Performance Optimization of SpMV by Considering Scheduling on CPUs
Performance optimization of SpMV using CRS format by considering OpenMP scheduling on CPUs and MIC
该篇论文是2014年发表的,比较久远了。作者关注的是通过调度对SpMV优化,测试了使用不同OpenMP调度方式和chunk_size对性能的影响,发现对于一些矩阵性能影响会比较大,因此以AT的方式,先测量最佳调度方式,此后再使用最佳方式。autotune的方式是当时比较多的研究,现在采用模型预测最佳方式的研究比较多了。对于小矩阵,静态方式更快,对于大矩阵,动态方式可能更快,这是选择调度方式的一个依据。
Abstract
这项研究中,作者评估了CSR格式下SpMV的性能与OpenMP调度设置之间的关系,并对结果进行分析,表明OpenMP调度对SpMV性能有很大影响。作者通过改进调度设置提升了SpMV的性能。
1 Introduction
在SpMV中通过OpenMP进行并行化是非常常见的。作者的研究通过调度设置来提高SpMV的性能,不提出新的调度算法,而是有效利用现有的调度方法,使用 Fujitsu 的 SPARC64 IXfx CPU、Intel 的 Xeon CPU 和 Intel 的 Xeon Phi MIC 测量许多稀疏矩阵的性能。作者使用了一系列 OpenMP 调度参数并评估它们的性能。
本文的其余部分安排如下。第2节介绍了一些相关研究。第 3 节包含目标矩阵的一般描述。第 4 节描述了计算环境和实现。第 5 节介绍评估的结果。第 6 节解释了新方法在 OpenATLib 中 SpMV 函数中的应用。最后,第 7 节给出了结论。
2 Related Work
作者之前发表了在 CPU[9] 和 GPU[10] 上计算 SpMV 的研究。还开发并提供了用于 CPU 的自动调整数值库,称为 OpenATLib 和 Xabclib [11]。这些库提供了一些用于 SpMV 计算的 SpMV 函数和数值求解器。之前的研究还没有针对 OpenMP 中的调度设置来探讨 SpMV 在当前多核 CPU 和 MIC 上的性能。因此本篇中作者关注调度设置来优化SpMV性能。
3 Target Matrices
为了分析稀疏矩阵与性能之间的一般关系,作者使用佛罗里达大学稀疏矩阵集合 [14] 中的 132 个稀疏矩阵作为目标矩阵。所有这些目标矩阵都是正定的。图 1 显示了目标矩阵中非零元素的数量和行数。最小非零元素数为 46,最小行数为 14(LFAT5 矩阵)。最大非零元素数为 77,651,847,最大行数为 943,695(audikw 1 矩阵)。
4 Computational Environment and Implementation
在以下部分中,描述使用两个 CPU 和一个 MIC 作为评估环境(表 I)。第一个 CPU 是 Fujitsu SPARC64 IXfx CPU,安装在 Fujitsu FX10 超级计算机系统。第二个 CPU 是 Intel Xeon E5 CPU,MIC 是 Intel Xeon Phi。将这些环境分别称为 SPARC64、Xeon 和 MIC。
为了评估 OpenMP 调度设置与其性能之间的关系,使用各种 OpenMP 调度设置实现了 CSR 格式的基本 SpMV 内核。作者使用 Fortran (Fortran90) 和双精度浮点值作为数据类型。 OpenMP 的循环并行化由 Fortran 中的 omp do 和 C 语言中的 omp for 应用,但 OpenMP 规范[15]定义了一些额外的调度变体(子句),如下所示。
- Static scheduling
omp do/for schedule (static, chunk size) - Dynamic scheduling
omp do/for schedule (dynamic, chunk size) - Guided scheduling
omp do/for schedule (guided, chunk size) - Runtime scheduling
omp do/for schedule (runtime)
应该注意的是,运行时调度使用环境变量在运行时从其他类型的调度中进行选择。此外,规范要求 no Schedule 子句的使用取决于实现,将其称为默认调度。在动态调度和引导调度中使用 no chunk size 子句与 chunk size = 1 相同。
作者实现并评估了默认调度和前三种调度方法,chunk_size取1-250,共754个测试(1+251+251+251)。
作者使用以下编译器、编译器选项和执行环境。对于 SPARC64,使用 Fujitsu Fortran 编译器 (frtpx 1.2.1) 并应用编译器选项:-Kfast、openmp、,间接预取、simd=2,使用 Fujitsu 用户指南中的示例。 OpenMP 线程数始终设置为 16。对于 Xeon,使用 ifort (IFORT) 14.0.2 并应用编译器选项:-xHOST -mcmodel=large -O2 -prec-div -openmp -align array32byte -shared-intel。 OpenMP 线程数始终设置为 20。对于 MIC,使用与 Xeon 相同的编译器并应用编译器选项: mcmodel=large -O2 -prec-div -openmp -align array64byte -mmic -shared-intel 。 OpenMP 线程数始终设置为 240。
5 Performance Evaluation
5.1 Overaall Performance
本小节描述总体性能评估。每次计算都会执行到满足执行次数超过1000次且总时间为1.0s的条件。然后选择平均计算结果。
图 2 显示了每种硬件类型的评估结果。图 2 (a) 说明了使用默认调度的 SpMV 的性能 (GFLOPS)。图 2 中的其他图显示了静态调度、动态调度和引导调度与默认调度相比的相对性能。对于不同的块大小,这三种调度类型是最快的。 x 轴根据非零元素的数量进行排序,方式与图 1 类似。
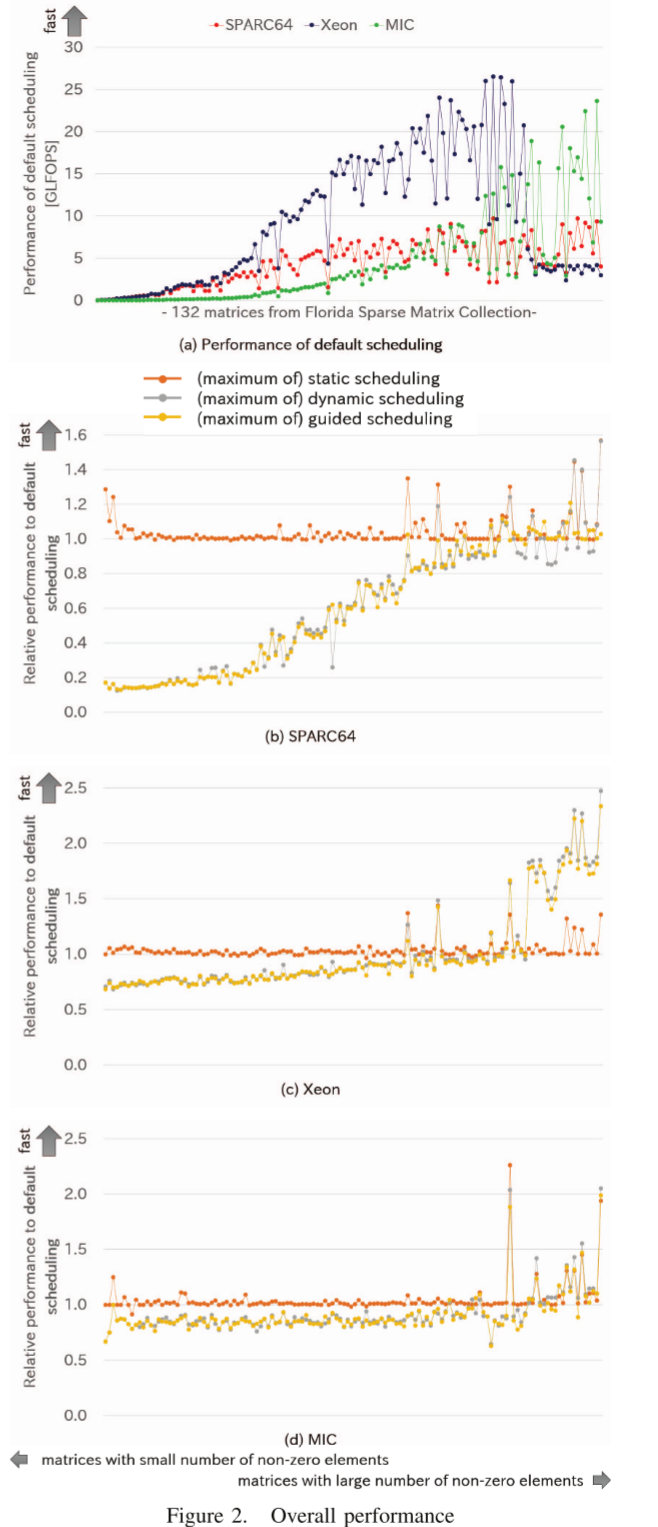
图2a显示性能与NNZ有关,NNZ超出缓存大小时,性能显著下降。
图 2 (b)、(c) 和 (d) 显示了所有三种硬件类型共有的一些性能趋势。
在小矩阵的情况下,默认调度和静态调度提供几乎相同的性能水平,并且它们都比动态调度和引导调度表现得更好。这是因为小矩阵的执行时间很短,动态调度需要一些处理线程的开销。这些结果表明,默认调度可以为小矩阵提供良好的性能,并且不可能通过优化这些矩阵中的调度来获得更好的性能。
大型矩阵的情况下,静态调度、动态调度和引导调度都优于某些矩阵的默认调度。对应的矩阵数量并不多,但对于某些矩阵,默认调度与其他方法的性能差异大于20%。因此可以认为这个结果表明优化的调度设置对性能有显着影响。作者还列出了这些矩阵,以及不同调度方式在三种硬件架构上相对于默认调度的最大加速比,此处就不列举了。这些矩阵被作者称为有利矩阵。
5.2 Performance Analysis
上一小节报告的结果表明,优化调度对所有三种环境中 SpMV 的性能都有相当大的影响。然而,性能基于许多不同的块大小值。因此,本小节重点关注优势矩阵,并考虑性能和块大小之间的关系。
图 3 显示了有利矩阵的性能与块大小之间的关系。 x 轴按块大小排序。 y 轴显示采用默认调度的每个硬件的相对性能,其中值 1.0 是前面小节中采用默认调度的性能。所有图表均显示相对于默认调度的最大、最小和平均性能。最大性能表示与使用每个硬件系统的有利矩阵的默认调度相比的最高性能。类似地,最低性能表示与使用每个硬件系统的有利矩阵的默认调度相比的最低性能。平均性能是与使用每个硬件系统的有利矩阵的默认调度相比的平均性能。

对于 SPARC64,除非块大小非常小,否则最大性能和平均性能不会受到块大小的太大影响。相比之下,最低性能受块大小的影响。 SPARC64 上的最高平均性能是通过静态调度和块大小 = 92 获得的,其中性能比为 1.21。
对于 Xeon,性能趋势与 SPARC64 非常相似。然而,静态调度的相对性能低于其他调度类型。其最大性能通过动态调度获得,块大小=204,其中性能比为1.70。
在 MIC 的情况下,性能趋势也与其他非常相似,除了小块大小通过静态调度获得良好的性能。 MIC 的最高平均性能是通过动态调度和块大小 = 57 获得的,其中性能比为 1.23。
有些参数代表了稀疏矩阵的特征,例如行数、非零元素总数、每行平均非零元素数。作者预计有利矩阵与每行非零元素数量的分布之间存在很强的关联。因此,动态调度和引导调度可以解决负载均衡问题,并获得比静态调度更高的性能。然而,获得的结果表明静态调度的性能与其他调度类型相同,并且我们没有检测到调度设置与非零元素数量分布之间的强关系。这可能是因为行数足够大;这样就在一定程度上解决了负载均衡问题。此外,与静态调度相比,动态调度和引导调度在处理线程时会产生更大的开销,因此动态调度和引导调度的性能可能会下降。动态调度和引导调度可能比静态调度表现更好,因为 Xeon 的线程管理成本非常低。然而,动态调度和引导调度受到计算时序的影响,因此很难完整地分析执行时序。作者将在未来的研究中进行这种分析。
6 Optimized Scheduling in OpenATLib
6.1 Approach and Implemention
正如上一节所述,OpenMP 的调度会影响 SpMV 的性能。因此,我们的目标是通过优化调度来提高 SpMV 在各种应用中的性能。然而,优化 OpenMP 调度以获得良好性能的条件尚未完全阐明。因此,作者目标是使用自动调整(AT)技术来优化调度。
之前,作者研究了 AT 技术并开发了名为 OpenATLib 和 Xabclib[11] 的数值库。 OpenATLib 提供各种自动调整数值函数,Xabclib 包含一些使用 OpenATLib 的自动调整数值求解器。 OpenATLib 中有一个自动调整的双精度 SpMV 函数,称为“OpenATI DURMV”。该 SpMV 函数包含 SpMV 的多个实现以及用于选择最快实现的 AT 机制。图 4 显示了 OpenATI DURMV 的流程。

第一次计算时,会测试哪种计算方法是最优的,此后就沿用这种方法,尽管这会带来额外的开销,但是鉴于SpMV通常对相同矩阵进行非常多次,代价会被摊销。
OpenATLib 提供的现有 SpMV 实现如下:
- 行分解法:行分解方法将目标矩阵划分为所需的线程数,以平衡每个线程处理的行数。此实现与上一节中的默认调度相同,其中块大小 = (非零元素数)/(线程数)。
- 标准化法:标准化 NZ 方法将目标矩阵划分为标准化每个线程处理的非零元素数量所需的线程数。该算法可以提供比行分解方法更好的性能,特别是当行中非零元素的数量存在较大差异时。
- BSS方法:当行中的非零元素之间存在较大差异且难以对其进行平均时,BSS 方法非常有用。该方法基于原始SS方法,适用于向量处理器。 BSS 方法已被修改,以便在多核处理器上获得良好的性能。此方法可以将行拆分为子段并将这些段分配给多个线程。
每种实现都有其优点和缺点。对于具有不平衡矩阵的 SpMV,行分解方法的性能较低。归一化 NZ 方法可能比行分解方法获得更好的性能,但性能很大程度上取决于行中元素数量之间的平衡。 BSS 方法适用于不平衡矩阵,但不适用于平衡矩阵,因为该方法需要额外的计算。因此,在执行之前很难确定哪种方法可以获得最佳性能,因此 AT 机制会很有用。
6.2 评估
为了评估优化调度的有效性,作者使用修改后的 OpenATI DURMV 测量数值求解器的性能,使用 Xabclib GMRES 函数。该函数求解线性方程问题Ax=b,其中A是大规模非对称稀疏矩阵,x是解向量,b是右侧向量。该算法的概述如图 5 所示。
作者使用三个有利矩阵和三个其他矩阵进行测试。评价结果如表2和图6所示。
对于有利矩阵,无论迭代次数如何,仅选择新的 SpMV 实现。改进的水平取决于目标矩阵,但是使用所有三个有利的矩阵都可以获得性能改进,除了在某些迭代次数非常少的情况下。对于其他矩阵,选择原始 SpMV 实现。尽管这些测量不包括搜索所需的时间(AT 开销),但在某些情况下会出现性能下降。这是因为运行 SpMV 所需的时间是可变的。可变性的影响通过多次迭代进行平均。然而,通过少量的迭代,效果就很明显。根据上一节中给出的结果,所有有利的矩阵都有望将性能提高 20% 以上,但并没有获得如此高的改进。作者认为这是由于缓存的可变性或行为造成的,其中 SpMV 以外的计算会更改缓存的状态。
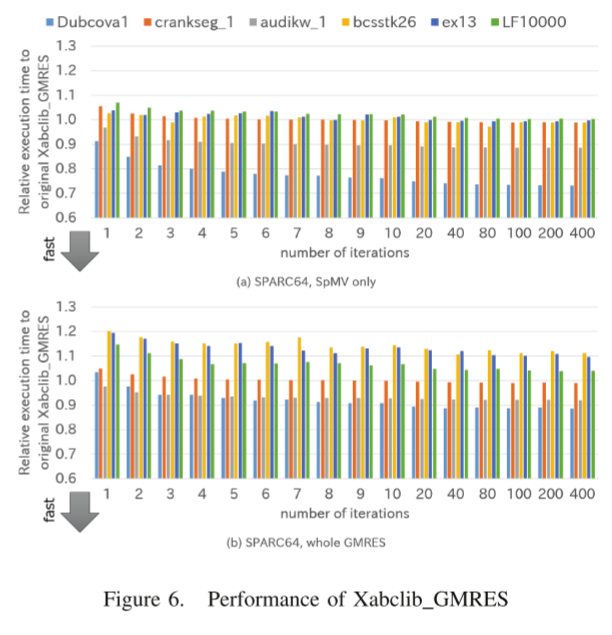
图 6 (b) 显示,通过大量迭代,所有三个有利矩阵都获得了性能改进。 AT 开销和性能改进相互抵消,因此在使用少量迭代时,cranskseg 1 矩阵会出现性能下降。然而,其他三个矩阵并没有提供我们预期的性能改进。为了减少AT开销,需要优化OpenATLib和Xabclib的AT机制。
总的来说,作者成功地确认了为每个目标矩阵选择了最佳的 SpMV 实现,并且在某些情况下减少了 SpMV 和 GMRES 的总执行时间。仅使用 SpMV(使用 Dubcova1 矩阵和 400 次迭代)的最佳性能改进为 26.7%,而使用相同 Dubcova1 矩阵和 400 次迭代的总体 GMRES 的最佳性能改进为 11.4%。这些结果证明了优化的调度方法的实用性及其在 OpenATLib 中的应用。
7 Conclusion
在本研究中,作者使用 CRS 格式在两个 CPU(SPARC64 IXfx 和 Xeon)和一个 MIC(Xeon Phi)上评估了 SpMV 的性能。我们评估了许多目标矩阵,并将性能与各种类型的 OpenMP 调度设置进行了比较。与默认调度相比,使用有利矩阵获得的最高平均性能改进为:在 SPARC64(块大小 = 92 的静态调度)上提高 1.57 倍,在 Xeon(块大小 = 204 的动态调度)上提高 2.44 倍,在 MIC 上提高 2.11 倍(块大小 = 57 的动态调度)。因此,OpenMP调度对SpMV的性能有相当大的影响。
然而,并非所有矩阵都获得了这些性能改进,并且很难确定是否可以获得比默认调度更好的性能。因此作者测试了自动调整技术的使用。作者修改了 OpenATLib 的 SpMV 函数,并使用具有特定调度设置的 SpMV 作为附加 SpMV 内核。评估了 GMRES 求解器的性能,并确认在某些情况下可以获得比默认实现更好的性能。仅使用 SpMV 就成功获得了高达 26.7% 的性能提升,而使用整个 GMRES 流程则成功获得了高达 11.4% 的性能提升。
在未来的研究中,作者将分析非零元素的布局与最佳OpenMP调度方法之间的关系。正如第 5 节所述,这是一个具有挑战性的问题,并且影响很大。自动选择调度设置的快速变化也是一个重要问题。然而,也使用除CRS格式之外的矩阵格式。因此作者还将优化 SpMV 与这些其他格式的性能进行比较,并在未来的研究中对这些其他格式应用相同的方法。