Efficiently Running SpMV on Long Vector Architectures
Efficiently Running SpMV on Long Vector Architectures
Abstract
稀疏矩阵-向量乘法(SpMV)是并行数值应用的一个重要核心。SpMV中存在稀疏和不规则的数据访问,这使得它的向量化变得复杂。这些困难使得SpMV在运行于利用SIMD并行性的长向量ISA时,经常出现非最优的结果。在这种情况下,开发新的优化方法成为了使SpMV在新兴的长向量架构上实现高性能执行的基础。本文通过提出几种新的优化方法,改进了最先进的SELL-C-𝜎稀疏矩阵格式。作者针对长向量架构,如NEC Vector Engine。通过结合多种优化方法,在考虑24个异构矩阵的情况下,平均比SELL-C-𝜎提高了12%。作者的优化方法提高了长向量架构的性能,因为它们实现了高度的SIMD并行性。
1 Introduction
SpMV是HPC中常见的一个计算kernel。在线性系统中通常通过迭代方法求解,在这个执行过程中使用SpMV kernel。此外数据分析领域的工作负载需要通过SpMV来操作高度不规则和稀疏的矩阵。因此,有效地执行这个基本的线性代数核心是至关重要的。
SpMV的性能影响因素很多。一些提升性能的困难为:
- 对向量x的访问与矩阵A的稀疏模式有关,对x的访问不规则且难以预测。
- 𝑥是SpMV中涉及的唯一一个可以利用一定程度的数据重用的数据结构,但其访问的不规则性使得很难充分利用这些重用机会。
- 由于矩阵中的不同的非零值分布,会带来控制流分歧(多个线程或处理单元同时执行指令。当在执行中需要根据条件进行不同的操作时,就会发生控制流分歧。这可能导致一些线程需要等待其他线程完成它们的工作,从而影响整体性能)而影响性能。在GPU或长向量处理单元上这样的问题会显著限制性能。
对于最常见的稀疏矩阵存储格式CSR,对x的访问是不规则的,并且控制流分歧严重。因此有一些其他方式通过增加数据存储来换取对x访问的局部性的提升。SELL-C-σ和ESB是另外两种格式,通过分块和行排序来提高对x访问的局部性。许多方法提供了很好的性能,但是仍然可以针对长向量架构进行优化,本篇文章作者的工作主要有:
- 作者针对长向量架构改进了SELL-C-σ,在NEC SX-Aurora Vector Engine实现了117GFlops的78%的峰值内存带宽。展示了如何在新兴的向量ISA(如Arm SVE或RISC-V向量扩展)上处理稀疏数据结构。
- 实现评估了一些优化方法在长向量架构机器的优化效果。
- 与一些针对多核CPU或GPU设备的先进SpMV实现进行了比较。证明了作者的方法分别实现了3.02x和1.72x的加速比。
🔰NEC SX-Aurora Vector Engine:高性能向量处理器,向量长为16 kbit,支持谓词操作,可以执行基于条件的向量操作。
🔰Arm SVE:SVE是ARM在其v8-A架构中引入的较新的向量指令集,它的设计更为灵活,支持可变长度的向量。这使得SVE能够更好地适应不同应用和硬件的需求。SVE引入了矢量长度的概念,允许程序在运行时选择不同的矢量长度,而不是被限制在固定长度的向量上。这种可伸缩性使SVE能够更好地适应不同计算需求。早期的NEON指令集主要专注于嵌入式系统和移动设备上的加速,而SVE则更为灵活,适用于各种不同类型的计算,包括高性能计算和服务器领域。
2 Background
稀疏矩阵的常见存储格式有以下这些。
CSR
压缩稀疏行(CSR)是一种最常用的表示稀疏矩阵的格式。它按行顺序将非零(NNZ)元素的值和列索引分别存储在两个数组中。第三个数组保存了每一行在这些数组中的起始位置的指针。CSR的主要优点是它对任何类型的矩阵元素分布都有很大的压缩比,以及可以顺序地访问𝐴的值和列索引的可能性。它的主要缺点是不适合向量架构,以及𝑥访问的局部性差。
ELLPACK
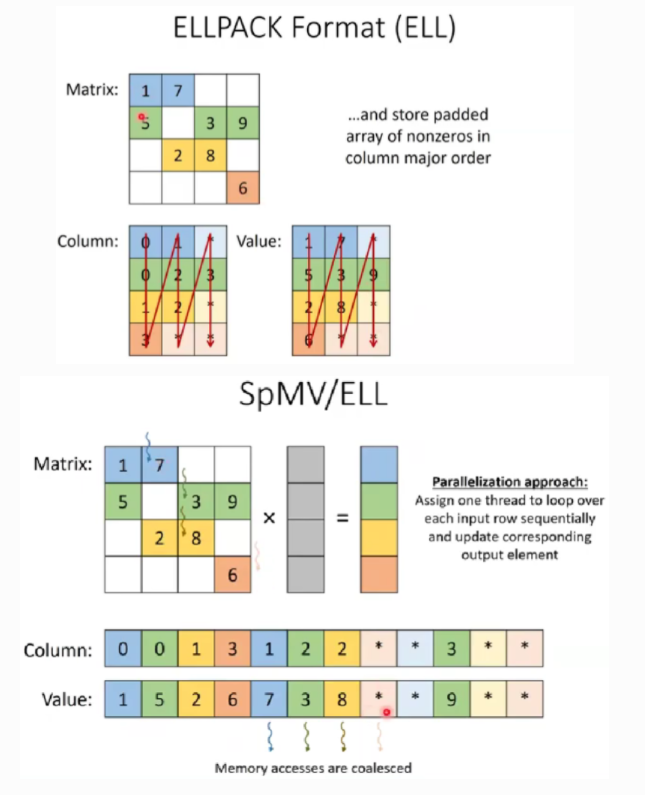
是为了在GPU和向量架构中高效地执行而设计的。与CSR相比,它通过以列顺序存储和访问非零元素,以增加存储的代价,提高了对𝑥的内存访问的局部性。对于一个大小为𝑀 × 𝑁的矩阵𝐴,如果每行的最大长度为𝐾,它需要一个大小为𝑀 × 𝐾的数组来存储𝐴。ELLPACK的主要缺点是它只有在存储的矩阵具有规则的每行NNZ元素时,才能提供良好的性能和压缩。尽管两个压缩矩阵是二维的,实际计算中会将其按列存储为一维,然后由GPU的threads进行计算,每个thread一行。
Sliced ELLPACK是ELLPACK的改进,将矩阵的行按照非零元素的个数排序,再将整个矩阵划分为固定行数的切片,这样每一切片中的行长度相近,可以更好的利用缓存局部性。适用于非零元素数分布不均匀的稀疏矩阵。
SELL-C-σ
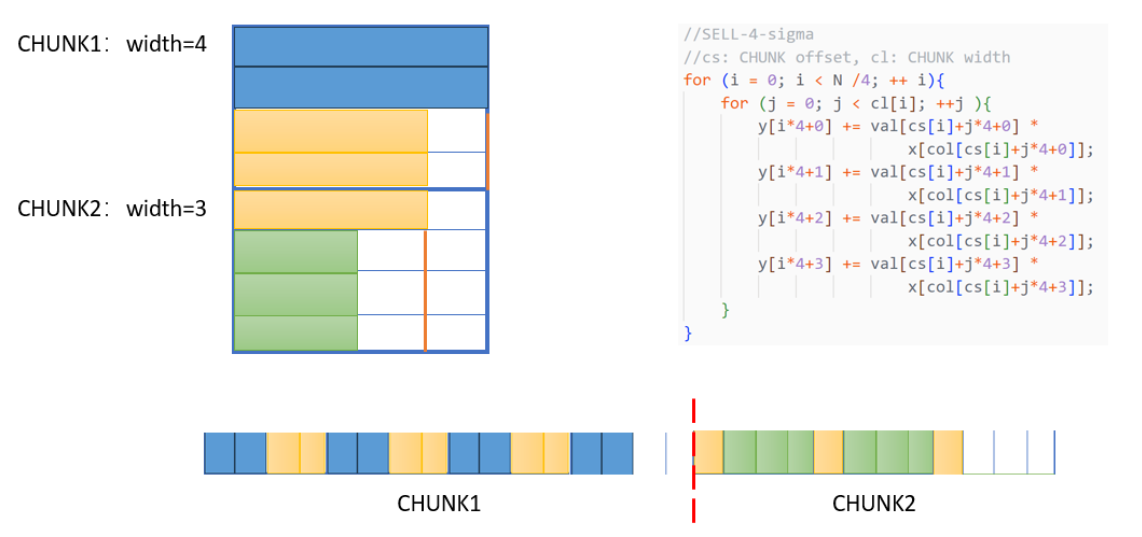
SELL-C-σ是基于Sliced ELLPCAK的改进。将矩阵按行分为指定大小的CHUNK,并只对指定σ行进行排序,避免大规模排序的性能开销。下图中C=4,σ为8。在GPU上,最小的C为32,即一个warp的大小,在CPU上则应该为向量单元的长度。
ESB(ELLPACK Sparce Block)
ESB引入了两个额外的优化来降低带宽需求:列阻塞和使用位数组来屏蔽指令。为了提高访问的局部性,ESB将矩阵拆分为列块或片块。ESB使用位数组数据结构为切片的每一列存储一位掩码。对于列中的每个非零元素,位被设置为1。该信息稍后用于屏蔽SIMD操作的元素。它实现了大的压缩率,因为它不需要零填充(在”针对长向量架构的优化-通过调整向量长度应对控制流分歧”部分说明这是如何实现的)。
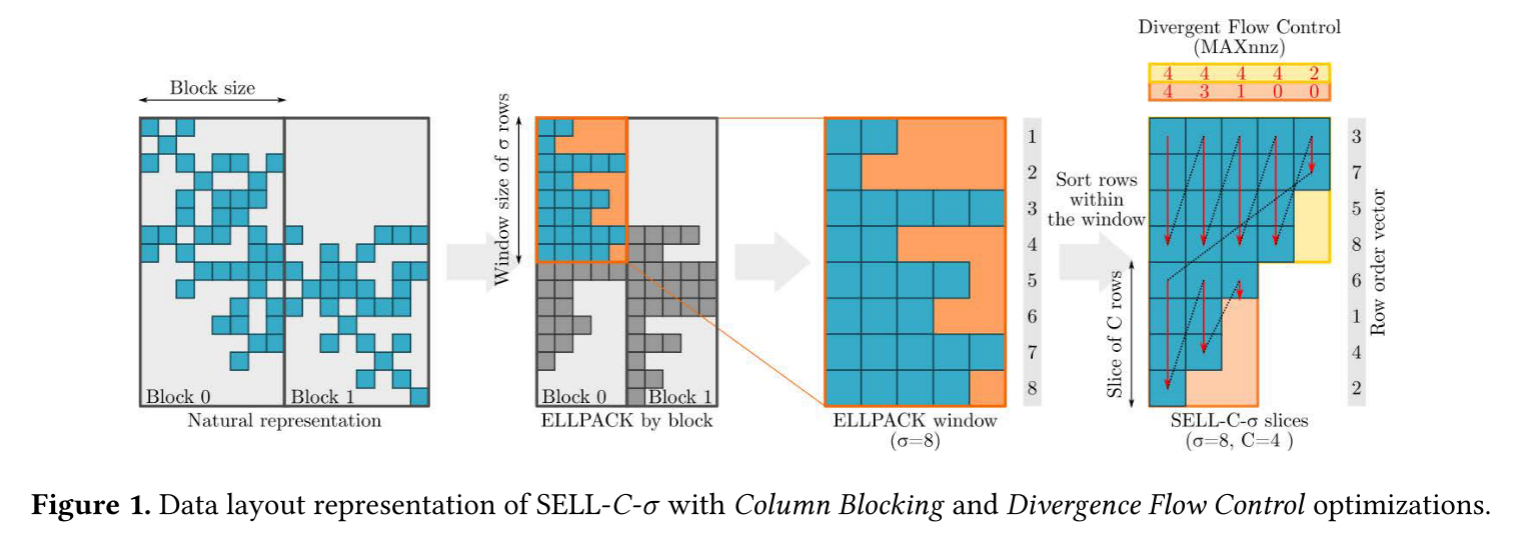
作者给出的该图中,最右侧的是采用了控制流分歧优化的SELL-C-σ,不需要0填充。
3 Contributions
3.1 SELL-C-σ格式的实现
SELL-C-σ是向量架构下高效的稀疏矩阵格式。因此作者以SELL-C-σ为基础来实现SpMV。首先作者使用了一些已有的优化手段,并针对长向量架构做了调整,主要是三个部分:
- 选择随着σ参数的增加,同时考虑性能和预处理开销的合适的排序策略。
- 使用不同粒度的任务大小来调整任务并行中格式缩放的影响。
- 使用列分块提升访问向量x的局部性。
排序策略
SELL-C-σ格式需要矩阵行根据NNZ元素个数排序,这开销可能很大。作者采用基数排序降低开销。矩阵被分为不同的子集部分,在内部进行排序,而各子集的排序可以并行完成,使用OpenMP就可以实现。子集被称为reorder window,大小为σ。在使用了控制流分歧优化的基础上,作者测试了排序的性能及最佳的σ值。σ取16K可达到最佳性能,比σ取256性能提高30%,但在预处理阶段需要40%-50%的额外时间。在测试时,将矩阵转换为SELL-C-σ格式需要10到15次迭代。作者使用row_order[num_rows]存储矩阵的行顺序。
任务并行
作者将工作负载分成不同的任务,并行执行,使用OpenMP来处理任务。理想中的任务粒度取决于输入矩阵,因此作者进行了可扩展性测试,最多8个线程,任务数量为8-256。任务处理类似工作量但稀疏程度不同的矩阵。结果说明最佳的工作负载性能不应创造过多的任务。工作负载划分为8-64个任务最好。后续实验也采用了8-64个任务的配置。
列分块
已有工作分析了列分块对SpMV的影响,不过仅限于Xeon Phi,SIMD宽度为512位。作者扩展了SELL-C-σ,实现了类似的分块,测试这样优化的效果。
3.2 针对长向量架构的优化
作者针对SX-aurora类似的长向量架构做了一些优化:
- 通过缓存分配提升x的重用以及减少存储依赖(降低存储指令之间的依赖关系的优先级,从而允许一些不违反内存顺序的加载指令提前发出,而不用等待之前未解决的存储地址。)。
- 自适应向量长度的控制流,避免存储和计算0填充元素。
- 使用部分循环融合❓在SELL-C-σ中实现循环展开。
- 使用特殊指令实现高效的gather和scatter操作。
作者所有的优化都是基于以下的基本实现代码的:
1 | void sell_c_sigma_mv(mtx, x, y, num_rows) { |
🔰TIP:这里要注意的是,前述的SELL-C-σ格式,每个切片内的元素的按照列存储的,切片是按顺序存储的。所有的切片行数相同,最后一个切片的长度也是,在values和col_indices也是这样对齐存储的,这样做是为了方便向量化操作,因此更新values的地址时要+maxvl,多余的部分也要跳过。
缓存分配和存储放松
在SpMV中,对矩阵A的访问和复用特性与对x的有很大差异。访问A的数据结构时步长是1且不会重用,而对x的访问是随机的但会重复使用。为了实现更好的性能,需要尽可能的实现数据的重用,来减少内存带宽的压力。长向量架构通常提供显式的缓存替换策略选择。充分利用这个特性,可以设定含有values和col_indices的缓存行最先被换出,从而降低向量x被换出的可能性。这被称为非缓存加载(Non-Cacheable load)。
另一个方面是存储策略。作者使用一个向量寄存器存储一个slice内的中间结果,结束后通过scatter指令存储数据。分散存储指令会根据地址范围计算依赖性,这可能导致尽管具体地址不同,但延迟访问该地址范围的后续存储指令。由于我们知道scatter之后的指令不会访问相同的内存地址,所以可以指示硬件不要检查scatter和后续指令之间的依赖关系,这被称为Store Overtake。在这部分relaxation
period结束后再插入memory fence指令。现代向量处理器支持这样的依赖放松。
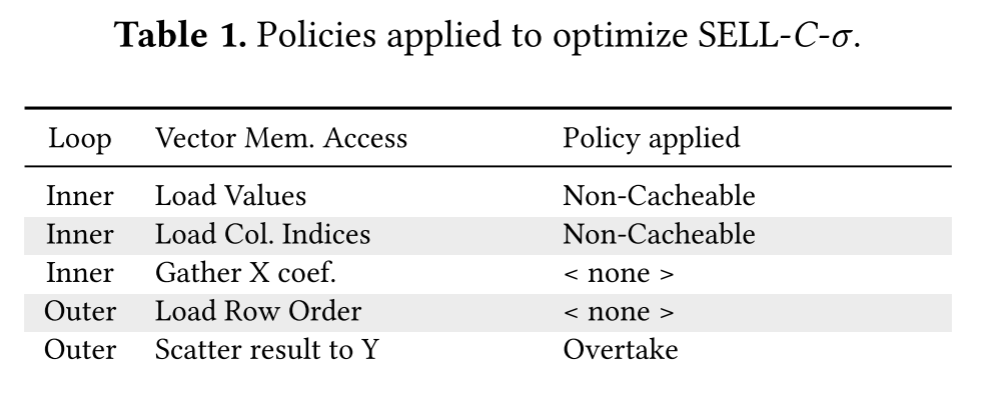
通过调整向量长度应对控制流分歧
每行的非零元素数量不一样,会导致循环迭代时的每行数据控制流分歧。例如假设有4列4行,前两行有4个非零元素,后两行只有2个非零元素,按列计算的迭代共有4轮,但后两行在最后两轮迭代其实没有计算,浪费了计算资源。
一个处理控制流分歧的流行技术是使用谓词寄存器。这种寄存器包含了一个位数组指出哪些元素为0。AVX,SVE都支持这样的寄存器,使编译器能够向量化不规则的循环。但是这需要大量的存储空间,因为每个向量元素都需要一个相应的mask,而且有许多实现不是不处理0元素,而只是处理后忽略无意义的结果。
作者提出了一种新方法来应对控制流分歧,这种方法依赖于向量元素数量(Ve)和向量通道(Vl)的比率,这种方法被作者称为Divergent Flow Control (DFC)。计算向量需要Ve/Vl个batch,作者的方法就是只要求硬件处理MAXnnz/Vl个batch,而且MAXnnz的大小受到向量寄存器的限制,对于SX-Aurora,向量寄存器存储256元素,因此MAXnnz在1~256之间,用一个字节就可以存储MAXnnz的信息。这里不明白作者命名MAXnnz中MAX表示什么,不过优化的操作如下:
回顾上文,由于切片内数据是按列计算的,因此向量存储的是一列的数据,假设我们有一个如下的Slice,Vl是2,如果未优化,那么向量长度(列长)是4,计算需要两个batch,而最后一行的最后一个batch的计算是没有意义的,因此额外添加一个数组,记录每一列的NNZ数量分别为4 4 4 4 2,这样最后一列(最后一个向量)就只计算一个batch,从而实现性能的优化。而一个slice的行最多有256个(SX-Aurora的向量长度限制),因此每一列NNZ元素数量只要一个字节就可以记录。作者使用一个active_lanes来实现这种优化,这个数据结构包含每个切片要执行的每个列向量操作的值。
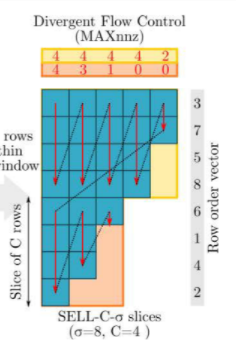
循环展开
循环展开是一种常见优化,可以减少控制流开销。在这里作者增加列向量长度来提高向量x的局部性,同时最大限度提高寄存器文件上的数据重用。
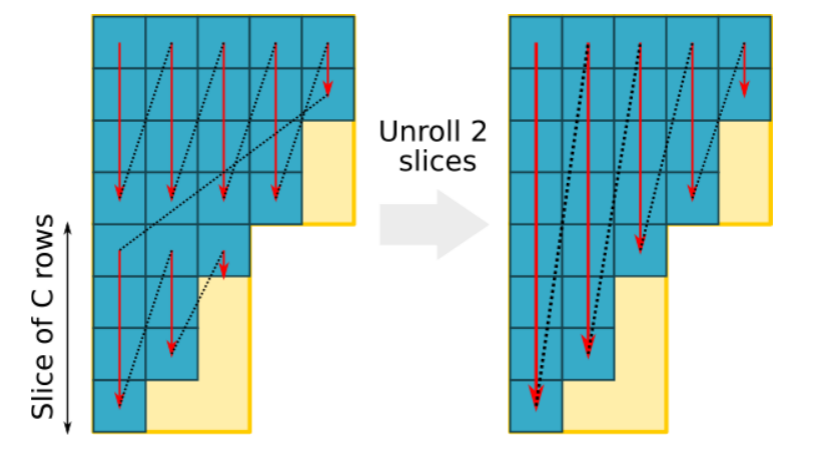
但是这种循环展开在这里的有效实现并不简单,展开的问题在于每个切片具有不同的宽度,每个切片的宽度都小于或等于前一个切片的宽度。因此需要在最后额外计算slice1的最后几列,同时计算slice1和slice2循环的列数是slice2的列数(行宽swidth)。此外,σ应该是展开的所有切片行数的倍数。
展开大小受向量寄存器数量的限制。由于每次展开时局部变量的数量都会增加,因此重要的是要在使用它们的最直接的上下文中声明它们,这使得编译器更容易管理寄存器依赖项、应用特定于体系结构的优化并避免溢出。作者的实现能够在具有192个架构寄存器的向量架构上最多展开8次,而不会产生任何溢出访问。
作者进行两次展开的示例如下:
1 | void sell_c_sigma_mv_unroll(mtx, x, y, num_rows) { |
gather/scatter地址的高效计算
在SpMV中,gather用于获取非连续的x元素,而scatter存储元素到结果向量y中时,是通过起始地址+行索引*数据大小计算的。对此进行优化,跟有加法运算的乘法指令可以被单个移位和加法指令取代。这在上面的代码中已经应用了。
为了评估优化效果,作者创建了五种实现,进行了测试,在此后的章节进行评估,这五种实现为:
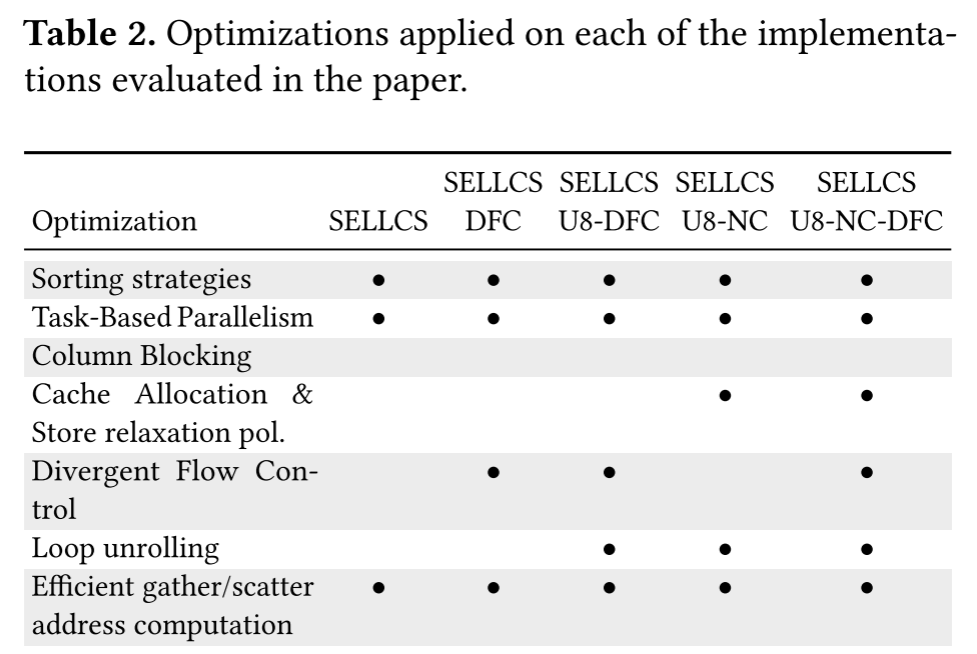
4 Methodology
这一章描述了评估的实验设置。作者的实现是在NEC SX-Aurora上的,用于比较的系统有:
- Intel Xeon Platinum 8160 CPU:24核2.10GHz。L1缓存32KB,L2缓存1024KB,L3是所有核共享的,大小为33792KB。每个核都有AVX-512SIMD单元,支持512bits即16floats,8doubles的向量计算。
- NVIDIAV100 (Volta) GP-GPU:84SM,最大1.5GHz。84SM共享6144KB的L2缓存,4096GB的高带宽存储器(HBM2)。
4.1 SX-Aurora VE
NEC SX-Aurora VE是NEC长向量架构的最新实现,结合了SIMD和流水线。向量单元和向量寄存器在8周期深的流水线中使用32*64位宽的SIMD,最大向量长度为256×64位或512×32位元素。本文的VE10B处理器2018年发布,并进行了性能评估。VE的6层每层8个HBM2的48GB总容量的内存接口可以提供172.4 GB/s的内存带宽,8核共享。
SpMV运算的性能优势在于大内存带宽,但同样重要的是处理器的其他特性,如内存延迟隐藏或缓存机制。8个VE核心的每一个都有一个标量处理单元(SPU)和一个向量处理单元(VPU),连接到共用的16MBLLC(末级缓存)。核到LLC的带宽是406.9GB/s,是双向的。因此4个内核可以实现内存带宽的饱和。每个VPU有64个256 ×64位元素的架构向量寄存器,硬件中有三倍的寄存器,用于寄存器重命名。三个融合乘加向量单元在1.4 GHz时可提供每核269 GFLOPS(双精度)的峰值性能,在1.6 GHz时可提供307 GFLOPS(VE 10A型号)。所使用的VE变体的峰值性能为2.15 TFLOPS。具有8个核心的粗粒度并行性和向量级别的细粒度并行性。
VE作为PCIe卡集成到其主机中,并将操作系统功能完全卸载到主机。它们以多任务和多处理模式运行,像标准CPU一样,程序可以运行在VE上,将部分代码卸载到主机(反向卸载),或在主机上运行,并将计算内核卸载到VE(加速器,卸载模型)。异构程序也可以使用NEC提供的混合MPI构建,该混合MPI连接在主机和VE上运行的进程。在所有情况下,程序员都可以使用C、C++、Fortran等语言,并与MPI和OpenMP并行化,而加速器代码仍然可以透明地使用几乎任何Linux系统调用。
NEC的专有编译器在指令的帮助下支持自动向量化。它们能够使用高级语言循环构造的扩展向量引擎ISA的大部分功能。对于本文提出的工作,我们需要更严格地控制VE功能,如向量掩码生成和控制、向量寄存器和数据的LLC缓存亲和性。因此,作者使用开源的LLVM-VE项目,它支持允许完全控制生成的代码的内部函数。
4.2 Experimental Setup
作者使用了在最近的文献中频繁使用的代表广泛HPC应用问题的矩阵来评估。下表列出了矩阵及一些特征,这些内容可在SuiteS-parse Matrix Collection repository找到。
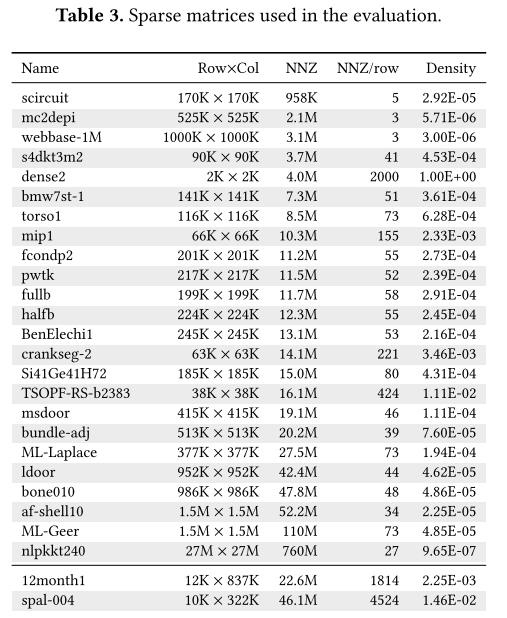
对于作者在VE中的Sell-C-𝜎实现,作者使用LLVM-VE v1.8进行编译,并链接NEC的专有编译器NCC v3.0.1。作者还使用一些专有的数学库进行平台间的性能比较:适用于上述VE、NVIDIA V100和Intel Xeon系统的NLC 2.0、cuSPARSE v10.2和MKL v2020.0。所有这些库都是在2019年或2020年发布的。所有代码都是使用-03优化级别编译的。为了便于重现,作者的资源库中提供了所有SpMV实现、开发的基准测试工具和用于每个系统的确切环境配置文件。
5 Evaluation
5.1 Performance of Long Vector Optimizations
作者测试了在第三章提到的不同实现的性能。SpMV的性能与稀疏矩阵的结构高度关联。因此并不期望优化在所有评估的矩阵上都有相同的性能提升。作者考虑了矩阵的大小和密度,以及硬件性能监控计数器(PMC)提供的事件信息。PMC能提供VE的一些指标包括:标量和向量指令数,平均向量指令长,缓存未命中率。作者测量了采用提到的优化之前与之后的这些指标,来分析优化的效果。
图4显示了考虑所有矩阵的GFLOP/s性能结果。共评估了六种实现。其中NLC表示使用NEC的数学库的结果。所有的测量都具有第三章所述的最佳σ和任务分配配置。
图4中的dense2和nlptkk240矩阵缺少值。在dense2的情况下,包含8切片展开优化的实现需要至少2048行才能正确执行,而该矩阵只有2000行。在nlptkk240的情况下,使用 NLC 在尝试分配数据结构时会耗尽内存。尽管存在这些问题,作者仍然包含这些矩阵,因为作者认为它们对于评估目的很有价值。

从图中可以看出,有两个矩阵(mip1和torso1)的测量性能,作者的实现明显比NEC数学库差。作者测试后发现8核运行时比单核运行时,执行的标量指令数大了一个数量级,这是因为OpenMP的工作负载分配不均衡导致的。
DFC evaluation
对于大多数矩阵,DFC的效果基本可以忽略,但对于高度不规则或非常稀疏的矩阵(webbase-1M和bundle-adj),DFC能有效降低向量长度,提高性能。对于webbase-1M,采用DFC比不采用DFC快了50%,平均向量指令长度从256降到了148。
Unrollling by 8 evaluation
作者将SELLCS-DFC和SELLCS-U8-DFC比较,评估循环展开效果。13/24的矩阵使用循环展开后带来了1%~15%的性能提升,也有特例如nlpkkt240带来了51%的性能下降。
循环展开引入了将slices分配给不同任务的限制。作者的实现要求循环展开的每一个slice都小于等于上一个slice。为了保证这一点,不允许两个排序窗口的slice出现在一个循环展开当中。在一个窗口中,slice一定是长度减小的。每个任务的slice数是8的倍数。这导致任务分配的粒度比较大,最终可能导致核心之间负载分配的不平衡。bundle-adj循环展开后的情况就是由于上述原因,第一组slices的NNZ数量非常不均匀,由于上述限制,全部分配到一个task当中了。
图4表明采用循环展开,行数较少的矩阵优化效果比较好,行数较多的则受益不大。PMC数据指出了性能的提升来源于向量指令计算时间的减少。对于MLGEER和MLLaplcace,循环展开带来了14%和7%的向量负载吞吐量,这不仅来源于对x访问的局部性的提升,也来源于向量指令的并行度提升。
Cache allocation and store relaxation policies
将SELLCS-U8-NC-DFC和SELLCS-U8-DFC比较,可以评估缓存分配策略和存储放松的优化效果。有2/3的矩阵都有5%~12%的性能提升。作者选取了ldoor和pwtk进行进一步的分析,这两个矩阵优化后分别提高了8%和6%的LLC命中率,并提高了10%和8%的单周期向量加载元素。并且所有的矩阵都有最大50%的L1缓存缺失的减少。没有任何一种采用优化后性能会降低的情况,这说明缓存分配策略和存储放松优化适用于任何情景。
Applying all optimizations
所有的优化可以在所有的矩阵取得平均90.3GFLOPs的性能,这比基本的SELL-CL-σ和NEC数学库的性能分别提升了12%和17%。这证明了作者优化的重要性。
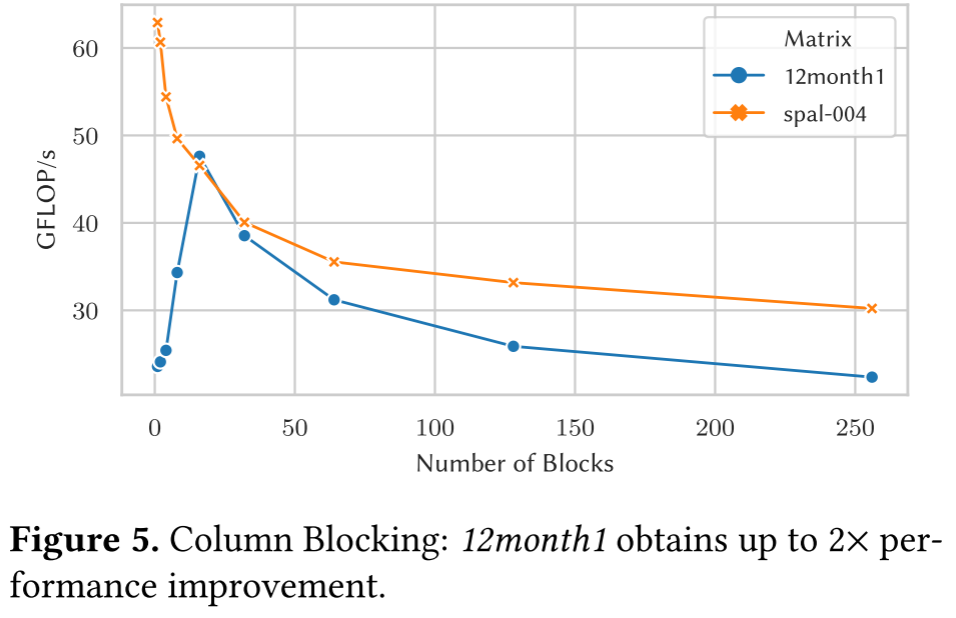
Applicability of column blocking
作者还尝试了列分块,但是列分块没有任何性能的提升。一些前期的在SIMD架构的的研究表明只有在有很长的行的矩阵才有效。所以作者又测试了另外两个矩阵spal_004和12month1,这两个矩阵有很长的行。如图5,12month1可以通过16分块得到2x的性能途胜,但是在spal_004,性能随着分块增加而降低。因此可以说明,虽然列分块在长向量架构中的适用性似乎有限,但在某些特定情况下它可能会对性能产生巨大的影响。
5.2 Comparison with state-of-the-art HPC architectures
作者比较了在VE上运行采用全部优化的SpMV和在Intel和NVIDIA平台使用对应数学库的SpMV的性能和能耗。测试选取了每个矩阵在每个平台的最好结果,并包含了矩阵加载和预处理的时间。能耗测试时SpMV算法运行600K次迭代,使预处理和加载矩阵的总占比时间小于10%。
图6展示了这三个平台的性能对比。下方的图表示与MKL结果相比的归一化能耗。平均而言,SELLCS-U8-NC 分别比 cuSPARSE 和 MKL 提高了 1.72𝑥 和 3.02𝑥。在能源效率方面,SELLCS-U8-NC 与 cuSPARSE 相比能耗降低 22%,与 MKL 相比能耗降低 9.09 倍。
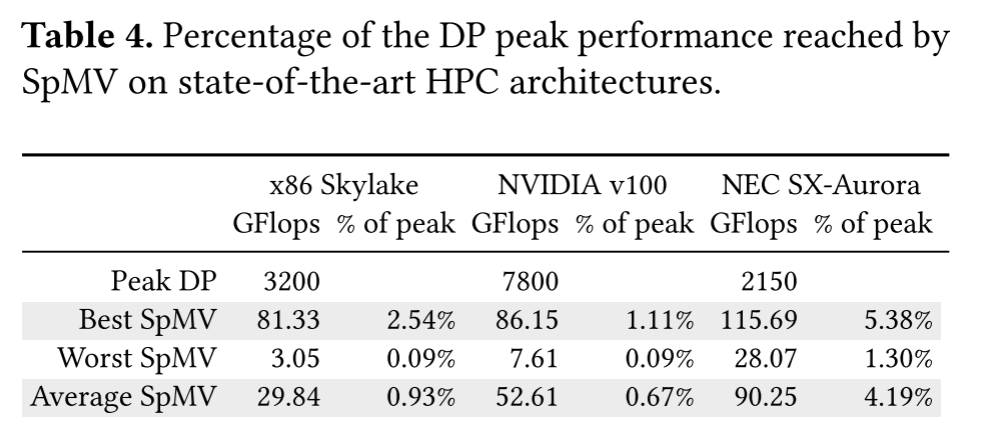
此外,图 6 上半部分所示的 VE 性能数据略低于图 4 所示的性能数据。不匹配平均低于 5%,这是引入了VE的能耗检测带来的开销。作者从比较中排除了两个矩阵:dense2,因为与展开优化不兼容;和 nlpkkt240,由于库中的内存管理错误。在表 4 中,作者给出了三种架构各自实现的双精度峰值性能的百分比。

6 Related work
由于 SpMV 是多种科学计算算法中至关重要的核心,因此在过去 20 年中已经发表了大量关于许多架构上的 SpMV 优化的研究。最近,研究社区正专注于开发高效的 SpMV 实现,针对具有不同并行度的新兴架构,例如大量内核和长 SIMD 或向量单元。然而,大多数研究仅限于 CPU 中的 8 元素 SIMD 单元或 GPU 中的 32 元素扭曲 [4,8,9,13,14,16]。即使这些方法考虑了具有 AVX-512 扩展功能的最先进的英特尔 CPU 和最新的 GPU,但与作者在研究中考虑的 256 个双精度元素矢量平台 SX-Aurora 相比,它们还是有差距。
多项研究提出了能够利用 SIMD/向量单元的新格式。他们通过添加零填充来创建连续元素块。然而,由于这些格式依赖于拥有足够大的彼此靠近的 NNZ 元素组才能高效,因此它们不适合长向量架构。
有一些研究提出了一种两步 SpMV 算法,该算法对大数据矩阵显示出良好的性能改进。使用前一项工作(Implement-
ing a Sparse Matrix Vector Product for the SELL-C/SELL-C-𝜎 formats on NVIDIA GPUs.)的作者提供的代码,作者能够在类似于他们研究中使用的 x86 系统中重现结果。但作者无法使用性能接近 VE 中 SELL-C-𝜎 代码的内在函数来开发有效的实现。
7 Conclusion
作者针对SX-Aurora长向量架构的SpMV实现显示了非常有竞争力的性能结果,大部分超过了NEC库集合中的高度优化的专有实现。作者使用开源编译器LLVM作为计算内核,并讨论了各种也可以应用于其他算法的优化。该实现适用于VE本机库,可从VE程序调用,可以轻松转换为可直接从主机上运行的程序调用的卸载库,以加速主机本机程序。该用例实际上将为预处理步骤带来调整机会,而该步骤在优化方面受到的关注较少。通过在主机端运行排序,作者预计会减少矩阵设置时间。
与其他高端架构相比,图6中的性能结果表明SX-Aurora性能非常有竞争力,平均胜过竞争架构Xeon Skylake Platinum和Skylake Platinum的两个标准库MKL和cuSparse。尽管VE的峰值性能最低,为2.15 TFLOPS,而Skylake的峰值性能为3.2 TFLOPS,V100的峰值性能为7.8 TFLOPS,但它可以利用其卓越的内存带宽,实现比竞争对手更高的SpMV性能。表4中的结果表明SX-Aurora是一个平衡良好的架构。其0.567 byte/FLOP与以显式并行的长向量 ISA 配合使用,可实现最高的最大和平均性能效率百分比,分别为峰值的5.38% 和4.19%。
从能耗考虑,加速器优于通用CPU,即便是使用了SIMD和高度优化的库的CPU。此外,性能测量表明长向量架构符合内存带宽要求的数据并行工作负载(例如 SpMV)的要求。