Optimizing SpMV on Emerging Many-Core Architectures
Optimizing SpMV on Emerging Many-Core Architectures
本文实现了一个针对众核平台实现的自适应格式选择的模型,能够针对不同矩阵选择合适的压缩矩阵格式进行计算。两个众核平台分别为Intel KNL和FTP。选取的格式为CSR,CSR5,ELL,SELL,HYB。数据集采用suitsparce的900+个矩阵。
在实现SpMV时,只在KNL上做了向量化,而FTP没有进行向量化,因为ARM NEON没有gather/scatter指令,对不同位置数据的加载慢。经测试,在FTP上,SELL在最多矩阵中有最佳性能,而CSR,CSR5,HYB在一部分矩阵中有最佳性能,ELL则最差。
作者实现的模型为决策树,采用了一些基本特征来预测最合适的压缩格式,并进行计算。
Abstract
本文全面研究了稀疏矩阵表示对两种众核架构(Intel KNL Xeon Phi和FT-2000Plus)上的计算性能。实验涉及956个稀疏矩阵和五种主流SpMV表示上执行的9500多次不同的分析运行。结果表明,最佳稀疏矩阵表示取决于底层架构和程序输入,作者使用机器学习来开发预测模型,首先使用一组训练示例进行离线训练,学习到的模型用于预测给定架构的最佳矩阵表示。模型在KNL和FTP上分别提供了平均95%和91%的最佳可用性能。
1 Introduction
已有的研究表明稀疏矩阵格式对性能有很大影响,最佳格式和架构及矩阵的大小和模式有关。虽然已经有大量在多核架构上优化SpMV的研究,但是没有明确不同的稀疏矩阵格式如何影响新型多核架构上的SpMV性能。
KNL和FTP集成了多个处理器内核,可提供潜在的高性能。而本研究中稀疏矩阵格式选取五种:CSR、CSR5、ELL、SELL和HYB。
作者的研究表明选取合适的格式对性能很重要,并建立了一个机器学习模型来选择合适的格式。模型的输入是矩阵的一些特征,输出是最合适的格式。作者的实验结果表明模型在格式的选择上是非常有效的。
2 Background
以下是稀疏矩阵存储的一些常见格式
COO
最基本的格式。
CSR
最常用的通用稀疏矩阵格式。对COO进行了进一步的压缩。
CSR5
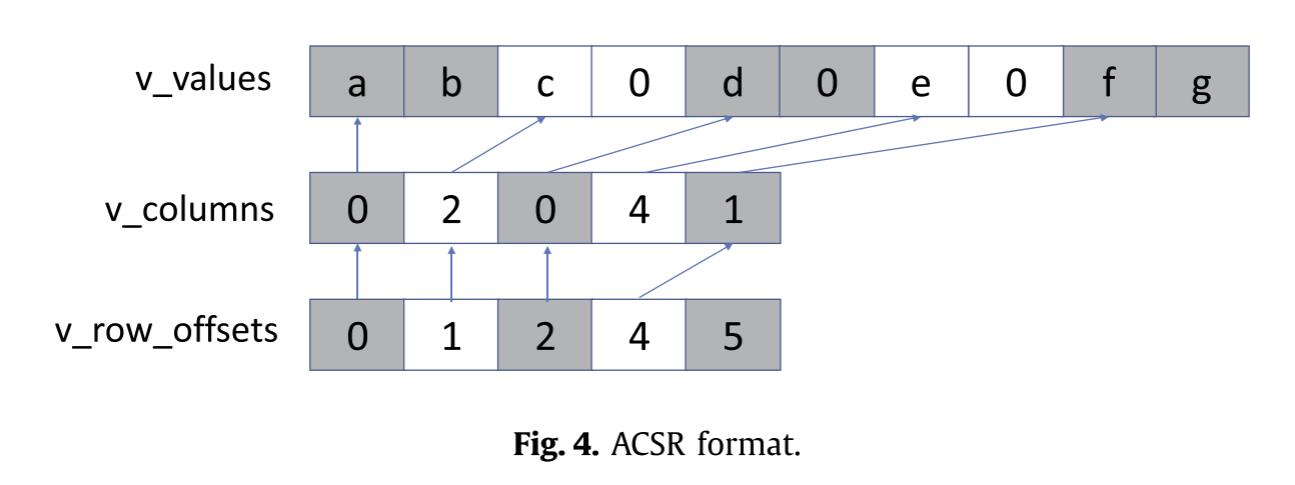
为了对任何结构的稀疏矩阵实现负载均衡,CSR5首先将所有非零元素平均分为相同大小的2D块。当执行并行计算时,计算核心分配到多个2D块,并且核心的每个SIMD通道处理块的一列。
CSR5是CSR的扩展,有两个参数:ω和σ,分别为块的宽度和高度。在CSR的数据结构基础上,还引入了两个数据结构tile_ptr和tile_des。
ELL
ELLPACK是针对向量体系结构的,通过填充0将数据存储在M*K的数组中。K是行的最大非零元素数。ELLPACK会浪费一些空间,为了减少浪费,可以将其与其他格式进行结合。
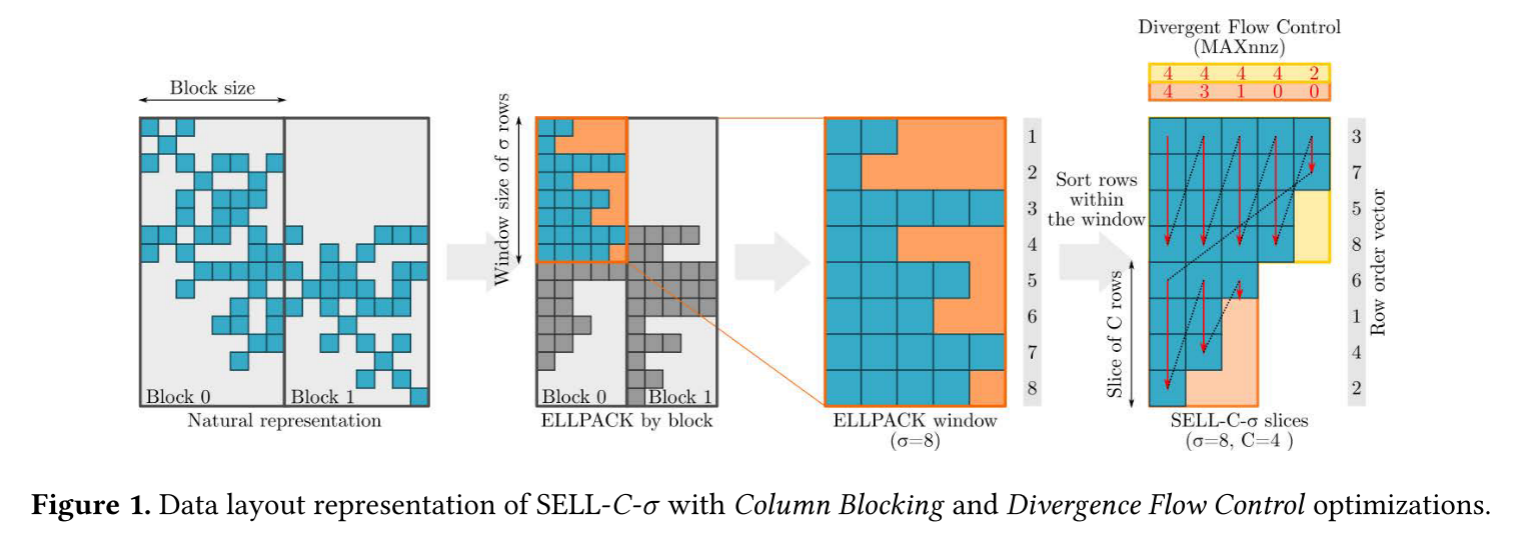
SELL & SELL-C-σ
SELL是将ELLPACK划分,相邻的C行一组。每组ELL格式。而SELL-C-σ进一步将组长度进行排序来节省空间。相邻的σ行是有序的,σ是C的倍数。
HYB
HYB是ELL和COO的结合,存储矩阵主要部分的元素为ELL格式,其余为COO格式。通常,HYB以ELL格式存储每行的典型非零数(K),以COO格式存储特别长的行。K可以直接从输入矩阵计算出来。
3 Experiment Setup
FTP
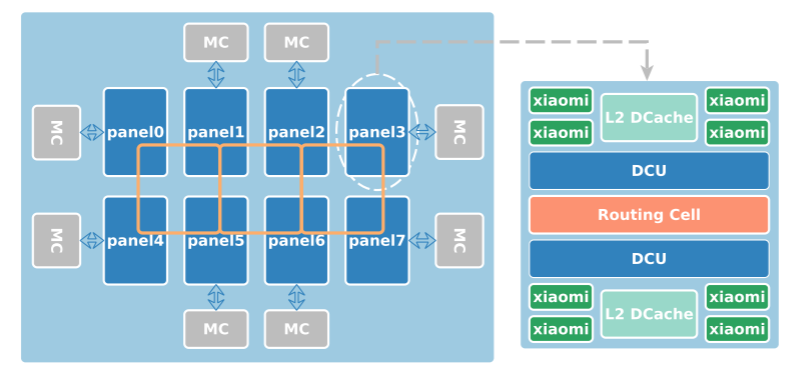
图二是FTP的高层次结构图示。该结构有64个ARMv8核,提供双精度最大512GFLOPS的性能,最大功耗100W,核的最大频率为2.4GHz,并分组为8 panel * 8 core。每个核有32KB L1,4核共享的2MB L2。panel通过DCU连接,核缓存都通过2D网格连接。外部 I/O 由 DDR4 内存控制器 (MC) 管理。
KNL
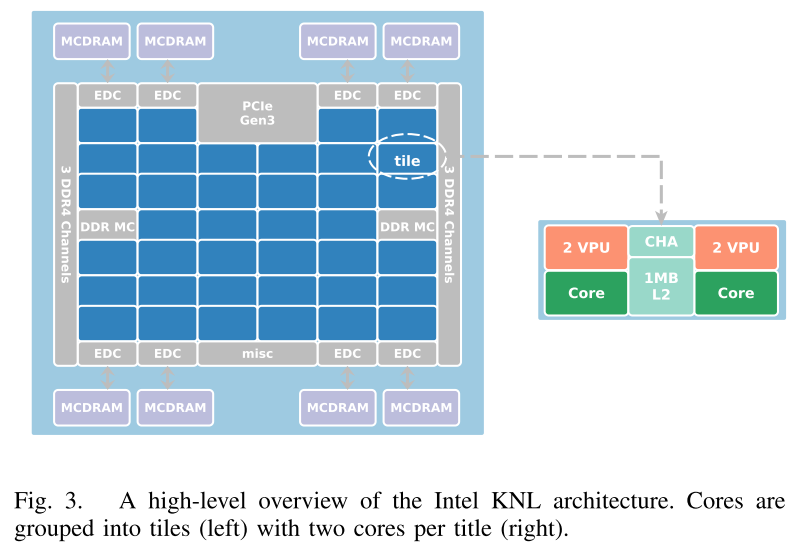
KNL的shaun高精度峰值性能为3Tflops/s。一个KNL通道最多有72核,每核可以以1.3GHz运行4个线程,每个核有32KB的L1数据和32KB的L1指令缓存,两个向量单元。
KNL的核被组织为32tile,每个tile两核,两核共享1MB的L2数据缓存,由cache/home agent (CHA)管理。tiles通过2D网格连接保证L2缓存的一致性。此外,KNL 芯片具有“近”和“远”存储组件。近存储器组件是多通道 DRAM (MCDRAM),它们通过 MCDRAM 控制器 (EDC) 连接到区块。 “远”内存组件是 DDR4 RAM,通过 DDR 内存控制器 (DDR MC) 连接到芯片。虽然“近”内存比“远”内存小,但它提供的带宽是传统 DDR 的 5 倍。根据芯片的配置方式,某些部分或整个近存储器可以与远存储器共享全局存储器空间,或者用作缓存。在这种情况下,MCDRAM用于缓存模式,数据集可以保存在高速存储器中。
系统软件
平台均为Linux系统,FTP的kernel为4.4.0,KNL的为3.10.0。编译选项为-O3,分别使用gcc和intel icc编译器。使用OpenMP实现多线程,FTP上64线程,KNL上272线程。
数据集
使用来自suitesparce的956个矩阵。NNZ范围为100K到20M。包含规则和不规则的矩阵,各种领域应用的矩阵。
SPMV实现
算法 1 使用 CSR5 格式作为示例说明了基于库的 SpMV 实现。库将 Matrix Market 格式的原始数据放入 COO 格式的内存中。然后基于 COO 的数据转换为目标存储格式(CSR、CSR5、ELL、SELL 或 HYB)。在计算SpMV时,使用OpenMP线程模型进行并行化。此过程与格式相关,即基本任务可以是行、块行或数据图块。

计算结果向量y的单个元素被分割到不同任务中,需要收集部分结果。这种有效的数据收集可以通过使用内在函数手动向量化 SpMV 代码来实现。NEON没有gather和scatter功能,因此在FTP上不使用NEON intrinsics,因为实验表明使用intrinsics会导致性能的下降。测量性能时,运行FRQ次实验并计算平均结果。
4 Memory Allocation and Code Vectorization
SpMV 性能取决于众核架构上的许多因素。其中包括内存分配和代码优化策略,以及稀疏矩阵表示。这项工作的重点是确定导致最快运行时间的最佳稀疏矩阵表示。为了隔离问题,需要确保在最佳的内存分配和代码优化策略上进行不同表示的性能比较。为此,作者研究了非均匀内存访问 (NUMA) 和代码矢量化如何影响 FTP 和 KNL 上的 SpMV 性能。然后作者对最佳的 NUMA 内存分配和矢量化策略进行了实验。
NUMA 绑定
FTP架构一组8核心连接到本地内存模块,可以间接访问远程内存模块,但速度较慢,实验使用numactl从正在运行的处理器的本地内存分配所需要的数据缓冲区。
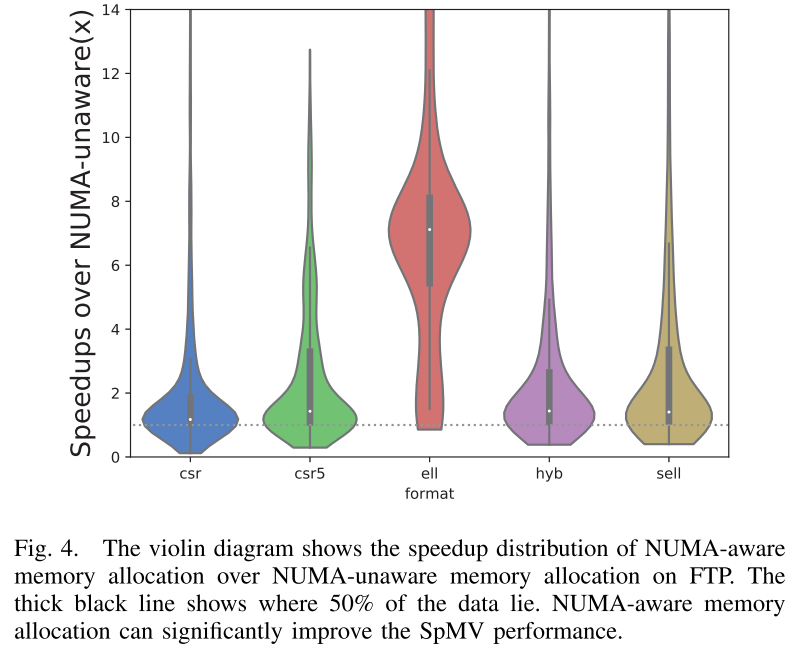
图4是采用numactl的结果,性能明显比不使用numactl更好。
KNL上进行的向量化
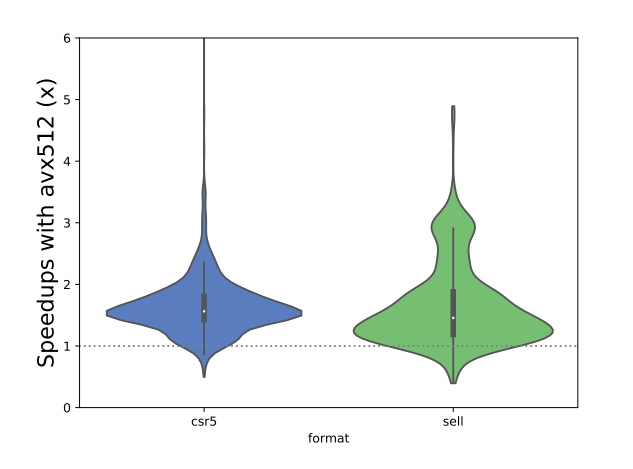
本研究的两个架构都支持SIMD。图5显示了KNL上SpMV的性能优化效果。作者没有对FTP上的SpMV进行向量化,因为NEON不支持gather指令,从不同位置载入数据的速度不够快。因此作者只向量化了KNL上的SpMV。
FTP与KNL的比较
图6展示了KNL和FTP的性能比较。KNL在各种格式上都更快。性能差异来自于架构内存层次结构的差异。 KNL 与 FTP 的不同之处在于,它在 L2 缓存和 DDR4 内存之间有一个高速内存,又称 MCDRAM。 MCDRAM 可提供比传统 DDR 内存高 5 倍的内存带宽。数据集被载入MCDRAM高速内存,应用就可以以更高内存带宽访问数据,有更好的性能。此外,KNL对gather/scatter指令的支持也对性能的提升很关键。
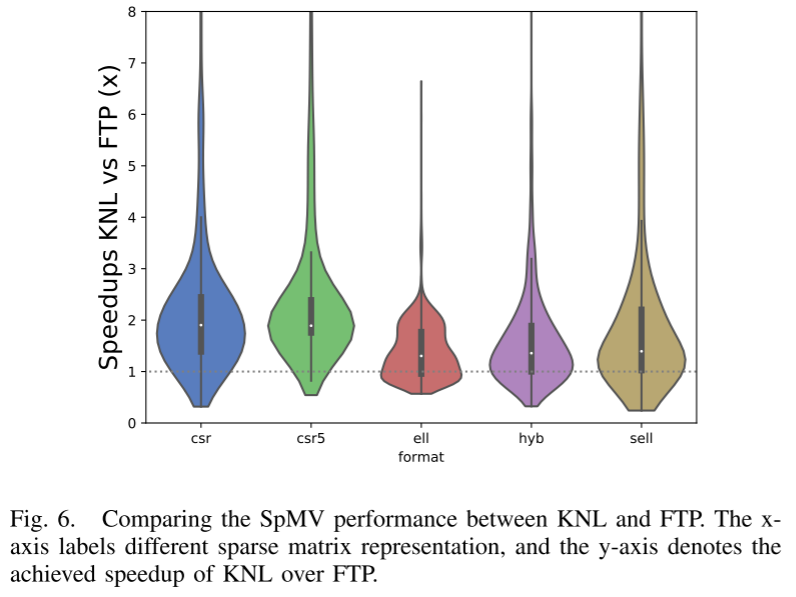
从图 6 中,还可以观察到 FTP 在某些矩阵上的性能优于 KNL,特别是当输入矩阵的大小较小时。性能差异是由于 KNL 和 FTP 在二级缓存中的容量和一致性协议方面有所不同。
最佳矩阵格式
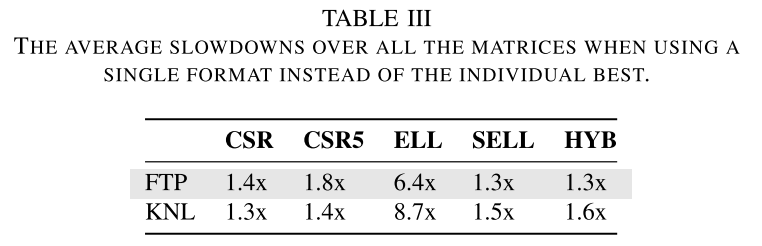
图7展现了FTP和KNL上的SpMV性能。在 FTP 平台上,SELL 是大约 50% 稀疏矩阵的最佳格式,ELL 在大多数情况下表现最差。在KNL平台上,CSR在大多数情况下表现最佳,其次是CSR5和SELL。在 KNL 上,ELL 和 HYB 对于总共 64 个稀疏矩阵给出了最佳性能(表 II)。
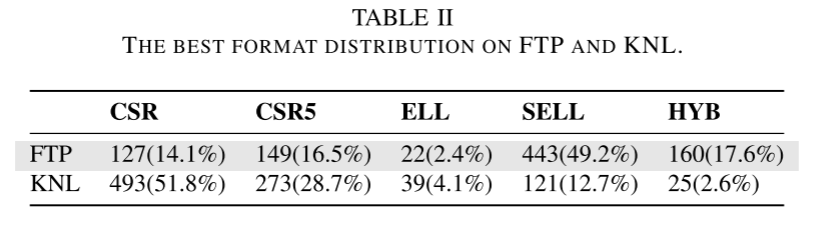
表 III 显示了在测试用例中使用固定格式时相对于最佳格式的平均减速情况。减速与给定格式最佳的频率呈负相关。例如,CSR 在 KNL 上提供了最佳的整体性能,因此它的整体减速程度最低。此外,SELL 和 HYB 在 FTP 上的平均速度相似,因为它们通常提供相似的性能(参见图 7(a))。
鉴于最佳稀疏矩阵存储格式因架构和输入而异,找到最佳格式是一项艰巨的任务。为了得到自适应方案,需要实现为给定的输入和架构自动选择正确的格式,在下一节将介绍如何实现这部分内容。
5 Adaptive Representation Selection
5.1 总体方法
作者采用的方法的overview如下:
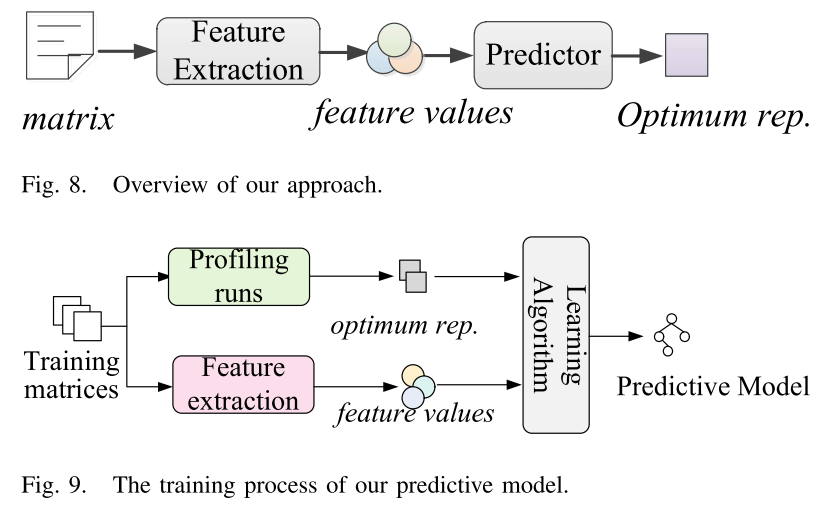
预测模型是基于scikit-learn机器学习包实现的。
对于给定的稀疏矩阵,收集一组信息或特征,以捕获矩阵的特征。可以在编译时或运行时收集该组特征值。表 IV 列出了作者考虑的所有功能的完整列表。收集特征值后,基于机器学习的预测器(离线训练)接收特征值并预测目标架构应使用哪种矩阵表示。然后,将矩阵转换为预测格式并生成该格式的计算代码。
5.2 预测模型
作者采用决策树作为预测最佳矩阵格式的模型。作者还尝试了其他的模型,包括回归、朴素贝叶斯和 K 最近邻。决策树的效果是最好的,并且与其他黑盒模型相比更便于分析和解释。
构建和使用此类模型遵循监督机器学习的 3 个步骤流程:(i) 生成训练数据 (ii) 训练预测模型 (iii) 使用预测器,如下所述。
训练预测器
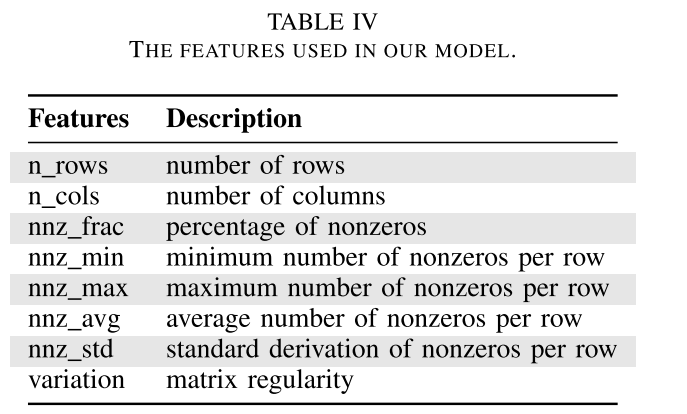
训练预测模型的方法如图 9 所示。使用相同的方法为每个目标架构训练模型。为了训练预测器,首先需要为每个训练矩阵示例找到最佳的稀疏矩阵表示,并提取特征。然后使用这组数据和分类标签来训练预测模型。
使用五重交叉验证进行训练。这种标准机器学习技术的工作原理是选择 20% 的样本进行测试,并使用 80% 的样本进行训练。为了生成模型的训练数据,使用了 SuiteSparse 矩阵集合中的 756 个稀疏矩阵。使用每个稀疏矩阵表示多次执行 SpMV,直到在 95% 置信区间设置下置信区间上限和下限的差距小于 5%。然后在 KNL 和 FTP 上记录每个训练样本的最佳性能矩阵表示。最后从每个矩阵中提取所选特征集的值。
最佳矩阵表示标签及其相应的特征集被传递给监督学习算法。学习算法试图找到特征值和最佳表示标签之间的相关性。学习算法的输出是基于决策树的模型的一个版本。因为在本文中针对两个平台,所以构建了两个预测模型,每个平台一个模型。由于训练是离线执行的,并且对于给定的架构只需要执行一次,这是一次性成本。
模型的总训练时间由两部分组成:收集训练数据,然后构建模型。收集训练数据消耗了总训练时间的大部分,在本文中,两个平台花费了大约 3 天的时间。相比之下,实际构建模型所花费的时间可以忽略不计,不到 10 毫秒。
特征
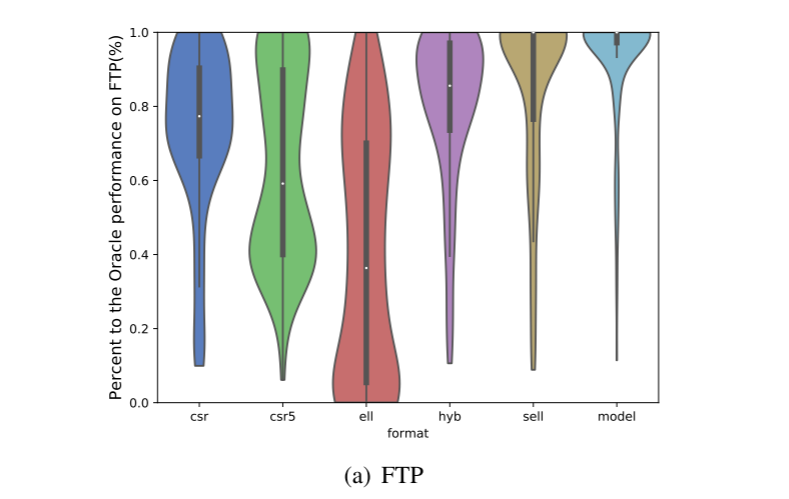
构建成功的预测器的关键方面之一是开发正确的特征来表征输入。预测模型完全基于目标矩阵的静态特征,不需要动态分析。因此,它可以应用于任何硬件平台。这些特征是使用 Python 脚本提取的。由于作者的目标是开发一种可移植的、独立于架构的方法,因此作者不使用任何特定于硬件的功能。
在这项工作中,作者总共考虑了七个候选原始特征(表 IV)。一些特征是根据直觉根据可能影响 SpMV 性能的因素选择的,例如nnz frac和variation,其他特征是根据以前的工作选择的[33]。总而言之,候选特征应该能够代表 SpMV 内核的内在部分。
将特征传递给机器学习模型之前的最后一步是将特征向量的每个标量值缩放到公共范围(0 到 1 之间),以防止任何单个特征的范围成为影响其重要性的因素。缩放特征不会影响其值的分布或方差。为了在部署期间缩放新图像的特征,记录训练数据集中每个特征的最小值和最大值,并使用它们来缩放相应的特征。
运行时部署
预测模型的部署被设计得简单且易于使用。为此,作者的方法以 API 的形式实现。该 API 封装了所有内部工作,例如特征提取和矩阵格式转换。作者还提供了源到源转换工具,将给定 SpMV 内核的计算转换为每个目标表示。使用预测标签,运行时可以选择使用哪个 SpMV 内核。
5.3 预测模型评估
作者使用交叉验证来评估方法。将 965 个矩阵随机分为两部分:756 个用于训练的矩阵和 200 个用于测试的矩阵。学习一个具有训练矩阵和五种表示形式的模型。通过应用学习模型对 200 个测试矩阵进行预测来评估它。多次重复此过程,以确保每个矩阵至少测试一次。
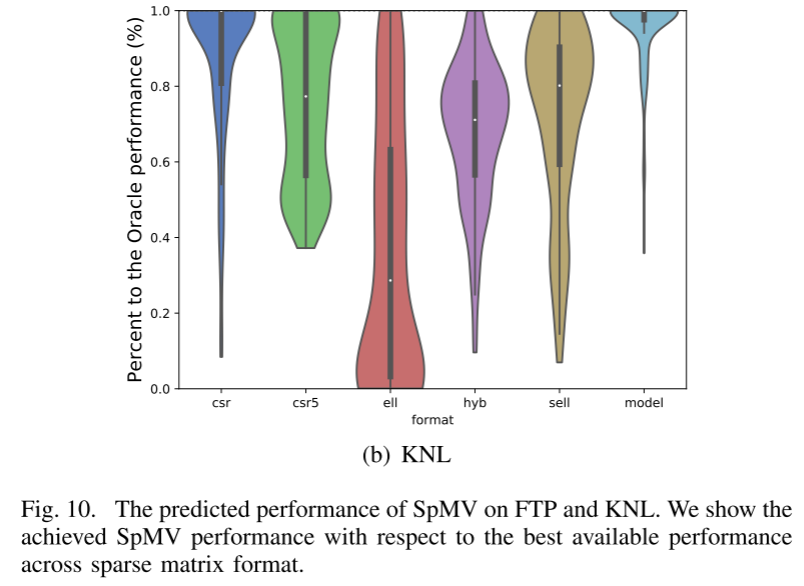
图 10 显示,预测器在 FTP 和 KNL 上平均分别实现了最佳可用 SpMV 性能(通过详尽搜索发现)的 91% 和 95%。它优于仅使用单一格式的策略。正如在表三中分析的那样,SELL 和 HYB 可以在 FTP 上获得比其他三种格式更好的性能。但他们仍然被预测器超越。然而,在 KNL 上,预测器的性能是通过使用 CSR 表示来跟踪的。此外,使用 ELL 表示在 FTP 和 KNL 上的性能都很差。这表明预测器在选择正确的稀疏矩阵表示方面非常有效。
5.4 其他模型
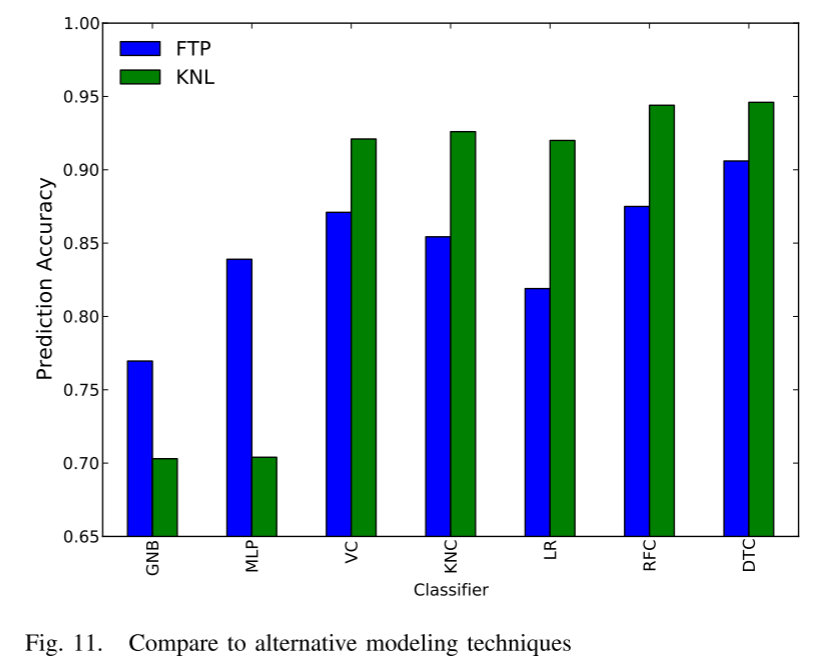
图 11 显示了使用不同技术构建预测模型时相对于最佳可用性能的结果性能。除了基于决策树的模型 (DTC) 之外,作者还考虑高斯朴素贝叶斯 (GNB)、多层感知 (MLP)、软投票/多数规则分类 (VC)、k 最近邻 (KNC, k=1) )、逻辑回归(LR)、随机森林分类(RFC)。由于高质量的特征,所有分类器在选择稀疏矩阵表示时都非常准确。作者选择 DTC 是因为它的准确性与替代技术相当,并且可以轻松可视化和解释。
6 Related Work
在过去的几十年里,SpMV 在各种平台上得到了广泛的研究 [24]、[30]、[46]。大量工作致力于在多核和众核处理器上实现高效且可扩展的 SpMV。作者的工作是第一次对KNL和FTP进行全面的研究。在 SIMD 处理器上,一些研究人员设计了新的压缩格式以实现高效的 SpMV [1]、[13]、[17]、[46]、[47]。刘等人。提出了一种存储格式CSR5 [21],它是一种基于图块的格式。 CSR5在各种平台上提供高通量SpMV,并在规则矩阵和不规则矩阵都表现出良好的性能。
而且从CSR到CSR5的格式转换可以低至几次SpMV操作的成本。关于 KNC,Liu 等人。已经确定并解决了几个瓶颈[22]。他们利用 KNC 的显着架构特征,使用专门的数据结构和仔细的负载平衡来获得令人满意的性能。唐伟腾等人。提出了一种称为矢量化混合COO+CSR(VHCC)的SpMV格式[35],它采用2D锯齿状分区、平铺和矢量化前缀和计算来改善硬件资源。对于一系列无标度矩阵,他们的 SpMV 实现比英特尔 MKL 平均加速 3 倍。
近年来,ELLPACK 是宽SIMD 处理器上最成功的格式。 Bell 和 Garland 提出了第一个基于 ELLPACK 的格式 HYB,将 ELLPACK 与 COO 格式相结合 [1]。 HYB 可以提高 SpMV 性能,特别是对于“宽”矩阵。 Monakov 等人提出了切片 ELLPACK 格式,其中矩阵的切片分别以 ELLPACK 格式打包[25]。 BELLPACK 是一种源自 ELLPACK 的格式,它按每行非零数对矩阵的行进行排序 [5]。蒙里茨·克罗伊策等人。设计了基于 Sliced ELLPACK 的 Sliced ELLPACK SELL-C-sigma 变体作为 SIMD 友好的数据格式,其中切片被排序 [19]。
还有一些针对 SIMT GPU 专用 SpMV 的优化研究 [1]、[23]、[35]、[39]。唐伟腾等人。引入了一系列用于在 GPU 上表示稀疏矩阵的位表示优化压缩方案,包括 BRO-ELL、BRO-COO、BRO-HYB,这些方案对索引数据进行压缩,并通过减少内存流量来帮助加速 GPU 上的 SpMV [ 34]。 Jee W. Choi 等人。提出了经典的分块压缩稀疏行(BCSR)和分块ELLPACK(BELLPACK)存储格式[5],它可以匹配或超过最先进的实现。他们还开发了一个性能模型,可以指导矩阵相关参数调整,这需要对 GPU 架构进行离线测量和运行时估计建模。杨等人。提出了一种新颖的非参数和自可调方法[49]来计算该内核的数据表示,特别是针对表示幂律图的稀疏矩阵。他们考虑了呈现幂律图的矩阵中非零分布的偏斜。
稀疏矩阵存储格式选择之所以需要,是因为已经针对不同的应用场景和计算机体系结构提出了各种格式[52]。在[33]中,Sedaghat 等人。研究 GPU 架构、稀疏矩阵表示和稀疏数据集之间的相互关系。此外,他们构建了一个基于决策树的模型,以在给定 GPU 平台上自动选择给定稀疏矩阵的最佳表示。决策树技术也在[20]中使用,其中Li等人。开发稀疏矩阵向量乘法自动调整系统,以弥合特定优化和通用用途之间的差距。该框架为用户提供了CSR格式的统一编程接口,并在运行时自动确定任何输入稀疏矩阵的最佳格式和实现。在[52]中,赵等人。建议使用深度学习方法选择合适的格式,与传统的机器学习技术相比,使用深度学习可以避免为学习目的而提出正确的矩阵特征的困难。结果表明,基于 CNN 的技术可以将格式选择错误减少三分之二。
7 Conclusion
本文使用五种主流矩阵表示形式对两种新兴多核架构上的 SpMV 性能进行了全面研究。研究 NUMA 绑定、矢量化和 SpMV 存储表示如何影响运行时性能。实验结果表明,性能最佳的稀疏矩阵表示取决于底层架构和输入数据集的稀疏模式。为了便于选择最佳表示,使用机器学习自动学习模型来预测给定架构和输入的正确矩阵表示。模型首先进行离线训练,学习到的模型可用于任何看不见的输入矩阵。实验结果表明,模型在选择矩阵表示方面非常有效,在评估平台上提供了超过 90% 的最佳可用性能。