
MPI
MPI内容主要来自https://mpitutorial.com/tutorials/。由于MPI tutorial的内容比较基础,缺少了常用的非阻塞通信,并行文件读写,因此补充了《高性能计算-MPI并行编程技术》(都志辉编著)中的一些内容。
1 MPI介绍
MPI在设计上有一些经典概念。
通讯器定义了一组能够互发消息的进程,每个进程有一个序号,称为秩(rank),并通过指定rank通信。
一个进程可以通过指定另一个进程的rank和一个消息tag来发送消息,接收者可以指定tag进行接收(或不管tag,接收任何消息),这样的发送接收过程为点对点通信。很多情况下,需要广播通信,MPI提供了专门的接口处理这类集体性通信。
MPI的HelloWorld程序如下:
1 |
|
MPI_init时会创建MPI的相关变量,通讯器会根据所有可用进程被创建出来(通过mpi参数指定进程数)。一般来说MPI_Init的参数是没有用的,只是保留待用。
编译使用了MPI的程序需要使用mpicc,mpicc只是对gcc做了一层封装。编译好的程序通过mpirun运行,mpirun提供了-n参数指定进程数,-f可以指定hostfile文件,如果要在多个节点的集群跑MPI程序,hostfile中需要包含所有节点的名称,还可以指定节点的进程数。
2阻塞通信
2.1 Send&Recv
如果A进程要发送消息给B进程,A进程会把需要发送给N的数据打包好,放入一个缓存,如果B进程确认想要收到A的数据,数据就传输成功了,并且消息可以使用tag进行区分。
MPI发送和接收方法的定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15MPI_Send(
void* data,
int count,
MPI_Datatype datatype,
int destination,
int tag,
MPI_Comm communicator);
MPI_Recv(
void* data,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm communicator,
MPI_Status* status);
MPI_Send会发送count数量个元素,MPI_Recv最多接收count个元素,而MPI_Recv的最后一个参数提供接收的信息状态。MPI的数据结构与基础数据结构是对应的:
| MPI datatype | C |
|---|---|
| MPI_SHORT | short int |
| MPI_INT | int |
| MPI_LONG | long int |
| MPI_LONG_LONG | long long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_UNSIGNED_LONG_LONG | unsigned long long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | char |
以下是一个最简单的例子,MPI_Comm_rank获取当前进程的rank,而MPI_Comm_size获取当前通讯器空间的大小。
1 | // 得到当前进程的 rank 以及整个 communicator 的大小 |
2.2 动态消息
上述介绍了MPI发送事先知道消息长度的消息,MPI本身可以通过额外的函数调用支持动态消息。
MPI_Recv将MPI_Status结构体的地址作为参数(可以使用MPI_STATUS_IGNORE忽略)。操作完成后,该结构体会填充有关接收操作的其他信息。三个主要的信息包括:
- 发送端的rank,通过stat.MPI_SOURCE访问。
- 消息的标签:MPI_TAG。
- 消息的长度:在结构体中没有预定义的函数,需要使用MPI_Get_count找出消息的长度。
1 | MPI_Get_count( |
MPI_Recv会提供一个很大的缓冲区来为可能的传输大小处理,而MPI_probe可以在实际接收消息前先查询消息大小:
1 | MPI_Probe( |
MPI_probe除了不接受消息以外,和MPI_Recv是一样的。也同样会阻塞具有匹配消息和发送rank的消息,消息可用时,会填充status结构体。然后可以使用MPI_Recv接收实际的消息。以下是动态接收消息的示例:
1 | int number_amount; |
MPI_Probe是许多动态MPI应用程序的基础,例如控制端和子程序在交换变量大小的消息时会大量使用MPI_Probe。
2.3 其他通信模式
上述的MPI_Send是标准通讯模式,MPI实际提供了四种通讯模式:
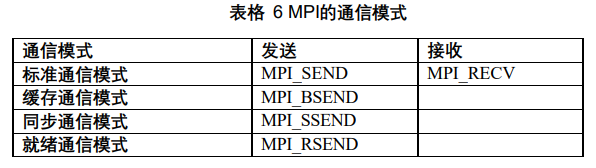
其他通讯模式是没有相应的接收函数的。这些模式与标准通讯模式的区别在于是否对发送数据缓冲,发送数据缓冲什么时候可以重用。详情见书。
3 集合通信
collective通信隐含着所有的进程都必须到达一个同步点后才能继续执行。
MPI的barrier函数如下,用于实现进程之间的同步。
1 | MPI_Barrier(MPI_Comm communicator) |
组通信又可以根据通信方向分为一对多,多对一,多对多。广播是常见的一对多通信,而收集是最常见的多对一通信。
3.1 MPI_BCAST
MPI_BCAST用于将消息广播到其他的进程,广播和接收消息的进程的count等参数需要保持一致,并且广播和接收都是使用这一个函数来进行的。
1 | MPI_Bcast( |
3.2 Gather & Scatter
MPI_Gather用于一个进程从其他进程收集数据。只有接收进程需要一个有效的接收缓存,所有其他调用进程只需要传NULL,recvcount是接收到的每个进程发来的数据数量
1 | int MPI_Gather( |
MPI_SCATTER则用于一个进程向其他进程发送数据,与BCAST的区别是发送的是数据的各个部分给不同的进程。
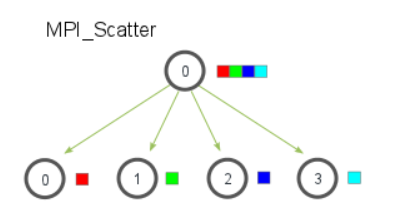
其原型如下:
1 | MPI_Scatter( |
send_data是所有数据的数组,而每个进程将接收到原数组连续的send_count个数据。
在使用Scatter和Gather时,发送进程需要开辟完整的数据空间,每个进程开辟一块独立的数据空间。以下是使用Gather和Scatter计算平均数的一段示例代码:
1 | if (world_rank == 0) { |
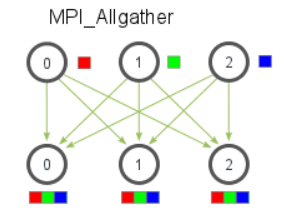
ALL Gather类似与Gather,作用是将数据收集到每个进程上,如下图示:
1 | MPI_Allgather( |
3.2 MPI_Reduce
MPI_Reduce在每个进程上获取一个输入元素数组,将输出元素数组返回给root进程,输出元素包含reduce的结果。原型如下:1
2
3
4
5
6
7
8MPI_Reduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm communicator)
send_data是每个进程处理的数据,recv_data则存放规约结果,大小为sizeof(datatype)*count,op对应的规约操作有:
- MPI_MAX/MIN/SUM
- MPI_PROD(所有元素相乘)
- MPI_LAND/LOR/BAND/BOR(所有元素与/或/按位与/按位或)
- MPI_MAXLOC/MINLOC(返回最小值/最大值所在进程的rank)
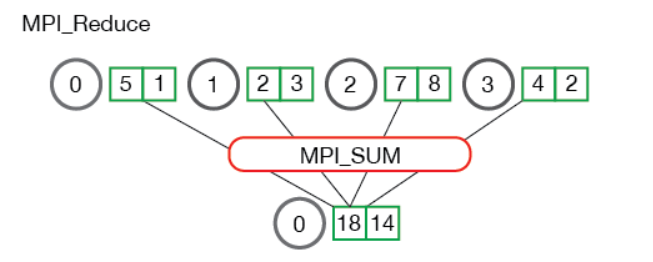
当多个元素reduce时,需要注意是对应的元素进行reduce,而不是所有元素reduce。如下图:
以下是使用reduce计算平均值的示例:
1 | rand_nums = create_rand_nums(num_elements_per_proc); |
类似ALLgather,reduce也有一个对应的ALLreduce函数,能将数据规约到每一个进程上:
1 | MPI_Allreduce( |
4 组和通讯器
对于简单的程序,使用MPI_COMM_WORLD作为通讯器就够了,因为进程通常只与另外一个进程对话,或是和其他所有进程对话。当程序规模变大,需要只与进程组的子集对话,就需要使用新的通讯器。
4.1 通讯器
当需要创建新的通讯器时,以下是一个最常见的函数:
1 | MPI_Comm_split( |
comm为原始的通讯器,调用该函数会在不影响原始通讯器的情况下创建新的通讯器newcomm。color参数确定进程属于哪个通讯器,color值相同的进程会分配给同一通讯器,若color为MPI_UNDEFINED,则该进程不在新通讯器当中。key则确定进程在新通讯器中的rank,按照key从小到大分配rank。
以下示例将通讯器拆分为一组通讯器:
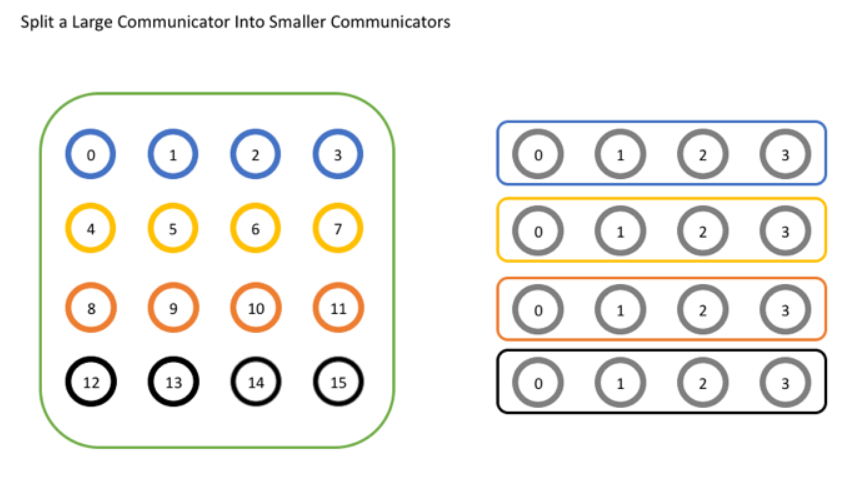
1 | int world_rank, world_size; |
以上代码将原通讯器按行拆分,并使用原始秩作为key,这样进程在新通讯器中和在原来通讯器中的顺序是一致的。最后,使用MPI_Comm_free释放通讯器,这是有必要的,因为MPI可以创建的对象数量是有限的。
除了MPI_Comm_split,还有其他用于创建通讯器的函数。MPI_Comm_dup的作用是创建通讯器的副本,常常用于使用库执行特殊函数的应用,用来保证用户代码和库代码不互相干扰,因此每个程序都首先创建一个MPI_COMM_WORLD的副本,避免其他使用MPI_COMM_WORLD的库的问题。
4.2 组
组MPI_Group是MPI中的另外一种对象。通讯器是通讯的上下文及该通讯器包含的一组进程,而组是通讯器中所有进程的集合。
组可以进行集合理论中的各种操作,例如交,并等。
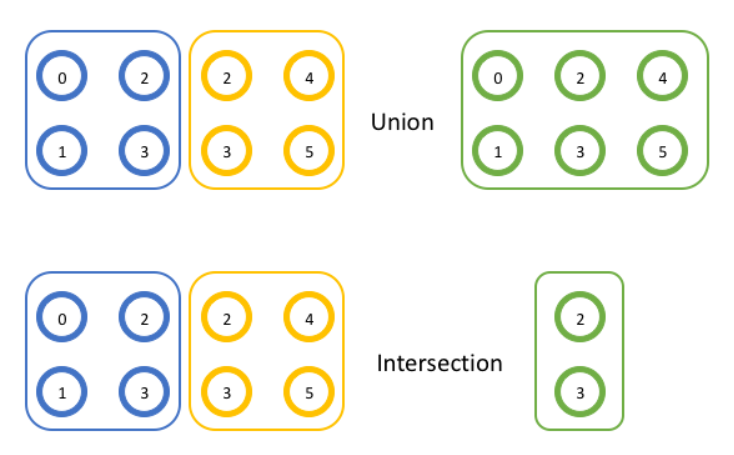
在MPI中,提供API获取通讯器的进程组:
1 | MPI_Comm_group( |
组可以获取rank和size,但不能通讯,因为没有上下文,但由于组不用于通信,可以在本地进行各种操作,例如交、并:
1 | MPI_Group_union( |
MPI还支持组的减,排除特定rank等操作。组可以用于创建通讯器:
1 | MPI_Comm_create_group( |
5 非阻塞通信
非阻塞通信主要用于实现计算与通信的重叠。
阻塞通信中,阻塞发送后该缓冲区可以被更新,而接收操作后数据已经完整,可以正确使用。且对于接收进程,接收消息是按照顺序接收的,无论消息到达的顺序先后。
由于通信经常需要一段时间,通信没有结束时,只能等待,非阻塞通信可以实现计算和通信的重叠,提高执行效率。非阻塞通信不必等待通信操作完成就可以返回,将通信交给特定硬件完成,和异步I/O的思想是一致的。在非阻塞通信中,发送缓冲区必须等待发送完成后释放,而接收消息必须等到消息到达后才可以引用。
非阻塞通信和通信模式结合,有四种形式,而MPI还引入了在循环中使用的重复非阻塞通信,因此通信模式有:
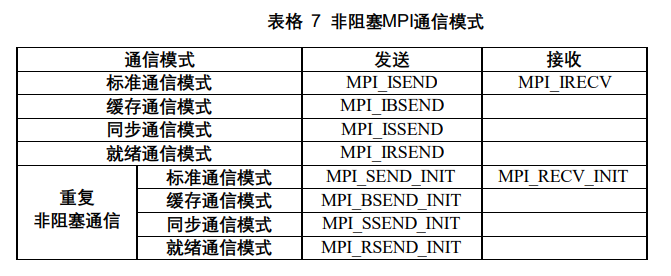
此外,MPI还提供了多种非阻塞通信的完成方法和完成检测方法。
5.1 ISEND&IRECV
MPI_ISEND启动一个非阻塞发送,调用后立即返回,比SEND多了一个参数request,request是一个非阻塞通信对象,通过对其的查询可以知道非阻塞发送是否完成。而IRECV则是启动一个非阻塞接收,与ISEND类似。
1 | MPI_Isend( |
5.2 WAIT&TEST
MPI提供了两个调用MPI_WAIT和MPI_TEST来检查发送和接收是否完成。
MPI_WAIT以非阻塞通信对象为参数,等到通信完成后才返回,同时释放该对象,这样就不用手动释放非阻塞通信对象。而MPI_TEST只检查非阻塞通信是否完成,设置完成标志,不释放相应的非阻塞通信对象。如果不使用wait释放request,就要手动释放request,如果对应通信没有完成,request不会被释放,而是会等到通信结束,因此使用request_free释放request不影响通信的完成。
1 | MPI_Wait(MPI_Request *request, MPI_Status *status); |
MPI还提供了一次完成多个已经启动的非阻塞通信调用的接口,MPI_WAITANY,MPI_WAIT_ALL,MPI_WAIT_SOME,这里不一一介绍了。
6 并行I/O
6.1 概述
MPI根据读写定位方法的不同,提供了三种并行I/O:
- 指定显式的偏移:没有文件指针的概念,每次读写指定读写位置。
- 各进程拥有独立文件指针:不需要指定读写位置,读写完成后自动移动到下一个数据位置,每个进程有一个视口,视口数据是文件连续或不连续的一部分。
- 共享文件指针:每个进程对文件的操作都从当前共享文件指针开始,且指针移动对所有进程可见。
根据同步机制的不同,对文件的操作可以是阻塞的或非阻塞的。而非阻塞又分为单步和两步,单步中MPI只提供文件读写的开始操作,通过类似MPI_WAIT的方式完成;而两步则提供读写的开始和完成操作两步。只有对组读写才可以使用两步。
在MPI2中,对于非阻塞的组读写,只有两步法,这样将读写明显分开,可以提供给MPI更多的优化机会。
在文件的组调用时,调用使用的进程组就是打开文件时指定的通信域进程组。
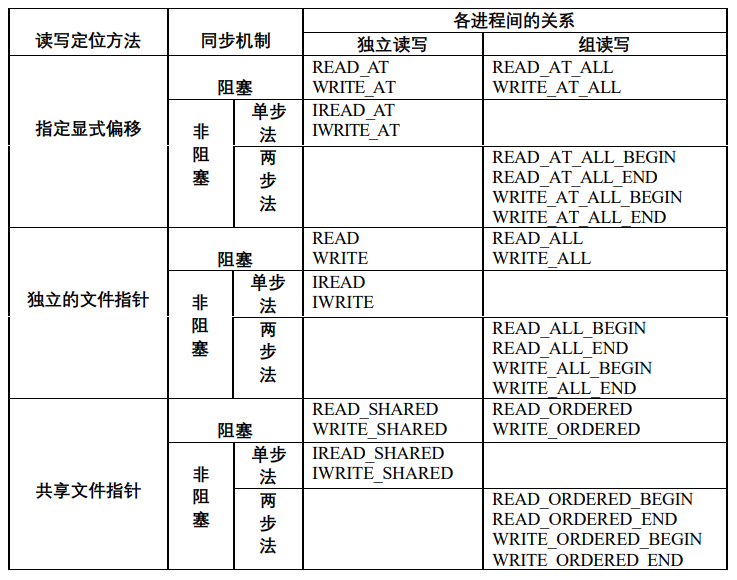
6.2 并行文件基本操作
并行的文件打开,关闭,删除等接口如下:
1 | int MPI_File_open( |
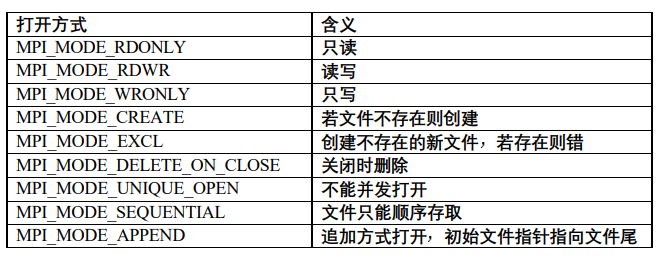
文件的打开方式有以下九种之一:
6.3 显式偏移的并行文件读写
在文件读写时需要注意大小,所有文件读写的数量参数count都是int型,当读取G级别的数据时,就要考虑是否超出了int表示范围(<2G)。
阻塞方式
1 | int MPI_File_read_at( |
read_at_all是一个组调用,要求所有进程调用时都使用相同的偏移量和读取参数,所有进程读取相同位置的数据。
非阻塞方式
类似于非阻塞通信,非阻塞并行读写为IREAD/IWRITE,并有一个request参数,用于检查非阻塞读写是否完成。检查是否完成同样是MPI_WAIT和MPI_TEST函数。
1 | int MPI_File_iread_at( |
此外,还有应用于组的两步非阻塞调用形式,明确将读写分为两步完成,详情见书。
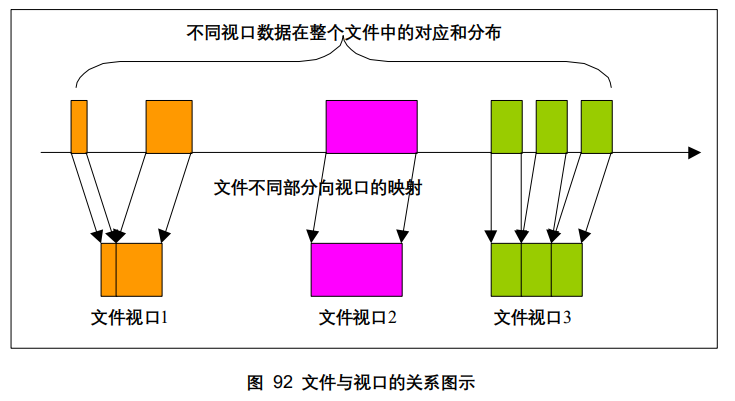
6.4 多视口并行文件读写
多视口并行文件读写中,每个进程都有自己的文件指针,可以看到一个视口内的文件数据。
其他内容待后续需要使用时补充。
6.5 共享文件读写
待后续需要使用时补充。


