能需要调整R以匹配不同的硬件设置。 尽管如此,选择合适的R在CPU和GPU之间分配计算任务的基本原则仍然是一个重要的考虑因素。
为了解决数据传输耗时的问题,ApSpGEMM实现了计算和数据传输的OVERLAP,最小化等待开销。
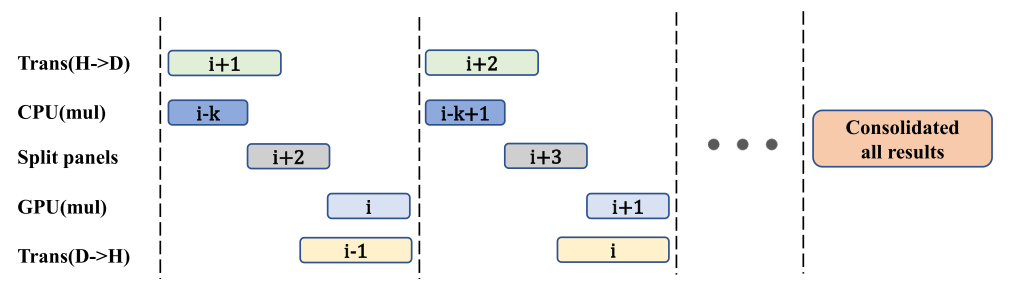
实验
双精度计算,前9个在GPU上进行,其余则在GPU/CPU上进行。