Merge-based Sparse Matrix-Vector Multiplication (SpMV) using the CSR Storage Format
Merge-based Sparse Matrix-Vector Multiplication (SpMV) using the CSR Storage Format
这是一篇来自PPoPP的2016年的文章。本篇文章是考虑提高负载均衡程度从而提高并行化效率来提高SpMV性能。不需要改变格式,而是直接对CSR的SpMV过程进行更改,从而实现平衡的工作负载分配。
Abstract
作者提出了一个非常均衡的基于合并的并行SpMV。算法是对CSR格式的稀疏矩阵进行运算。作者的算法对输入数据集进行公平的分区,确保单个线程不会因分配给任意长的行或大量0长度的行而负载不均衡。这种并行分解不需要预处理,也不需要辅助数据格式。作者在CPU和GPU都评估了该方法,传统的SpMV表现不一致,而作者的方法在性能上基本不受行长度的影响。
1 Introduction
并行 SpMV 性能的主要设计问题是 (1) 统一处理器利用率和 (2) 内存带宽的有效利用 [4]。实现这些目标需要并行分解和矩阵存储格式化的补充策略,并且仍然是一个活跃的研究领域。
通过创新的矩阵格式化来提高 SpMV 性能需要付出巨大的实际成本。应用程序主要依赖通用压缩稀疏行 (CSR) 格式进行内存中表示。因此,需要替代格式的 SpMV 实现最终会给应用程序带来 (1) 格式转换的处理时间和 (2) 重复的矩阵存储空间的负担(因为原始 CSR 矩阵可能是其他例程需要的并且不能被丢弃)。相比之下,作者的“基于合并”的 CsrMV 并行化方法无需格式转换或增强即可提供高性能。
尽管 CSR 格式可以通过各个线程之间的行分配来进行直接的 SpMV 并行化,以实现私有化的行缩减,但当代并行 CsrMV 实现会因不规则的行长度和/或宽纵横比而导致数据相关的性能下降。或者,可以采用“非零分割”策略,其中为并行处理器分配非零数据的正则化部分(即,值和column_indices数组)。当每个处理器消耗其非零部分时,它必须通过 row_offsets 数组跟踪其进度。不平衡仍然是可能的,因为某些处理器可能比其他处理器消耗任意更多的行偏移量。已经开发了许多启发式方法来改善这些问题。威廉姆斯等人。调查了多核 CPU 的各种优化技术 [5],Filippone 等人。调查了 60 多个 GPU 特定的变体 [2]。
然而,这两种总体策略都没有被证明是万能的。 (1) 更宽的并行处理器越来越容易受到未充分利用的影响,(2) 无标度数据集,其中少数行比其他行长多个数量级,以及 (3) 数据集具有大量与有向图中的“叶”顶点相对应的零长度行。对于 CPU 和 GPU 微架构,这些 CsrMV 策略在类似大小的矩阵中通常会出现一个或多个数量级的性能缺陷。
为了完全消除工作负载不平衡,作者的方法采用细粒度的 MergePath 分解 [3] 来合并两个排序列表,从而允许其实现分配相等的SpMV份额。结果是均匀地利用并行处理元件来提供可预测的良好性能,而不管行不规则性和倾斜如何。
作者方法的中心思想是将并行 CsrMV 分解构建为两个列表的逻辑合并:
- 行描述符(例如,CSR 行偏移)
- 自然数(例如,CSR 非零值的索引)。
作者使用整个佛罗里达大学稀疏矩阵集合(目前有 4,201 个重要数据集)进行评估。该实验语料库涵盖了广泛的稀疏模式,从结构良好的矩阵(典型的离散几何流形)到幂律矩阵(典型的网络图)。对于共享内存 CPU 和 GPU 架构,作者展示了 MKL 和 cuSPARSE CsrMV 在类似大小的矩阵中通常表现出一个或多个数量级的性能差异。作者的方法的实验结果中,性能与不规则行长度基本上不相关,而与问题大小高度相关,通常匹配或超过 MKL 和 cuSPARSE 的性能,对于中型和大型数据集分别实现 1.6 倍和 1.1 倍的平均加速,对于高度不规则的数据集高达 198 倍。作者的方法在特殊格式(CSB [15]、HYB [7])方面也表现良好,即使是那些利用昂贵的每处理器和永久矩阵自动调整的格式(pOSKI [16]、yaSpMV [17])。
2 Background
2.1 通用稀疏矩阵格式
COO是最简单的稀疏矩阵表示格式,能提供工作负载平衡,但通常无法实现高水平性能,因为存储开销较高。CSR格式则是最常见的通用格式。
2.2 专用稀疏矩阵格式
有许多专用于SpMV的格式,通过0填充或重组织规范计算和内存访问。
重组策略尝试将类似大小的行映射到共同调度的线程组上。 Bell 和 Garland 研究了一种分组 (PKT) 格式,该格式对矩阵进行分区,然后以平衡线程间工作的方式布置每个部分的条目 [21]。阿沙里等人。建议按长度对行进行分箱,以便可以一起处理长度相似的行[9]。 Sliced ELL 格式 [22] 可以提供类似的好处,因为它也按长度对行进行装箱。尽管这些启发式方法改善了许多场景的平衡,但它们的粗糙度仍然会导致处理器利用率不足。
许多专用格式还旨在通过索引压缩来减少内存 I/O。分块是上述存储格式的常见扩展,其中仅使用单个索引来定位小而密集的矩阵条目块。 (基于合并的 CsrMV 与阻塞兼容,因为 CSR 结构以相同的方式使用来引用稀疏块而不是单个稀疏非零。)其他复杂的压缩方案尝试优化矩阵的位编码,但通常会付出代价大量的格式化开销[23],[24]。 yaSpMV BCCOO 格式是块压缩 COO 的一种变体,它使用位标志来存储与列索引一致的行索引 [17]。
混合和多层次的格式也很常见。矩阵可以划分为单独的区域,每个区域可以以不同的格式存储。 pOSKI 自动调整框架探索了广泛的多级阻塞方案 [16]。压缩稀疏块 (CSB) 格式是一种嵌套的 COO-of-COO 表示形式,其中两个级别的元组都保存在 Morton Z 顺序中 [15]。 HYB 格式结合了 ELL 部分和 COO 部分 [7]。苏等人。演示了一个基于 Cocktail 格式的自动调整框架,该框架将探索任意杂交 [25]。对于扩展阅读,威廉姆斯等人。探索多核 CPU 的一系列技术 [5]、[26] 和 Filippone 等人。对 GPU 的 SpMV 方法进行了全面的调查 [6]。
2.3 现有CSR SpMV的并行化策略
整体来说,并行化有两种策略:行分割;按非零元素数进行划分。
行分割
这种方法将行进行分割分配给处理器,部分和在最后通过聚合得到结果。小于分割尺寸的行长还是会带来负载不均衡。分割可以静态完成,也可以动态完成。动态分割需要运行时分配,可能会导致处理器争用,并在大规模并行系统上可扩展性有限。
向量化是行分割的常见变体。分配线程处理每一行。向量化是基于GPU的典型实现。当行长度与SIMD宽度不对齐时,SIMD通道可能严重未充分利用。Greathouse 和 Daga [8] 以及 Ashari 等人的最新工作[9]基于行长度自适应向量化,从而避免了向量化CSR内核在短行上表现不佳的问题。然而,这些方法需要额外的存储和预处理时间,以使用捕获线程分配的补充数据结构来扩充 CSR 矩阵。
非零元素分割
基于行的并行化的替代方法是分配相等份额的非零数据。处理器通过在行偏移数组中搜索来确定其数据项属于哪些行。当每个处理器消耗其非零部分时,它必须通过行偏移数组跟踪其进度。 Dalton 等人的 CsrMV 并行化。 [27]和Baxter [28]将这种搜索作为离线预处理步骤来执行,将处理器特定的路点存储在补充数据结构中。 (尽管它们的命名法不同,但这些实现并不是基于合并的,而是非零分割的示例。)
如图 2b 所示,不平衡仍然是可能的,因为在存在空行的情况下,某些处理器可能比其他处理器消耗任意更多的行偏移。尽管这种超稀疏[29]矩阵在数值代数中相当罕见(非奇异方阵必须nnz ≥ n),但它们在图计算中经常出现。

2.4 CsrMV 工作负载不平衡的说明
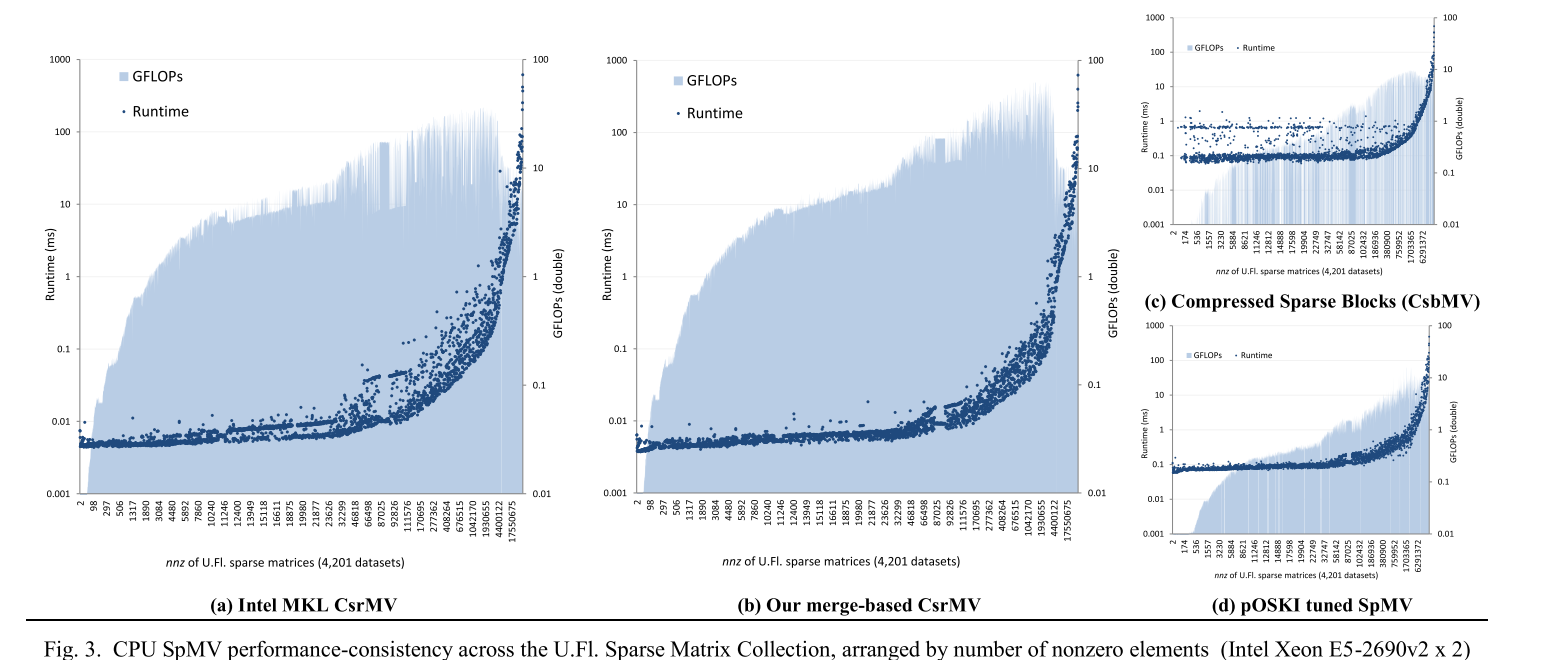
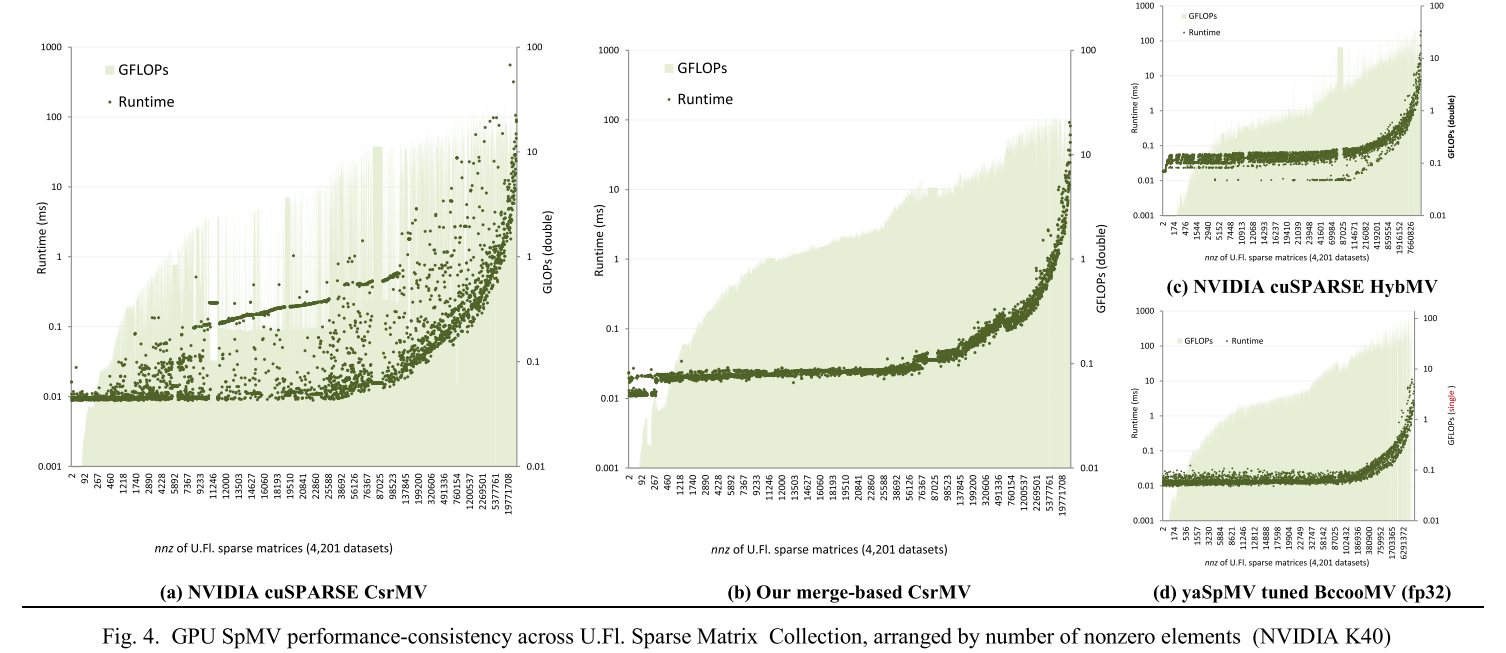
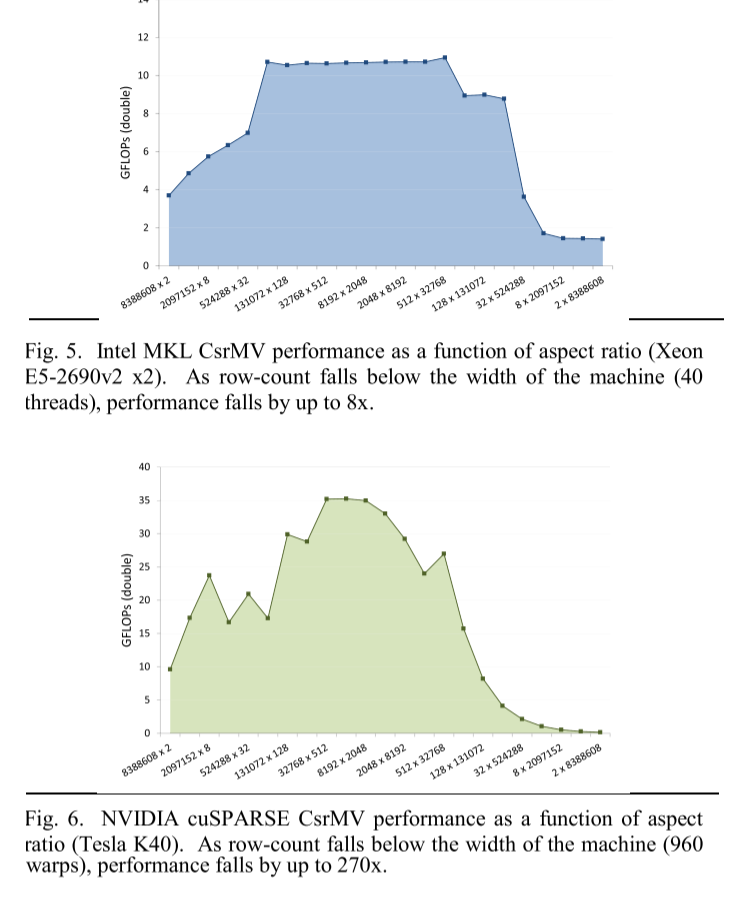
图 3a 和图 4a 说明了不规则稀疏结构的未充分利用,展示了整个佛罗里达稀疏矩阵集合中的 MKL 和 cuSPARSE CsrMV 经过的运行时间性能。理想情况下,我们会观察到与数据集大小 (nnz) 高度相关的平滑、连续的性能响应。然而,许多性能异常值是显而易见的(尽管是在对数刻度上绘制的),通常比类似大小的数据集慢一两个数量级。这在 GPU 上尤其明显,其中并行效率尤其受到工作负载不平衡的阻碍。
此外,图 5 和图 6 突出显示了基于行的 CsrMV 在计算具有多列和少量行的短而宽的矩阵时常见的性能悬崖。我们使用 MKL 和 cuSPARSE 来计算稠密矩阵(以稀疏 CSR 格式存储)的不同纵横比的 CsrMV,所有矩阵都包含相同数量的非零值。当行数低于可用硬件线程上下文的数量时,性能会严重下降。尽管 CSR 格式是通用的,但这些实现通过纵横比来区分短、宽稀疏矩阵的整个类型。
3 Merge-based CSRMV
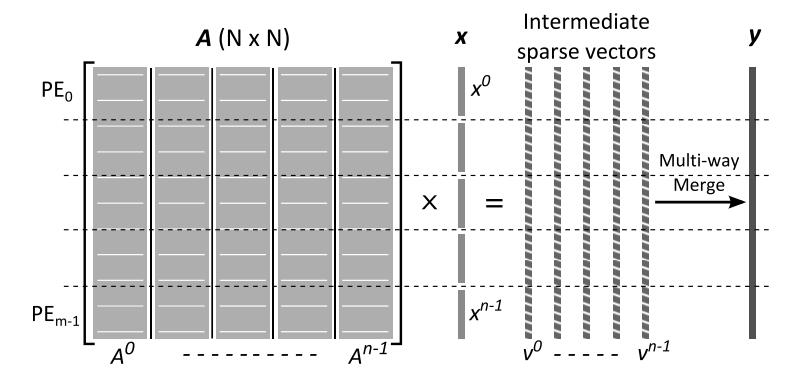
CSRMV分解类似于用于有效合并两个排序列表A和B的细粒度合并路径方法,该方法的基本属性是为处理器提供等份额的|A|+|B|步骤。
3.1 并行路径合并
此处描述的并行路径合并可视为对有序的A+B进行合并的选择路径,每次从A或B选择一个元素。图7显示了二维网格,x轴表示A的元素,y轴表示B的元素。决策路径从左上角开始,到右下角结束。当按顺序跟踪时,合并路径在消耗来自 A 的元素时向右移动,而在消耗来自 B 的元素时向下移动。因此,路径坐标描述了跨两个输入序列的元素比较和消耗的完整时间表。此外,每个路径坐标可以通过其网格对角线线性索引,其中对角线从左上角到右下角枚举。按照惯例,在比较相同值的项目时,合并的语义总是优先选择 A 中的项目而不是 B 中的项目。这导致了唯一一条决策路径。

为了跨 p 个线程并行化,网格被对角地切成 p 个宽度相等的条带,每个线程的工作是通过其条带建立决策路径的路线。使用算法 3 中提出的二维搜索过程可以独立找到任何给定的路径坐标 (i,j)。更具体地说,可以通过以下方式找到计划在对角线 k 处进行比较的两个元素 Ai 和 Bj沿对角线进行约束二分搜索:找到第一个 (i,j),其中 Ai 大于 Bj 之前消耗的所有项目,假设 i+j=k。每个线程只需要搜索其条带中的第一个对角线;其路径段的其余部分可以通过从该起始坐标开始的顺序比较来简单地建立。

3.2 应用于CSR SpMV
如图8,将行偏移与值索引和列索引向量逻辑合并,可以通过合并路径分解来计算CSRMV。这一合并不是物理进行的,只用于实现CSR的公平分配。根据设计,决策路径的每个连续垂直部分都对应 CSR 稀疏矩阵中的一行非零。当线程沿着合并路径向下移动时,它们会累积矩阵-向量点积。向右移动时,线程会将这些累积值刷新到 y 中相应的行输出端,并重置累加器。无论矩阵结构如何,总是将等量的 CsrMV 工作分配给并行线程。

3.3 CPU实现
为了说明这种方法的简便性,算法 2 中介绍了基于 CsrMV 的并行 OpenMP C++ 合并实现的全过程。第 3-6 行确定合并列表和合并路径长度(总长度和每线程长度)。进入并行部分后,第 16-21 行确定线程的起点和终点对角线,然后在合并网格内搜索相应的二维起点和终点坐标。在第 24-32 行中,每个线程沿着其在合并路径中的份额有效执行顺序 CsrMV 算法 1。第 35-36 行为与下一个线程共享的部分行累积任何非零。第 39-40 行保存线程的运行总数和行标识,以便后续修复。回到顺序阶段,第 44-46 行更新跨多个线程的行的 y 值。
为了强调工作负载平衡的重要性,作者的实现除了附加线程亲和性以防止内核间的迁移外,没有执行任何针对特定架构的优化,没有明确采用软件流水线、分支消除、SIMD、高级指针运算、预取等任何优化方法。

4 Evaluation
作者将CSRMV实现与MKL和cuSPARSE做了比较。为了突出基于合并的 CsrMV 方法的绝对竞争力,作者还将其与几种专门为容忍行长变化而设计的非 CSR 格式进行了比较:CSB [15]、HYB [7]、pOSKI [16] 和 yaSpMV [17]。表 2 进一步详细介绍了这些实现的特性。将预处理开销定义为一次性检查、编码或调整活动,其运行时间与任何后续 SpMV 计算分开计算。将其归一化为预处理时间与单次 SpMV 运行时间的比率。作者没有将基于合并的二进制搜索和修正算作预处理,而是算作 SpMV 运行时间的一部分。不过 NUMA 页面迁移作为预处理开销进行报告。
评估硬件由一个双插槽 NUMA CPU 平台组成,其中包括两个英特尔至强 E5-2690v2 CPU 和一个英伟达™(NVIDIA®)Tesla K40 GPU。每个 CPU 由 10 个内核组成,具有双向超线程(共 40 个线程)和 25MB 三级缓存(共 50MB)。它们共同实现了 77.9 GB/s 的 Stream Triad [34] 分数。K40 由 15 个 SM 组成,可同时执行 960 个warps,每个 32 个线程(共 30k 个线程),提供 1.5MB 的二级缓存。
图 9a 显示了每种实现将 SpMV 吞吐量与行长不规则解耦的程度。相对于 MKL 和 cuSPARSE CsrMV,基于合并的性能与行长不规则性的关系要小得多,甚至比专门的 GPU 格式还要好。

此外,图 9b 显示了每种实现符合 SpMV 运行时间与矩阵大小之间线性关系这一一般预期的程度。这一通用指标包含了 SpMV 计算中可能影响性能可预测性的所有方面,如缓存层次结构、非零局部性等。
基于合并的 CsrMV 在类似大小的矩阵中并非完全没有性能差异。这些不规则现象主要是由于高速缓存对密集向量 x 中不同访问模式的响应不同造成的。
图 10 显示了 SpMV 的相对速度。与 MKL CsrMV 相比,基于 CPU 合并的方法在高度不规则矩阵上的速度提高了 15.8 倍。 NUMA 感知变体能够更好地将这一优势扩展到无法在芯片上捕获的大型数据集,平均速度比 MKL 快 26%。此外, CsrMV 能够近似 CSB 和 pOSKI 实现的一致性,同时在很大程度上提高了它们的性能。这对于小型问题来说尤其如此,因为片外内存访问的延迟无法掩盖这些专用格式所增加的复杂性。

还有一些分析部分,这里略过了。
5 Conclusion
随着现代处理器不断扩展并行性,工作负载不平衡很快就会成为 CSR SpMV 等分段计算的高阶性能限制因素。更糟糕的是,与数据相关的性能下降往往会给需要可预测性能响应的应用带来巨大挑战。在这项工作中,作者调整了基于合并的并行分解,直接在 CSR 矩阵上计算平衡良好的 SpMV,而无需离线分析、格式转换或构建边带数据。这种分解方法尤其适用于跨多尺度处理器和具有固定大小本地存储器的系统的约束工作负载。这项研究表明,当代的 CsrMV 方法性能不稳定,而作者提出的方法的性能响应却不受行长不规则性的影响。