Performance analysis and optimization for SpMV based on ARM
Performance analysis and optimization for SpMV based on aligned storage formats on an ARM processor
这篇论文对毕设方向帮助很大。确定了重点在于优化而不是方法选择,因为ARM的SIMD向量只有128bit,很多格式没有必要,并且这里提出的对齐格式也给出了明确的优化效果分界点。这篇文章还在理论分析那一部分没有完全理解,估计以后还会看很多次。
Abstract
稀疏矩阵向量乘法(SpMV)一直是科学计算和大数据处理的研究热点,但稀疏矩阵中非零元素的稀疏性和不连续性导致了SpMV的内存瓶颈。在本文中,作者提出了对齐的CSR(ACSR)和对齐的ELL(AELL)格式以及并行SpMV算法,以在ARM处理器上利用 NEON SIMD寄存器。作者分析了 SIMD 指令延迟、缓存访问和缓存未命中对不同格式的 SpMV 的影响。在实验中,基于ACSR的SpMV算法分别比基于CSR的SpMV和PETSc中的SpMV实现了1.18倍和1.56倍的加速,而AELL比ELL实现了1.21倍的加速。ACSR中指令延迟和缓存访问的理论结果与实验结果的偏差分别为 10.26% 和 10.51%,AELL 中的理论结果与实验结果的偏差分别为 5.68% 和 2.91%。
1 Introduction
1.1 motivation
SpMV是数值计算的核心程序,在求解过程中可能会执行很多次。但是硬件的复杂性和矩阵的特性可能会导致内存瓶颈,使优化SpMV的性能具有挑战性。
已有的研究已经提出了多种稀疏矩阵存储格式,有些格式适合计算平台的计算。大多数对于SpMV的研究都是针对x86或其他加速器的。针对ARM处理器的工作很少。
ARMv8-A是ARM提出的高性能计算架构,因为其性能好,能耗低等特点,在移动设备中广泛应用。ARMv8支持64位指令和双精度浮点,并通过NEON指令集支持SIMD运算。并且2020的超算排名,集成48核A64FX的Fugaku取得了第一,这是首个ARM架构处理器实现的top超算。
1.2 contribution
这篇主要的工作为:
- 提出了对齐格式ACSR和AELL,适合NEON的双精度浮点运算。
- 提出了基于对齐格式的SpMV算法。
- 在鲲鹏920处理器上评估了两种格式的性能。
作者使用20个矩阵进行评估,结果NEON加速的SpMV在CSR中的平均性能提升达到 19.91%,在ELL中达到 19.15%。对于NEON的使用,与ELL相比,AELL在双精度计算时间、缓存访问和缓存未命中方面的平均性能提升分别为20.54%、34.10%和28.85%,而ACSR的平均性能提升为18.17%,与CSR相比分别为18.59%和18.00%。此外,基于ACSR的SpMV的平均加速度比PETSc中的SpMV高56.46%。
2 Related work
2.1. Compressed storage formats for sparse matrices
为了存储和加快稀疏矩阵运算,有许多不同的压缩格式,最基本有COO和CSR,还有针对对角矩阵的DIA格式,还有针对nnz元素比较均匀的ELLPACK格式。针对处理器设计存储格式可以最大限度提高性能,例如针对GPU和x86CPU的HYB、SELL-C-σ格式,CSR5、BCE等等。
实际应用中的稀疏矩阵规模越来越大,因此矩阵划分越越重要了。有一些研究比较了不同分块格式的性能,BCSR用于稀疏矩阵密集子块的计算,随后BCSR被优化为未对齐块压缩稀疏行(UBCSR)格式,还有许多类似的研究。
2.2 ARMv8-A
ARM结构的处理器广泛用于移动设备,但现在也有许多公司购买了该架构,研发了用于服务器的处理器。
3 Sparse matrix compression and NEON technology
3.1 General storage formats for sparse matrices
本节主要介绍CSR和ELLPACK格式。因为对这两种格式已经有了解了所以不详细阐述了。
CSR
CSR对矩阵的特征不敏感。使用三个数组来存储矩阵,一个存储值,一个存储col-idx,一个存储每一行第一个元素的下标。
ELLPACK
ELLPACK中,矩阵被压缩为两个小矩阵,存储元素和col_idx,假设每行最多有K个NNZ,两个矩阵的大小为NxK,空余部分用0填充。
3.2 NEON techknowlogy
ARMv8提供32个128bit的NEON寄存器。在向量乘时,向量x需要一个元素一个元素的存入SIMD寄存器。但是如果采用ACSR和AELL,SIMD寄存器可一次性用矩阵和向量值填充。
4 Aligned compressed storage formats
ARM的SIMD一般都是加载连续的数据到向量寄存器,而SpMV中由于x的访问是不连续的,只能一个一个load到向量中。为了提高效率,作者设计了ASR和AELL来使用ARM的SIMD结构。
稀疏矩阵压缩后,如果两个相邻非零元素的列索引也相邻,则在计算SpMV时,与这两个非零元素相乘的向量中对应的两个元素相邻。如果两个非零元素的列索引不相邻,则向量中对应的两个元素也不相邻。如果两个不相邻元素之间的距离超过了缓存行的宽度,则不可能一次将两个元素加载到向量寄存器中。如果两者的列索引之间的偏差小于8,则认为它们位于同一缓存行并在当前非零元素之前插入零。如果不是,则在当前非零之后插入零,这保证了填充操作不会在访问允许的情况下导致冗余的跨缓存行。
4.1 ACSR
ACSR中有三个数组,v_value存储了值及填充0,v_columns存储了每个向量的首个列index,v_rowptr存储了每行的第一个v_columns的index。
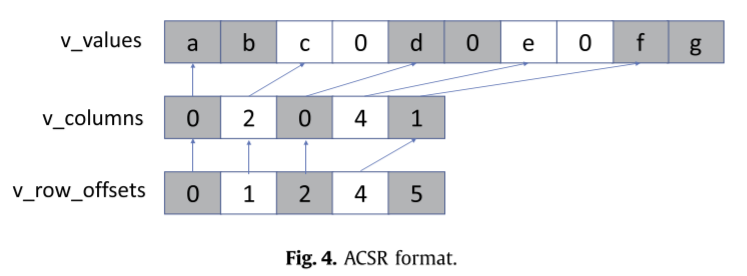
假设有M行NNZ,则非对齐CSR的存储空间为SCSR = NNZ x (4+8) + (M+1) x 4 = 12NNZ + 4(M+1),而ACSR的0填充率为FR,则SACSR = NNZ x (1+FR) x (8+4/2) + 4(M+1) = 10NNZ(1+FR) + 4(M+1),联立两式,当FR > 0.2时ACSR的存储需要比CSR更大的空间。
4.2 AELL
类似ELLPACK,只是做了0填充。
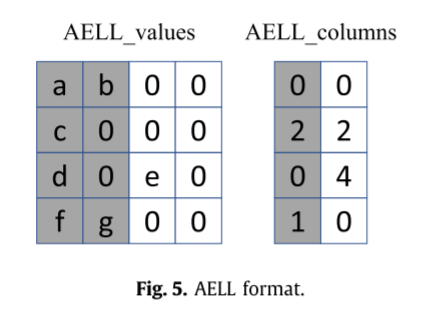
同样假设M行NNZ,则ELLPACK的存储空间为M x K x (4+8) = 12MK,如果AELLPACK的向量有Vk个,则存储空间为Vk x M x (2x8+4) = 20MVk,联立两式,当Vk>0.6K时AELL的存储空间会比ELLPACK更大。
5. Parallel algorithms of SpMV
CSR的SpMV核心用NEON实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14//The result vector is y
float64x2_t matrix;
float64x2_t vector;
float64x2_t temp_y;
temp_y = vdupq_n_f64(0.0);
for i=0 to rows-1 do:
for j=rowptr[i];j<rowptr[i+1];j+=2 do:
matrix = vld1q_f64(values+j);
vector = vld1q_lane_f64(x+columns[j]);
vector = vld1q_lane_f64(x+columns[j+1]);
temp_y = vmlaq_f64(temp_y, matrix, vector);
end for
y[i] += vget_lane_f64(temp_y, 0) + vget_lane_f64(temp_y, 1);
end for
ELLPACK的SpMV用NEON实现如下:
1 | //The result vector is y |
而ACSR和AELL的实现如下,需要注意x需要在末尾添加一个0元素,防止访问越界:
1 | //ACSR |
6.Performace analysis
ACSR和AELL通过加快向量加载到向量寄存器来提高效率,但是也增加了对0填充的额外计算量。因此SpMV在不同填充率下性能会有波动。本节作者分析了不同压缩格式的SpMV中NEON SIMD指令的执行延迟、缓存访问的影响以及缓存未命中情况。
6.1. SpMV performance analysis for ARMv8 architecture
下表是性能分析的一些变量:
对于SpMV计算,指令数量由稀疏矩阵中非零元素的数量决定,访问的数据量与稀疏矩阵的存储格式和右向量的访问方式有关。不同的格式下有不同的零填充,也会有不同的数据访问。因此并行程序的实际运行性能不仅与程序本身的计算规模有关,还与处理器的指令执行周期、指令的并行执行、缓存数据的利用效率、内存数据的读写次数、带宽利用率、处理器所有计算核心的利用率等有关。为了减少指令的执行周期,可以选择执行周期短的指令。另外,可以将指令分布到不同的计算核心上并行执行。这也可以提高流水线和SIMD指令的数据量。 SpMV串行操作在ARMv8处理器上的性能可以描述为
L和A是执行时间和数据访问时间。T和这两个值是正相关。而L由指令总数和处理器的指令延迟确定。对于ARMv8处理器。L为:
对于SpMV,乘法共有NNZ个,加法有NNZ-M个,运算指令数是由稀疏矩阵确定的。可以通过选择执行延迟短的指令并同时使用更多指令单元来减少计算时间。表3显示了ARMv8处理器上不同计算指令的时钟周期。指令流水线和SIMD技术可以提高多条指令的并发操作,从而导致指令执行吞吐量的提高。例如,如果向量运算单元的长度为M字节,浮点数为4字节,则一次向量运算可以计算M/4个浮点数,只需要NNZ/(M/4)次向量计算。如果数据访问受限于缓存访问和未命中访存,A为:
访问缓存和内存延迟是固定的。为了提升数据访问性能,应该减少缓存访问次数和缓存未命中率。
6.2. The execution latency of instructions
根据ARM官方文档中描述的执行延迟,可以通过分析依赖于所描述的组中的指令的操作来获得最小延迟。作者分析了基于ACSR和AELL格式以及CSR和ELL格式的SpMV之间SIMD指令延迟的差异。
主要指令的延迟在表3中。NNZ的列索引是通过LDR指令load的,而向量加载使用LD1指令完成的,而向量乘使用的是FMLA指令。此外,FMLA在表3中的括号内的3表示计算完成后3个周期就可以应用计算结果。
对于双精度SpMV,列索引需要先加载到通用寄存器,然后访存。因此必须执行LDR指令NNZ次。在CSR格式下,LD1指令需要NNZ/2次,因为128bit寄存器可以一次存入两个元素。但是对x的访问不行,因为对x的访问可能不连续。因此loadx需要NNZ次。而FLMA则需要NNZ/4次,所以可以计算L为:
而在ACSR中,对列索引和x的访问都可以通过向量一次访问两个数据,因此LACSR=19/2NNZ(1+FR)。
因为ARMv8的流水线有两个ASIMD单元,所以计算延迟是NNZ/4。
同样的,作者推导出了ELL和AELL的延迟:


由此,我们可以获得不同格式的SpMV的ASIMD指令的延迟。利用上述公式分析基于不同存储格式的SpMV运算的性能,可以得到以下命题:
FR<9/19时,ACSR的计算周期小于CSR的周期。
推导过程如下:
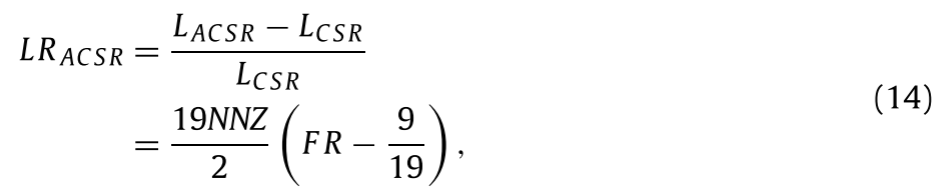
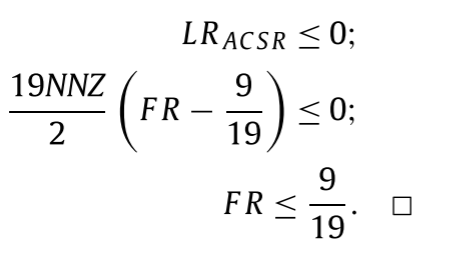
FR是0元素填充率。
Vk<14/19K时,AELL的计算周期小于ELLPACK的计算周期。
推导过程如下:
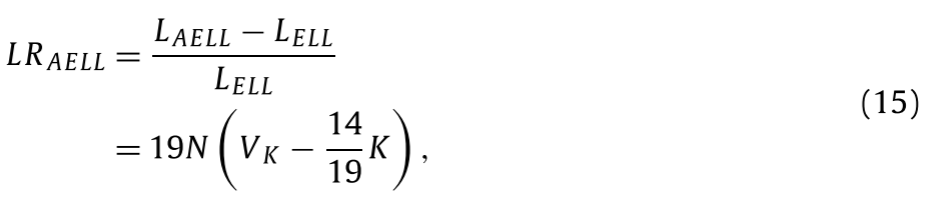
Vk是包含0填充的行的宽度(单位为向量)。
6.3 Cache access times
对于CSR和ACSR,SpMV都要访问行偏移2M次找到每行的NNZ元素。计算时NNZ以向量形式访问NNZ/2和NNZ’/2次。对col_idx的访问为NNZ和NNZ’/2次。而对于向量x的访问在CSR中NNZ次,ACSR中NNZ’/2次。而结果存入向量y需要M次。因此CSR和ACSR的缓存访问时间为:
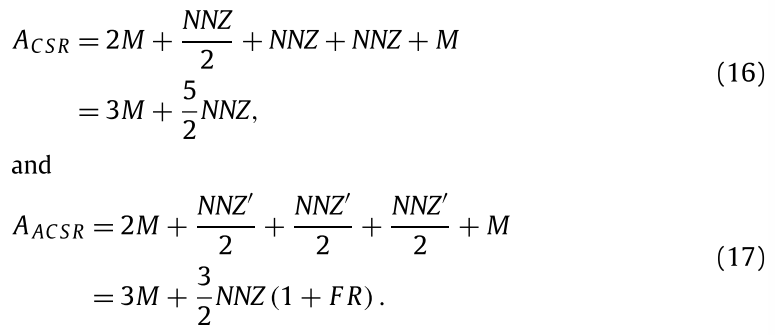
对于ELL,访问矩阵元素是按向量访问的,但是列偏移和向量x以及向量y都要顺序访问,因此ELL的缓存访问时间为:
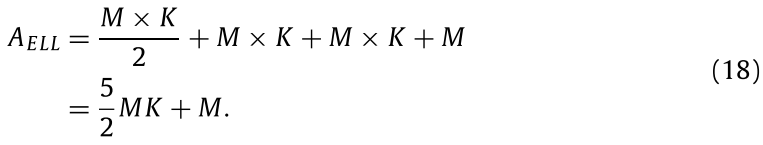
对于AELL,矩阵元素,列索引,x都可以按向量访问,因此缓存时间访问为:

类似6.2,可以计算出ACSR和AELL缓存时间比CSR和ELL的增加比例:
可以得出两个结论:
FR<2/3时,ACSR的缓存访问比CSR少
Vk<5/6K时,AELL的缓存访问比ELL少
6.4 Cache miss times
使用NEON加速的SpMV一次可以完成两个向量操作。基于CSR和ELL格式的SpMV中的非零元素需要访问缓存十次,并且包含向量形式的非零元素两次,列索引四次,向量x四次。ACSR和AELL格式需要访问缓存六次,其中values和x仅以向量形式访问两次,并且列索引只需要两个向量的起始列索引。
在每次计算中,在最坏的情况下,CSR和ELL中加载的四个x值可能分布在四个缓存行中,而ACSR和AELL中只有两个缓存行。实验是在鲲鹏920上进行的,L1缓存中有4条64B大小的缓存行。因此,在计算过程中,CSR和ELL格式可能会出现缓存行冲突,在最坏的情况下可能会被替换访问缓存6次,而ACSR和AELL格式只有4次。因此可以推断,与基于CSR和ELL的SpMV相比,ACSR和AELL格式可以降低缓存冲突的概率并导致缓存未命中的减少。
7. Experimentals
7.1 Platform
实验平台为华为的鲲鹏920。鲲鹏920支持基于ARMv8.2架构的多条并行指令,配备两个浮点单元(FPU)。如表4所示,鲲鹏920双精度浮点计算峰值性能达到665.6 Gflops。而且鲲鹏920支持8通道内存,但实验中只使用了4通道。

作者在鲲鹏920上考察了非均匀内存访问(NUMA)架构对性能的影响。如果不考虑NUMA,可能会因为操作系统进程切换而导致跨节点访问内存,从而造成更大的延迟。而且,在这种情况下,实验结果是不准确的。因此,为了在实验中获得稳定可靠的结果,作者通过NUMA工具numactl将线程和数据进行绑定,这样可以保证线程访问同一部分的内存。使用perf测试cycles,缓存缺失等指标。
所有的算法都使用openMP实现多线程,编译选项为-O2。
由于ACSR格式中每行的非零元素并不统一,并且操作系统在使用openMP自动并行时可能会调度线程来保证负载平衡,这种影响在性能评估中不容易预测。实验中,所有实验均选择性能最佳时的线程数。并且对于每个稀疏矩阵的对比实验,最终执行的线程数是相同的,这显着降低了多线程对性能评估的影响。
7.2. Experiment data
作者使用了20个SuitSparse矩阵来进行测试。
8. Experimental results
结果分为3部分。
- SpMV通过NEON加速的效果
- 实验数据的分析
- 不同格式下性能的比较
8.1 NEON acceleration for CSR and ELL
表6显示了NEON加速的效果。分别为CSR和ELL实现了19.91%和19.15%的提升。对于有些矩阵,加速效果不明显,因为对x的访问仍然是不连续的。
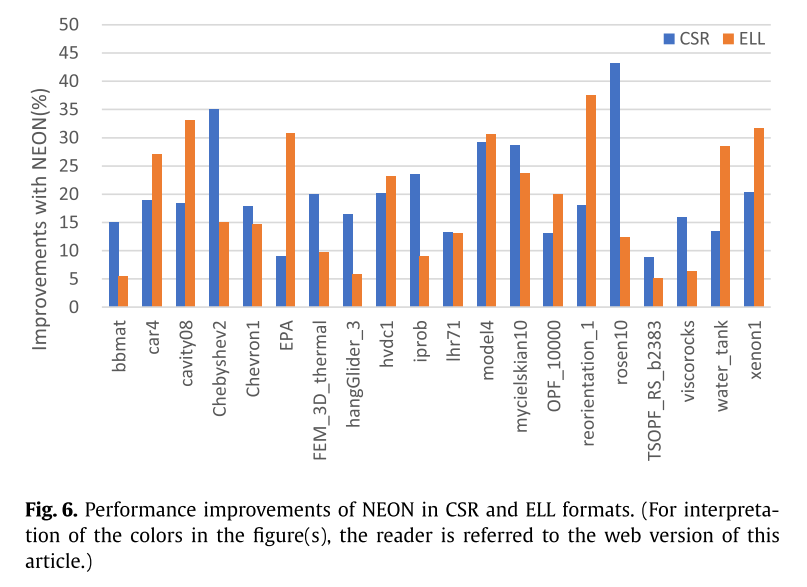
由于NEON操作指令本身的等待时间,数据量的增加可能会导致内存访问指令延迟过高,从而降低SpMV的性能。例如,ELL 中的“bbmat”和“FEM_3D_ Thermal”以及 CSR 和 ELL 中的“TSOPF_RS_b2383”。此外,基于CSR和带有NEON的ELL的SpMV可能会导致更多的缓存未命中,因为它需要额外的两次缓存访问。在进一步的实验中,基于CSR和ELL的SpMV均由NEON加速。
8.2 Analysis of experimental data
表6显示了ACSR和AELL的填充比率:

根据第6节提到的结论和表5中的比率,表7显示了真实的指令延迟改善:
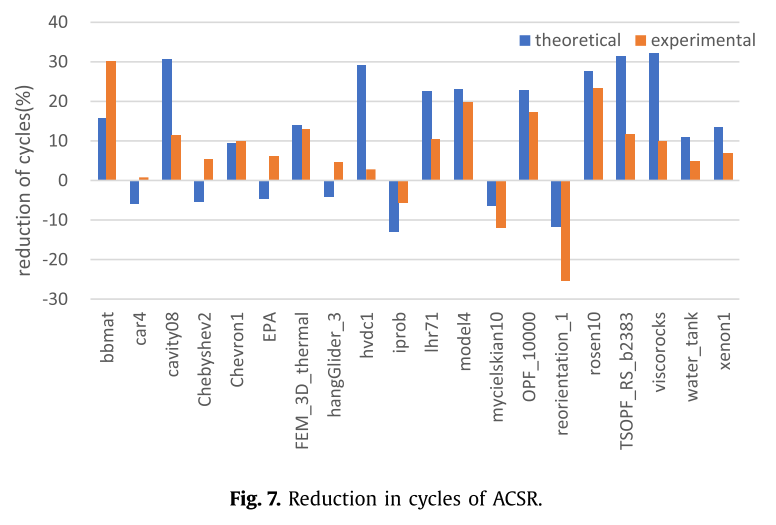
实验结果与理论分析一致。由图可见,ACSR较CSR平均可减少周期7.30%,AELL值较ELL减少21.08%。
测量结果和理论推导稍有偏差,这是因为分析时只考虑了主要的指令,实际执行时还有其他指令。==因此,实际结果表明如果ACSR的FR超过47%,就会有负提升。==并且因为OS调度线程,会带来ACSR的额外负载。
例如,“TSOPF_RS_b2383”中非零元素的分布过于分散,这可能会增加ACSR和AELL的内存访问次数。在一些CSR格式矩阵的并行SpMV计算中,主要性能取决于具有最大非零元素的长行。虽然理论上串行计算的指令时钟周期比CSR格式有所增加,但是并行计算中可能会出现与理论相反的情况,因为ACSR格式的长行的零元素填充率可能为零。例如“car4”、“Chebyshev2”、“hangGlider_3”和“EPA”。它们的非零行的平均长度与它们的长行相差数百或数千倍,而长行的零填充率几乎为零。因此,这些稀疏矩阵的实验结果与图7中的理论分析不一致。
访存的数据如图9,10,11:
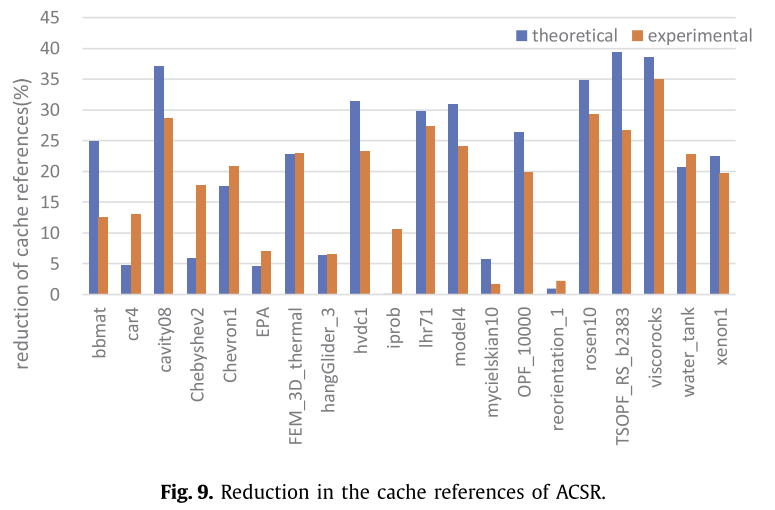
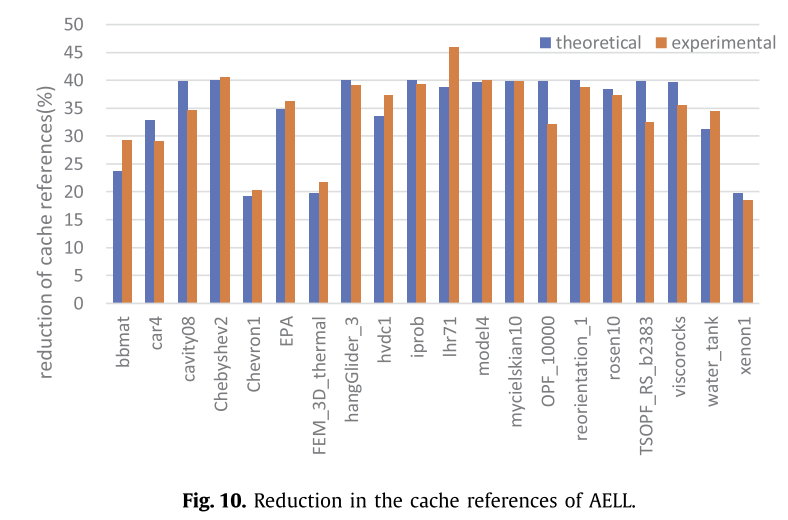
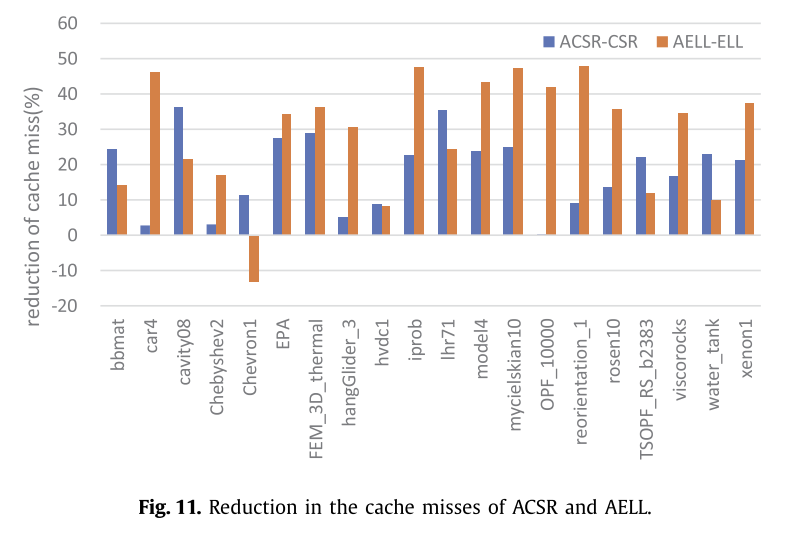
图9和图10展示了ACSR和AELL格式减少的缓存访问事件数,分别比CSR和ELL减少了18.59%和34.10%,理论值与实际值偏差为5.68%和2.91%。
虽然缓存访问对ACSR和AELL格式的影响与理论分析一致,但ACSR中少数矩阵的实验结果仍然存在较大偏差。通过分析这些矩阵中非零元素的分布,并与AELL进行比较,偏差较大的原因可能是计算过程中负载不平衡,例如“bbmat”和“TSOPF_RS_b2383”。
此外,作者发现ACSR和AELL格式可以减少单次计算中的缓存命中冲突。如图11所示,ACSR和AELL可以分别减少SpMV的缓存未命中次数28.85%和18.00%。
ACSR和AELL格式可以降低每次计算过程中发生缓存冲突的概率,因为添加的零元素和之前的非零元素通常保留在同一缓存行上。然而,由于缓存冲突,存在跨缓存行的向量。因此,当稀疏矩阵的非零元素分布相对集中时,AELL格式的零填充可能会导致额外的缓存未命中。例如,“Chevron1”是一个对角稀疏矩阵,所有非零元素都聚集在对角线上。因此,整个缓存行中的非零元素较少,因此额外的零填充会导致更多的缓存未命中。
Performance of ACSR and AELL
在这部分实验中,作者比较了使用由NEON加速的CSR和ELL的ACSR和AELL格式的SpMV的计算时间。我们发现ACSR格式在大多数情况下是最好的。图12记录了基于ACSR的SpMV与CSR格式的SpMV和PETSc相比的性能改进,并在鲲鹏920处理器上对AELL和ELL进行了比较。同时,图13显示了在FT2000+处理器上的实验结果,以验证对齐的存储格式的性能改进。
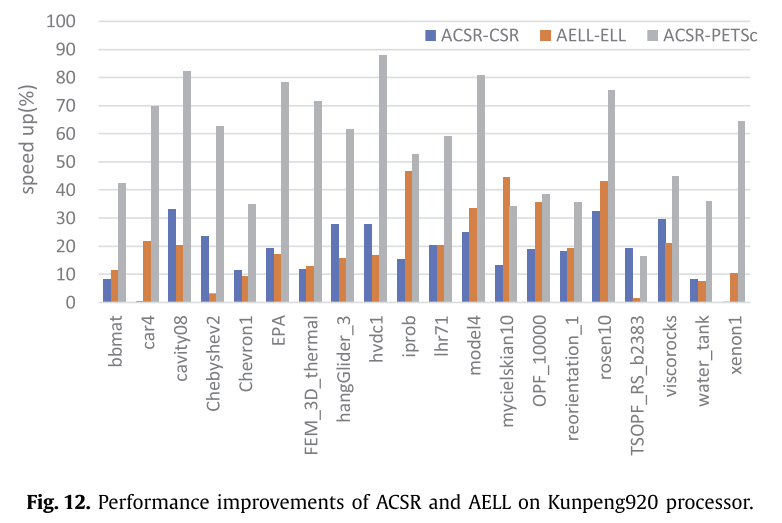
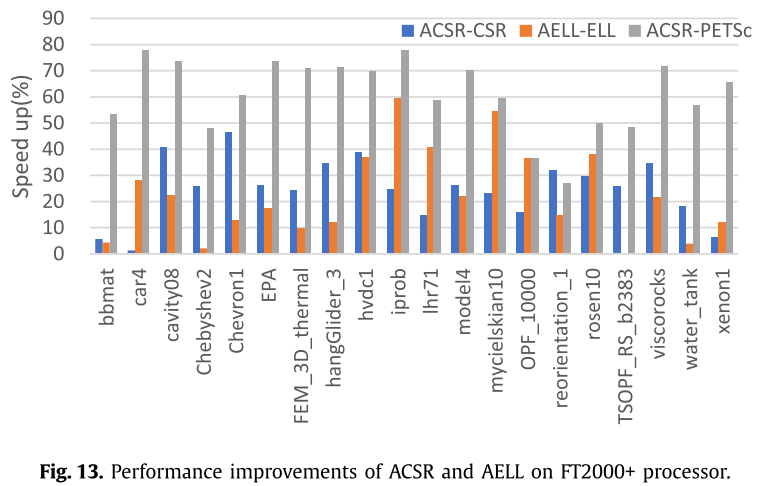
最终的实验结果与第6节的分析一致。在这个实验中,ACSR和AELL格式的SpMV比CSR和ELL格式能够获得更好的性能。与CSR和PETSc相比,ACSR可以实现平均性能提升18.17%和56.46%,AELL在鲲鹏920处理器上比ELL实现平均性能提升20.54%,而在FT2000+处理器上平均性能提升分别为24.83%、61.14%和22.55%。
而稀疏矩阵“car4”是具有局部连续性的对角矩阵,其在ACSR中的填充率达到了56.32%。基于ACSR的SpMV计算表明,与使用CSR的SpMV相比,在指令延迟、缓存访问和缓存未命中方面几乎没有任何改善。
9. Conclusions
在本文中,作者提出了两种对齐的存储格式:ACSR和AELL,它们专注于128位SIMD运算,以在ARM处理器上以双精度并行优化SpMV。作者分析了ACSR和AELL格式在指令延迟、缓存访问和缓存未命中方面的改进。并选择了PETSc进行比较,ACSR取得了56.46%的性能提升。在未来,作者可能会对更多指令类型进行考虑,考虑从缓存性能等角度进行进一步优化。