
HPC-Game-1th
主页:https://hpcgame.pku.edu.cn/
赛事组的题解:https://github.com/lcpu-club/hpcgame_1st_problems
1.流量
PCAP是一种数据包记录。本题要从PCAP数据包中破解出一个密码。
破解PCAP文件的程序为/usr/bin/quantum-cracker,只能破解全部为SSH;流量的PCAP文件作为参数。
在/lustre/shared_data/potato_kingdom_univ_trad_cluster/pcaps中,有16个pcap文件,是数据包的记录,并且进行了分块。
集群的节点上有一个wireshark-cli的软件包,提供了一些命令,包括tshark和mergecap,前者可以从PCAP文件中过滤信息,后者可以合并多个PCAP文件。
本题要求使用4个计算节点,每个节点4个tshark进程同时从16个PCAP文件中提取SSH流量,要求使用Slurm调度器运行这一步骤,将这一计算的Slurm JobID和获得的密码提交。
1 | #srun job |
2.高性能数据校验
题目提到的高性能校验算法如下:算法的流程如下(对算法的具体解释见 baseline 代码):
对数据进行分块,每一块的大小为 M=1MB,记划分的块数为 n。如果文件剩余内容不足一块的大小,则补二进制0至一个块大小。
对于第 i 个块,在其末尾连接上第 i-1 个块的 SHA512 校验码的二进制值,将所得到的 M + 64 大小的数据进行 SHA512 校验,得到第 i 个块的校验码。(i 从 0 开始,第 -1 个块的校验码为空文件的校验码)
最后一个块的校验码,即为文件的校验码
调用SHA512()计算和给出的代码中的计算是等价的。
baseline版本如下:
1 | void checksum(uint8_t *data, size_t len, uint8_t *obuf) { |
因为可以先计算块本身的数据,最后再加上上一个块的校验码,所以可以首先并行计算每个块本身的数据(第一块除外,可以直接完整计算),计算完毕后,接收上一个节点的计算结果,更新自己的每个块的校验码,再将最后一个块的校验码传给下一个节点。使用MPI的IO接口读入数据,因为最后一个测试点是16G文件,每个节点要读4G文件,超过了单词读入的size参数(32位整型),所以要分两次读入。但是这个版本只能拿到74分,正解是边读边接收上一块计算。
1 | namespace fs = std::filesystem; |
题解:
1 |
|
3.齐心协力(RAY)
ray是python实现的消息传递API,本题对于每个数据,需要4个步骤完成,因此可以构建四个worker组成的流水线,进行数据处理。
与上一题相同,本题也只拿了75分,两个题API不同,但过程是相似的,因此可能是有同样的可以优化的地方。
RAY的文档:https://docs.ray.io/en/latest/ray-core/walkthrough.html
最后还是看题解才知道做这个题对RAY的理解很多地方还是有问题。当时看文档没有仔细看。
1 | import os |
题解:
1 | #!/usr/bin/env python |
4.3D生命游戏
本题只拿了10分,直接等题解。
5.矩阵乘法
最经典的高性能计算实例,这次终于看懂goto算法了,但是在实现的过程中实际上是写了一个简化的版本,但是pack和缓存都考虑到了,所以分数还可以,150/200。
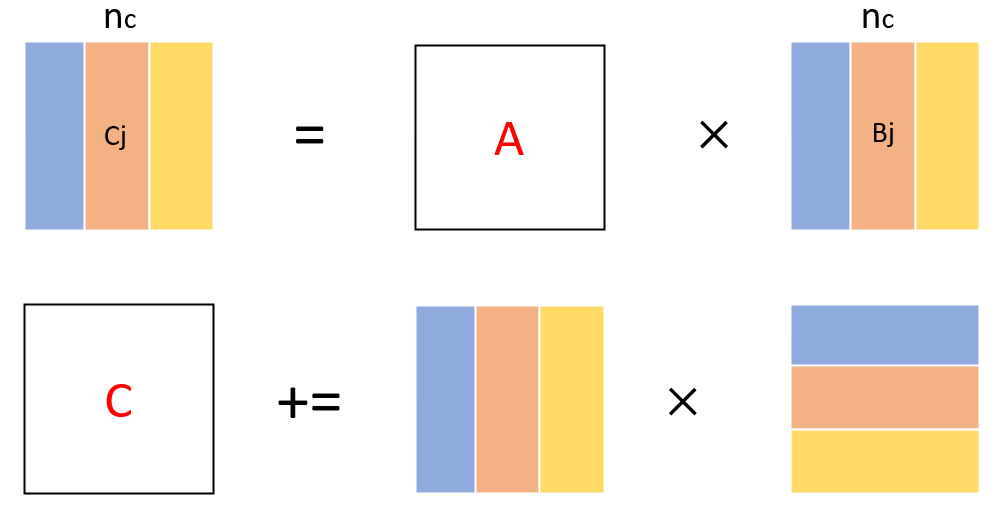
尽管用以下一张图就可以表示这个算法,真的完全理解和实现还是更复杂一些。

GOTO算法
计算记为C = A x B。
单独画了和上方不一样的图,是因为要提醒自己,每个块划分完之后是存在偏移的,数据定位是要考虑偏移的。一直到第二层循环,数据都打包好了以后,就可以将原问题转为子矩阵和子矩阵的计算了。
对于大型矩阵乘法计算,由于数据规模大,局部性会变得非常差。为了提高局部性,要对矩阵进行分块,对矩阵分块有多种分块计算方式。如果矩阵比较小,可以直接将矩阵C横向和纵向都进行划分,分为小块进行计算,也就是6重循环的计算方法,但是如果矩阵规模大,这种方式就会因为没有很好的利用到局部性而性能快速下降。所以对于大规模的矩阵,要一步一步划分,考虑每个划分后的子矩阵的计算方式,来最大化局部性。在goto算法中,主要利用到的是以下这两种划分方式,一个是按列,一个是分层。
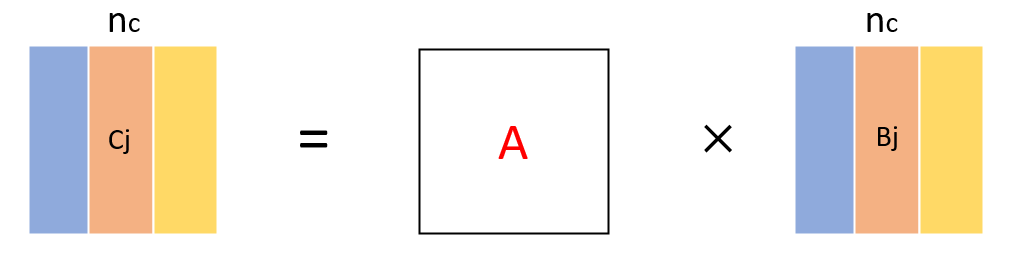
首先通过按列划分,减少矩阵计算的规模,每次计算Cj,Cj包含nc列,Cj的起始列号假设为js,此后访问Cj和Bj的数据都要注意加上js这个偏移量。此时C(i,j)为C[ldc*i + j + js],矩阵按行存储。
而对于Cj的计算,按照分层的方式进行划分:
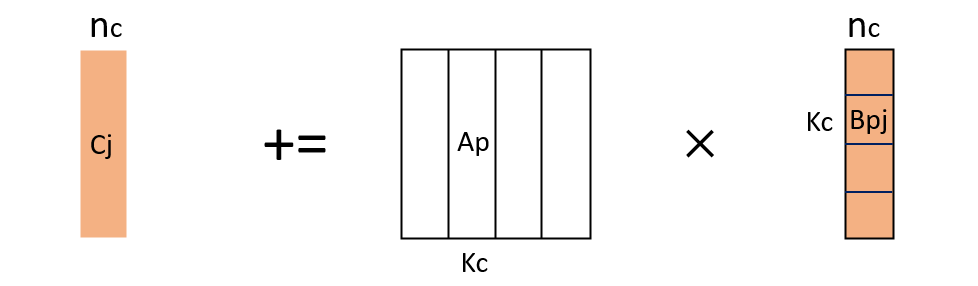
此时的Bpj已经经过两次划分,可以对其进行打包,至于打包的格式,取决于最核心kernel对其的计算方式,这里可以先不看。打包的目的是为了加快计算和提升局部性,接下来还要对Cj进行划分,这次按照行进行划分,子矩阵的计算就变成了Aip和Bpj的计算,Bpj会在计算Cij时反复使用,因此可以考虑将其大小与L3Cache适配。这里打包时,假设起始行号为as,将as行起的kc行打包到单独的一块内存。
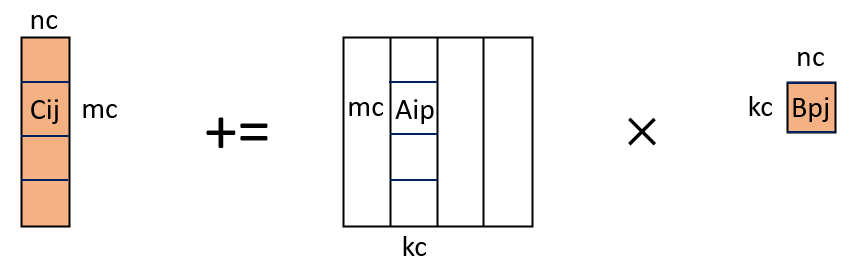
到了这里,计算已经划分为Cij += Aip × Bpj,可以将其作为一个macro kernel封装了。而A也已经划分为一个块,可以将其打包,以便于计算和放入缓存,此时L3已经存入Bpj,Aip作为更小的块,将其适配L2缓存。而对于每一个Cij,在内部再进行划分,此时Aip和Bpj都是打包后的了,可以不考虑原矩阵中的位置而访问数据,只有C的数据访问还需要在原矩阵中定位。Cij内部的划分和上述过程是一样的,先按列划分,再按行划分,最后计算子矩阵块,这时就可以直接搬出这个图了:
按照最终的计算顺序,对A和B进行相应的打包来加快计算。在我的实现中,最内层的kernel不是分层划分计算的,而是按照常规的矩阵乘法应用AVX计算的。
实现
这里假定大小是可以对齐,多加上长度的控制,就可以对通用大小进行计算了。此外,macro_kernel也不是严格按照上述算法分解的,但是原理是一致的,划分大小也是按照packB在L3缓存,packA在K2缓存,最小计算在L1和向量寄存器中完成而设定的。
gemm的整体实现如下,为了多线程并行计算,准备线程数个packA的打包缓冲区,在第三层循环这里进行多线程并行计算,注意macro_kernel传入的packA地址是当前线程对应的packA地址。
1 | const uint64_t gemm_nc = 4096; |
packB:
1 | //将Bpj按照nr列一组,组内行优先放入packB |
packA:
1 | void packAip(double *oa, size_t lda, size_t offset_a, double *na, int tid){ |
macro_kernel:
1 | void macro_kernel(double *c, size_t ldc, size_t offset_c, double *a, double *b){ |
6.LOGISTIC方程
AVX512+OPENMP。一开始就直接尽量填充了流水线,如果没有这么做,可能拿不满分数。见代码。
7.H66
用Vtune可以找到热点代码是spmv,原始计算是使用COO格式完成的,可以转为CSR,然后使用AVX和OPENMP计算,只拿到了部分分数,因为时间问题,没有尝试其他压缩格式。等题解。
以下是CSR的SPMV计算过程:
1 | //out=m*v; |
8.光之游戏
未完成,等题解。
9.洪水困兽
OPENMP题,对其中一部分数据要原子更新,并行化就可以拿到满分。


